
Upload folder using huggingface_hub
Browse files- README.md +25 -6
- all_results.json +10 -10
- eval_results.json +5 -5
- model-00001-of-00004.safetensors +1 -1
- model-00002-of-00004.safetensors +1 -1
- model-00003-of-00004.safetensors +1 -1
- model-00004-of-00004.safetensors +1 -1
- tokenizer_config.json +1 -1
- train_results.json +6 -6
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +2 -2
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -16,9 +16,9 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 16 |
|
| 17 |
# prm_version3_full_hf
|
| 18 |
|
| 19 |
-
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) on the
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
|
| 23 |
## Model description
|
| 24 |
|
|
@@ -53,10 +53,29 @@ The following hyperparameters were used during training:
|
|
| 53 |
|
| 54 |
### Training results
|
| 55 |
|
| 56 |
-
| Training Loss | Epoch | Step
|
| 57 |
-
|:-------------:|:------:|:----:|:---------------:|
|
| 58 |
-
| 0.
|
| 59 |
-
| 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 60 |
|
| 61 |
|
| 62 |
### Framework versions
|
|
|
|
| 16 |
|
| 17 |
# prm_version3_full_hf
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) on the prm_conversations_prm_version3_math+webinstructsub-mcq+webinstructsub-oe+apps+gsm_mix_ref_hf dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.1166
|
| 22 |
|
| 23 |
## Model description
|
| 24 |
|
|
|
|
| 53 |
|
| 54 |
### Training results
|
| 55 |
|
| 56 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 57 |
+
|:-------------:|:------:|:-----:|:---------------:|
|
| 58 |
+
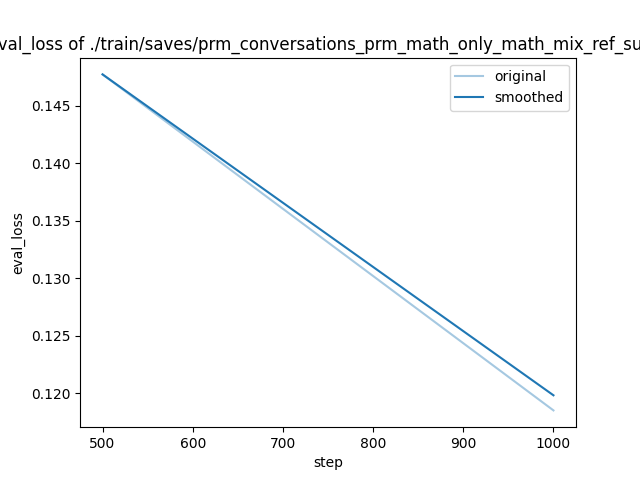
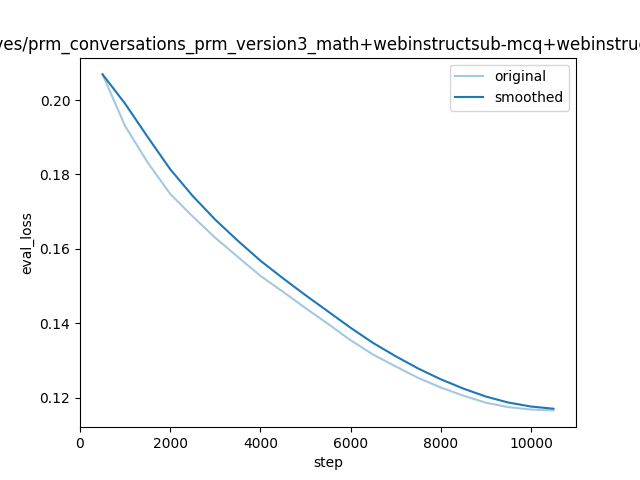
| 0.1961 | 0.0461 | 500 | 0.2069 |
|
| 59 |
+
| 0.192 | 0.0921 | 1000 | 0.1930 |
|
| 60 |
+
| 0.1963 | 0.1382 | 1500 | 0.1833 |
|
| 61 |
+
| 0.1701 | 0.1843 | 2000 | 0.1748 |
|
| 62 |
+
| 0.1647 | 0.2303 | 2500 | 0.1687 |
|
| 63 |
+
| 0.1507 | 0.2764 | 3000 | 0.1630 |
|
| 64 |
+
| 0.1421 | 0.3225 | 3500 | 0.1579 |
|
| 65 |
+
| 0.1403 | 0.3685 | 4000 | 0.1528 |
|
| 66 |
+
| 0.1557 | 0.4146 | 4500 | 0.1485 |
|
| 67 |
+
| 0.1536 | 0.4607 | 5000 | 0.1441 |
|
| 68 |
+
| 0.1344 | 0.5067 | 5500 | 0.1399 |
|
| 69 |
+
| 0.1195 | 0.5528 | 6000 | 0.1355 |
|
| 70 |
+
| 0.1209 | 0.5989 | 6500 | 0.1316 |
|
| 71 |
+
| 0.137 | 0.6450 | 7000 | 0.1284 |
|
| 72 |
+
| 0.117 | 0.6910 | 7500 | 0.1253 |
|
| 73 |
+
| 0.116 | 0.7371 | 8000 | 0.1228 |
|
| 74 |
+
| 0.1259 | 0.7832 | 8500 | 0.1206 |
|
| 75 |
+
| 0.1147 | 0.8292 | 9000 | 0.1187 |
|
| 76 |
+
| 0.1175 | 0.8753 | 9500 | 0.1175 |
|
| 77 |
+
| 0.1117 | 0.9214 | 10000 | 0.1168 |
|
| 78 |
+
| 0.1133 | 0.9674 | 10500 | 0.1166 |
|
| 79 |
|
| 80 |
|
| 81 |
### Framework versions
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 0.
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second":
|
| 7 |
-
"total_flos":
|
| 8 |
-
"train_loss": 0.
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second":
|
| 11 |
-
"train_steps_per_second": 0.
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 0.999953931911365,
|
| 3 |
+
"eval_loss": 0.11656492948532104,
|
| 4 |
+
"eval_runtime": 300.7975,
|
| 5 |
+
"eval_samples_per_second": 23.328,
|
| 6 |
+
"eval_steps_per_second": 2.919,
|
| 7 |
+
"total_flos": 1908258935930880.0,
|
| 8 |
+
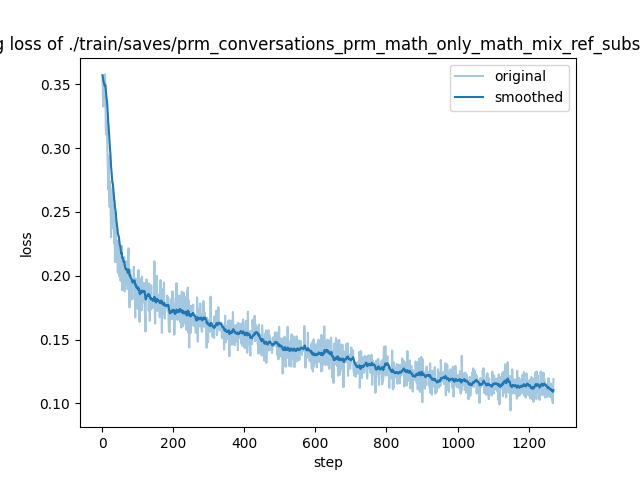
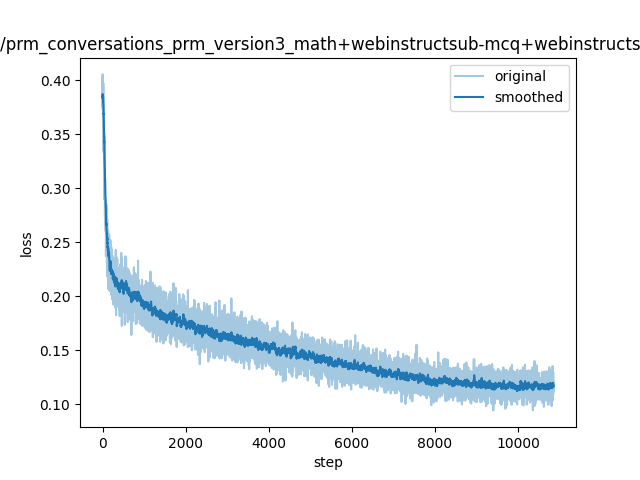
"train_loss": 0.14796658507510943,
|
| 9 |
+
"train_runtime": 123515.0295,
|
| 10 |
+
"train_samples_per_second": 5.624,
|
| 11 |
+
"train_steps_per_second": 0.088
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 0.
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second":
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 0.999953931911365,
|
| 3 |
+
"eval_loss": 0.11656492948532104,
|
| 4 |
+
"eval_runtime": 300.7975,
|
| 5 |
+
"eval_samples_per_second": 23.328,
|
| 6 |
+
"eval_steps_per_second": 2.919
|
| 7 |
}
|
model-00001-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4976698672
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a2bb9daf92dada040ef2bbe046ca2d8fb6c4201691a3f20abf0379ad9306e50c
|
| 3 |
size 4976698672
|
model-00002-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4999802720
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eab5f3a0f0c173e1fee4b3bc448db44340063749f6031805d8adf8ce787a26d3
|
| 3 |
size 4999802720
|
model-00003-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4915916176
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2a9a53be12e0636501dd42b75959bde440574b87ec96c671562c538a75a45b8a
|
| 3 |
size 4915916176
|
model-00004-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1168138808
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:92e099beabae4762f37d828d71ec227b0d59842da4ab925b5e006e8ff3fb1525
|
| 3 |
size 1168138808
|
tokenizer_config.json
CHANGED
|
@@ -2050,7 +2050,7 @@
|
|
| 2050 |
}
|
| 2051 |
},
|
| 2052 |
"bos_token": "<|begin_of_text|>",
|
| 2053 |
-
"chat_template": "{{
|
| 2054 |
"clean_up_tokenization_spaces": true,
|
| 2055 |
"eos_token": "<|eot_id|>",
|
| 2056 |
"model_input_names": [
|
|
|
|
| 2050 |
}
|
| 2051 |
},
|
| 2052 |
"bos_token": "<|begin_of_text|>",
|
| 2053 |
+
"chat_template": "{{ '<|begin_of_text|>' }}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|start_header_id|>system<|end_header_id|>\n\n' + system_message + '<|eot_id|>' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|start_header_id|>user<|end_header_id|>\n\n' + content + '<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|eot_id|>' }}{% endif %}{% endfor %}",
|
| 2054 |
"clean_up_tokenization_spaces": true,
|
| 2055 |
"eos_token": "<|eot_id|>",
|
| 2056 |
"model_input_names": [
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 0.
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 0.999953931911365,
|
| 3 |
+
"total_flos": 1908258935930880.0,
|
| 4 |
+
"train_loss": 0.14796658507510943,
|
| 5 |
+
"train_runtime": 123515.0295,
|
| 6 |
+
"train_samples_per_second": 5.624,
|
| 7 |
+
"train_steps_per_second": 0.088
|
| 8 |
}
|
trainer_log.jsonl
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc60866c2d54851b007afde9f8aaac54f1485ccd1bb5f771c8dd877aa1427ab9
|
| 3 |
+
size 7480
|
training_eval_loss.png
CHANGED
|
|
training_loss.png
CHANGED
|
|