
Upload folder using huggingface_hub
Browse files- .DS_Store +0 -0
- .gitattributes +3 -0
- README.md +182 -0
- agent.py +335 -0
- checkpoints/checkpoint.pth +3 -0
- checkpoints/final_model.pth +3 -0
- output/flappy_bird_evaluation.gif +3 -0
- output/flappy_bird_evaluation.mp4 +3 -0
- output/flappy_bird_training.mp4 +3 -0
- output/loss_vs_episodes.png +0 -0
- output/rewards_vs_episodes.png +0 -0
- policy.py +31 -0
- requirements.txt +9 -0
.DS_Store
ADDED
|
Binary file (8.2 kB). View file
|
|
|
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
output/flappy_bird_evaluation.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
output/flappy_bird_evaluation.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
output/flappy_bird_training.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Flappy Bird Reinforcement Learning Agent
|
| 2 |
+
|
| 3 |
+
This project implements a reinforcement learning agent for the Flappy Bird game using the REINFORCE (Policy Gradient) algorithm. The agent learns to play Flappy Bird by maximizing the cumulative reward through trial and error.
|
| 4 |
+
|
| 5 |
+
## Features
|
| 6 |
+
|
| 7 |
+
- Policy Gradient (REINFORCE) algorithm implementation
|
| 8 |
+
- Neural network policy with multiple hidden layers
|
| 9 |
+
- Checkpoint saving and resuming for training
|
| 10 |
+
- Evaluation with statistical analysis
|
| 11 |
+
- Video recording of gameplay
|
| 12 |
+
- Dynamic plotting of training progress
|
| 13 |
+
|
| 14 |
+
## Dependencies
|
| 15 |
+
|
| 16 |
+
- Python 3.13
|
| 17 |
+
- PyTorch
|
| 18 |
+
- NumPy
|
| 19 |
+
- Matplotlib
|
| 20 |
+
- Gymnasium
|
| 21 |
+
- Flappy Bird Gymnasium
|
| 22 |
+
- ImageIO
|
| 23 |
+
- tqdm
|
| 24 |
+
- PIL (Pillow)
|
| 25 |
+
- Hugging Face Hub (for model uploading)
|
| 26 |
+
|
| 27 |
+
## Installation
|
| 28 |
+
|
| 29 |
+
1. Create a virtual environment:
|
| 30 |
+
```bash
|
| 31 |
+
python -m venv env
|
| 32 |
+
source env/bin/activate # On Windows: env\Scripts\activate
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
2. Install dependencies:
|
| 36 |
+
```bash
|
| 37 |
+
pip install -r requirements.txt
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
Or manually:
|
| 41 |
+
```bash
|
| 42 |
+
pip install torch numpy matplotlib gymnasium flappy-bird-gymnasium imageio tqdm pillow huggingface-hub
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
## Usage
|
| 46 |
+
|
| 47 |
+
### Training
|
| 48 |
+
|
| 49 |
+
Run the training script with default settings (trains and evaluates):
|
| 50 |
+
```bash
|
| 51 |
+
python agent.py
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
The agent will train for 100,000 episodes by default. Checkpoints are saved every 100 episodes to `checkpoints/checkpoint.pth`, and the final model is saved to `checkpoints/final_model.pth`.
|
| 55 |
+
|
| 56 |
+
### Configuration
|
| 57 |
+
|
| 58 |
+
Modify the `hyperparams` dictionary in `agent.py` to adjust:
|
| 59 |
+
|
| 60 |
+
- `no_of_episodes`: Number of training episodes
|
| 61 |
+
- `gamma`: Discount factor
|
| 62 |
+
- `lr`: Learning rate
|
| 63 |
+
- `fps`: Frames per second for video output
|
| 64 |
+
- `save_videos`: Whether to save training/evaluation videos
|
| 65 |
+
- `train`: Whether to run training (default: True)
|
| 66 |
+
- `evaluate`: Whether to run evaluation (default: True)
|
| 67 |
+
- `push_hf`: Whether to push model to Hugging Face Hub (default: False)
|
| 68 |
+
- `hf_repo`: Hugging Face repository name (required if push_hf is True)
|
| 69 |
+
- `eval_episodes`: Number of evaluation episodes (default: 5)
|
| 70 |
+
|
| 71 |
+
### Examples
|
| 72 |
+
|
| 73 |
+
Train only (modify hyperparams):
|
| 74 |
+
```python
|
| 75 |
+
hyperparams["evaluate"] = False
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
Evaluate only (modify hyperparams):
|
| 79 |
+
```python
|
| 80 |
+
hyperparams["train"] = False
|
| 81 |
+
hyperparams["eval_episodes"] = 10
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
Train and push to HF (modify hyperparams):
|
| 85 |
+
```python
|
| 86 |
+
hyperparams["push_hf"] = True
|
| 87 |
+
hyperparams["hf_repo"] = "your-username/flappy-bird-rl-agent"
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
### Resuming Training
|
| 91 |
+
|
| 92 |
+
If checkpoints exist, the training will automatically resume from the last saved checkpoint.
|
| 93 |
+
|
| 94 |
+
### Evaluation
|
| 95 |
+
|
| 96 |
+
The script automatically evaluates the trained model after training. To evaluate a saved model separately, modify the `evaluate_policy` call in `agent.py`.
|
| 97 |
+
|
| 98 |
+
### Uploading to Hugging Face
|
| 99 |
+
|
| 100 |
+
To upload your trained model and project to Hugging Face Hub:
|
| 101 |
+
|
| 102 |
+
1. **Get your Hugging Face token**:
|
| 103 |
+
- Go to [Hugging Face Settings](https://huggingface.co/settings/tokens)
|
| 104 |
+
- Create a new token with "Write" permissions
|
| 105 |
+
- Copy the token
|
| 106 |
+
|
| 107 |
+
2. **Set the token as an environment variable**:
|
| 108 |
+
```bash
|
| 109 |
+
export HF_TOKEN=your_token_here
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
3. **Modify hyperparams in `agent.py`**:
|
| 113 |
+
```python
|
| 114 |
+
hyperparams["push_hf"] = True
|
| 115 |
+
hyperparams["hf_repo"] = "your-username/flappy-bird-rl-agent"
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
The entire project (excluding unnecessary files) will be uploaded to your repository.
|
| 119 |
+
|
| 120 |
+
## Configuration
|
| 121 |
+
|
| 122 |
+
Modify the `hyperparams` dictionary in `agent.py` to adjust:
|
| 123 |
+
|
| 124 |
+
- `no_of_episodes`: Number of training episodes
|
| 125 |
+
- `gamma`: Discount factor
|
| 126 |
+
- `lr`: Learning rate
|
| 127 |
+
- `fps`: Frames per second for video output
|
| 128 |
+
- `save_videos`: Whether to save training/evaluation videos
|
| 129 |
+
|
| 130 |
+
## Output
|
| 131 |
+
|
| 132 |
+
- Training plots: `output/rewards_vs_episodes.png`, `output/loss_vs_episodes.png`
|
| 133 |
+
- Training video: `output/flappy_bird_training.mp4` (if `save_videos=True`)
|
| 134 |
+
- Evaluation video: `output/flappy_bird_evaluation.mp4`
|
| 135 |
+
- Checkpoints: `checkpoints/`
|
| 136 |
+
|
| 137 |
+
## Results
|
| 138 |
+
|
| 139 |
+
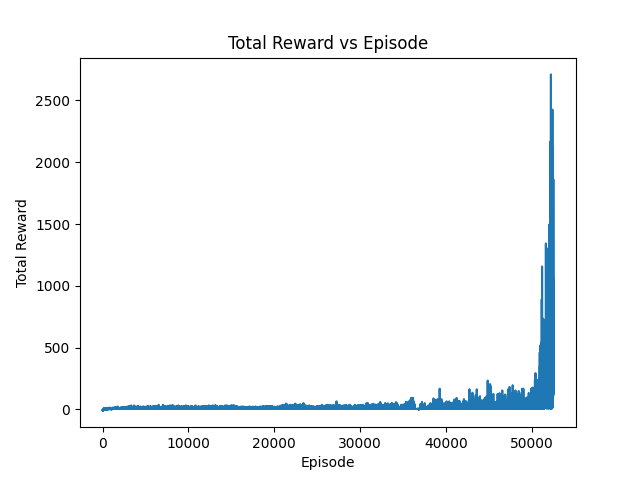
### Training Progress
|
| 140 |
+
|
| 141 |
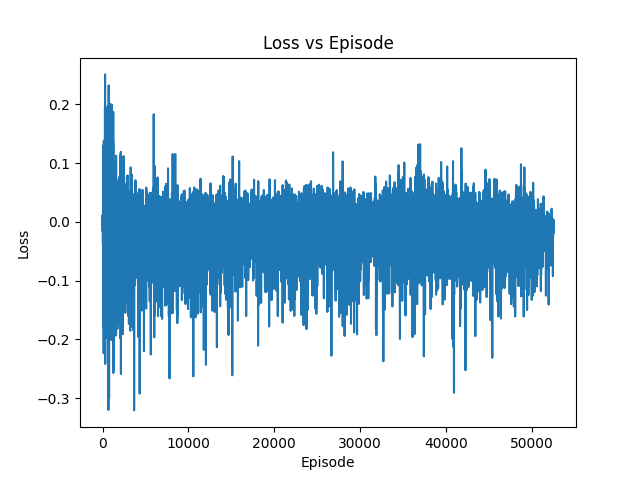
+

|
| 142 |
+
*Figure 1: Total reward per episode during training*
|
| 143 |
+
|
| 144 |
+

|
| 145 |
+
*Figure 2: Loss per episode during training*
|
| 146 |
+
|
| 147 |
+
### Evaluation
|
| 148 |
+
|
| 149 |
+
The evaluation video shows the trained agent playing Flappy Bird. To create a 3-second GIF from the last 3 seconds of the video:
|
| 150 |
+
|
| 151 |
+
```bash
|
| 152 |
+
ffmpeg -sseof -3 -i output/flappy_bird_evaluation.mp4 -t 3 -vf "fps=10,scale=320:-1:flags=lanczos" output/flappy_bird_evaluation.gif
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+

|
| 156 |
+
*Figure 3: GIF of the evaluation gameplay*
|
| 157 |
+
|
| 158 |
+
### Final Evaluation Statistics
|
| 159 |
+
|
| 160 |
+
Episode 1: Total Reward: 597.100000000053
|
| 161 |
+
Episode 2: Total Reward: 2084.89999999937
|
| 162 |
+
Episode 3: Total Reward: 428.4000000000229
|
| 163 |
+
Episode 4: Total Reward: 22.700000000000063
|
| 164 |
+
Episode 5: Total Reward: 152.89999999999645
|
| 165 |
+
|
| 166 |
+
Evaluation Statistics:
|
| 167 |
+
Mean Reward: 657.20
|
| 168 |
+
Standard Deviation: 741.78
|
| 169 |
+
Max Reward: 2084.90
|
| 170 |
+
Mean Score: 446.00
|
| 171 |
+
Max Score: 446.00
|
| 172 |
+
|
| 173 |
+
## Architecture
|
| 174 |
+
|
| 175 |
+
The policy network consists of:
|
| 176 |
+
- Input layer: Matches observation space dimension
|
| 177 |
+
- Hidden layers: 256, 128, 64 neurons with ReLU activation
|
| 178 |
+
- Output layer: Softmax over action space
|
| 179 |
+
|
| 180 |
+
## Algorithm
|
| 181 |
+
|
| 182 |
+
REINFORCE uses Monte Carlo policy gradients to update the policy parameters by maximizing the expected cumulative reward. The agent samples actions from the current policy, collects trajectories, and updates the policy using the discounted returns.
|
agent.py
ADDED
|
@@ -0,0 +1,335 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import flappy_bird_gymnasium
|
| 2 |
+
import gymnasium
|
| 3 |
+
from policy import PolicyNetwork
|
| 4 |
+
import torch
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import numpy as np
|
| 7 |
+
import imageio
|
| 8 |
+
import tqdm
|
| 9 |
+
import os
|
| 10 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 11 |
+
import matplotlib
|
| 12 |
+
matplotlib.use('TkAgg') # Use interactive backend
|
| 13 |
+
plt.ion() # Turn on interactive mode
|
| 14 |
+
from huggingface_hub import HfApi, upload_file, login, upload_folder
|
| 15 |
+
|
| 16 |
+
hyperparams = {
|
| 17 |
+
"no_of_episodes": 52300,
|
| 18 |
+
"gamma": 0.99,
|
| 19 |
+
"lr": 3e-4, # Lower learning rate for stability
|
| 20 |
+
"fps": 30,
|
| 21 |
+
"out_directory": "output/flappy_bird_evaluation.mp4",
|
| 22 |
+
"save_videos": True,
|
| 23 |
+
"train": False,
|
| 24 |
+
"evaluate": False,
|
| 25 |
+
"push_hf": True,
|
| 26 |
+
"hf_repo": "Heshwa/flappy-bird-reinforce-v1",
|
| 27 |
+
"eval_episodes": 3
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
def discounted_returns(rewards, gamma):
|
| 31 |
+
G = []
|
| 32 |
+
Gt = 0.0
|
| 33 |
+
for r in reversed(rewards):
|
| 34 |
+
Gt = r + gamma * Gt
|
| 35 |
+
G.insert(0, Gt)
|
| 36 |
+
|
| 37 |
+
eps = np.finfo(np.float32).eps.item()
|
| 38 |
+
G = torch.tensor(G, dtype=torch.float32)
|
| 39 |
+
G = (G - G.mean()) / (G.std() + eps)
|
| 40 |
+
return G
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def annotate_frame(frame, episode, score):
|
| 44 |
+
"""Draw episode number and score onto an RGB ndarray frame and return ndarray."""
|
| 45 |
+
try:
|
| 46 |
+
img = Image.fromarray(frame)
|
| 47 |
+
except Exception:
|
| 48 |
+
# If frame is already a PIL Image
|
| 49 |
+
img = frame
|
| 50 |
+
draw = ImageDraw.Draw(img)
|
| 51 |
+
font = ImageFont.load_default()
|
| 52 |
+
text = f"Ep:{episode} Score:{score}"
|
| 53 |
+
x, y = 8, 8
|
| 54 |
+
# draw black outline for readability
|
| 55 |
+
draw.text((x - 1, y - 1), text, font=font, fill=(0, 0, 0))
|
| 56 |
+
draw.text((x + 1, y - 1), text, font=font, fill=(0, 0, 0))
|
| 57 |
+
draw.text((x - 1, y + 1), text, font=font, fill=(0, 0, 0))
|
| 58 |
+
draw.text((x + 1, y + 1), text, font=font, fill=(0, 0, 0))
|
| 59 |
+
# draw main text
|
| 60 |
+
draw.text((x, y), text, font=font, fill=(255, 255, 255))
|
| 61 |
+
return np.array(img)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
env = gymnasium.make("FlappyBird-v0",render_mode="rgb_array",use_lidar=False)
|
| 69 |
+
policy_net = PolicyNetwork(input_dim=env.observation_space.shape[0], output_dim=env.action_space.n)
|
| 70 |
+
optimizer = torch.optim.Adam(policy_net.parameters(), lr=hyperparams["lr"])
|
| 71 |
+
|
| 72 |
+
ensure_dir = lambda p: os.makedirs(p, exist_ok=True)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def load_checkpoint(policy_net, optimizer, checkpoint_path):
|
| 76 |
+
if os.path.exists(checkpoint_path):
|
| 77 |
+
checkpoint = torch.load(checkpoint_path)
|
| 78 |
+
policy_net.load_state_dict(checkpoint['model_state_dict'])
|
| 79 |
+
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
|
| 80 |
+
start_episode = checkpoint['episode']
|
| 81 |
+
rewards = checkpoint.get('rewards', [])
|
| 82 |
+
losses = checkpoint.get('losses', [])
|
| 83 |
+
print(f"Resumed from episode {start_episode}")
|
| 84 |
+
return start_episode, rewards, losses
|
| 85 |
+
else:
|
| 86 |
+
print("No checkpoint found, starting from scratch")
|
| 87 |
+
return 0, [], []
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def get_latest_checkpoint(checkpoint_dir):
|
| 91 |
+
checkpoint_path = os.path.join(checkpoint_dir, "checkpoint.pth")
|
| 92 |
+
if os.path.exists(checkpoint_path):
|
| 93 |
+
return checkpoint_path
|
| 94 |
+
final_path = os.path.join(checkpoint_dir, "final_model.pth")
|
| 95 |
+
if os.path.exists(final_path):
|
| 96 |
+
return final_path
|
| 97 |
+
return None
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def reinforce(policy_net, optimizer, env, hyperparams, start_episode=0, rewards=[], losses=[]):
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
# Initialize dynamic plots
|
| 105 |
+
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
|
| 106 |
+
ax1.set_xlabel("Episode")
|
| 107 |
+
ax1.set_ylabel("Total Reward")
|
| 108 |
+
ax1.set_title("Total Reward vs Episode")
|
| 109 |
+
line1, = ax1.plot([], [], 'b-')
|
| 110 |
+
|
| 111 |
+
ax2.set_xlabel("Episode")
|
| 112 |
+
ax2.set_ylabel("Loss")
|
| 113 |
+
ax2.set_title("Loss vs Episode")
|
| 114 |
+
line2, = ax2.plot([], [], 'r-')
|
| 115 |
+
|
| 116 |
+
plt.tight_layout()
|
| 117 |
+
|
| 118 |
+
checkpoint_dir = "checkpoints"
|
| 119 |
+
ensure_dir(checkpoint_dir)
|
| 120 |
+
|
| 121 |
+
for i in tqdm.tqdm(range(start_episode, hyperparams["no_of_episodes"])):
|
| 122 |
+
returns = []
|
| 123 |
+
log_probs = []
|
| 124 |
+
obs, _ = env.reset()
|
| 125 |
+
terminated = False
|
| 126 |
+
truncated = False
|
| 127 |
+
while not (terminated or truncated):
|
| 128 |
+
# action = env.action_space.sample()
|
| 129 |
+
action, log_prob = policy_net.act(obs)
|
| 130 |
+
obs, reward, terminated, truncated, info = env.step(action)
|
| 131 |
+
returns.append(reward)
|
| 132 |
+
log_probs.append(log_prob)
|
| 133 |
+
# print(f"Action: {action}, Reward: {reward}, Terminated: {terminated}")
|
| 134 |
+
|
| 135 |
+
loss = 0.0
|
| 136 |
+
# print("Episode:", i+1)
|
| 137 |
+
for log_prob, Gt in zip(log_probs, discounted_returns(returns, hyperparams["gamma"])):
|
| 138 |
+
loss += -log_prob * Gt
|
| 139 |
+
loss = loss/len(returns)
|
| 140 |
+
# print("Loss:", loss)
|
| 141 |
+
# print("total reward:", sum(returns))
|
| 142 |
+
optimizer.zero_grad()
|
| 143 |
+
loss.backward()
|
| 144 |
+
torch.nn.utils.clip_grad_norm_(policy_net.parameters(), max_norm=1.0) # Add gradient clipping
|
| 145 |
+
optimizer.step()
|
| 146 |
+
losses.append(loss.item())
|
| 147 |
+
rewards.append(sum(returns))
|
| 148 |
+
|
| 149 |
+
# Save checkpoint every 100 episodes
|
| 150 |
+
if (i + 1) % 100 == 0:
|
| 151 |
+
checkpoint_path = os.path.join(checkpoint_dir, "checkpoint.pth")
|
| 152 |
+
torch.save({
|
| 153 |
+
'model_state_dict': policy_net.state_dict(),
|
| 154 |
+
'optimizer_state_dict': optimizer.state_dict(),
|
| 155 |
+
'episode': i + 1,
|
| 156 |
+
'rewards': rewards,
|
| 157 |
+
'losses': losses
|
| 158 |
+
}, checkpoint_path)
|
| 159 |
+
print(f"Checkpoint saved at episode {i+1} to {checkpoint_path}")
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
# Update plots every 100 episodes
|
| 164 |
+
if (i + 1) % 100 == 0:
|
| 165 |
+
line1.set_xdata(range(1, len(rewards) + 1))
|
| 166 |
+
line1.set_ydata(rewards)
|
| 167 |
+
ax1.relim()
|
| 168 |
+
ax1.autoscale_view()
|
| 169 |
+
|
| 170 |
+
line2.set_xdata(range(1, len(losses) + 1))
|
| 171 |
+
line2.set_ydata(losses)
|
| 172 |
+
ax2.relim()
|
| 173 |
+
ax2.autoscale_view()
|
| 174 |
+
|
| 175 |
+
plt.draw()
|
| 176 |
+
plt.pause(0.01) # Small pause to update the plot
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
ensure_dir("output")
|
| 180 |
+
plt.close(fig) # Close the dynamic plot
|
| 181 |
+
plt.close('all') # Close all plots
|
| 182 |
+
plt.figure()
|
| 183 |
+
plt.plot(rewards)
|
| 184 |
+
plt.xlabel("Episode")
|
| 185 |
+
plt.ylabel("Total Reward")
|
| 186 |
+
plt.title("Total Reward vs Episode")
|
| 187 |
+
plt.savefig("output/rewards_vs_episodes.png")
|
| 188 |
+
plt.close()
|
| 189 |
+
plt.figure()
|
| 190 |
+
plt.plot(losses)
|
| 191 |
+
plt.xlabel("Episode")
|
| 192 |
+
plt.ylabel("Loss")
|
| 193 |
+
plt.title("Loss vs Episode")
|
| 194 |
+
plt.savefig("output/loss_vs_episodes.png")
|
| 195 |
+
plt.close()
|
| 196 |
+
|
| 197 |
+
return rewards, losses
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def evaluate_policy(policy_net, env, episodes=5,save_videos=False, checkpoint_path=None,out_directory="output/flappy_bird_evaluation.mp4"):
|
| 202 |
+
if checkpoint_path is None:
|
| 203 |
+
checkpoint_path = get_latest_checkpoint("checkpoints") or "checkpoints/final_model.pth"
|
| 204 |
+
|
| 205 |
+
if checkpoint_path and os.path.exists(checkpoint_path):
|
| 206 |
+
checkpoint = torch.load(checkpoint_path)
|
| 207 |
+
policy_net.load_state_dict(checkpoint['model_state_dict'])
|
| 208 |
+
print(f"Loaded model from {checkpoint_path}")
|
| 209 |
+
else:
|
| 210 |
+
print("No checkpoint found, using current model")
|
| 211 |
+
|
| 212 |
+
if save_videos:
|
| 213 |
+
images = []
|
| 214 |
+
|
| 215 |
+
episode_rewards = []
|
| 216 |
+
episode_scores = []
|
| 217 |
+
for i in range(episodes):
|
| 218 |
+
obs, _ = env.reset()
|
| 219 |
+
if save_videos:
|
| 220 |
+
frame = env.render()
|
| 221 |
+
if frame is not None:
|
| 222 |
+
images.append(annotate_frame(frame, i + 1, 0))
|
| 223 |
+
terminated = False
|
| 224 |
+
truncated = False
|
| 225 |
+
total_reward = 0
|
| 226 |
+
while not (terminated or truncated):
|
| 227 |
+
action, _ = policy_net.act(obs)
|
| 228 |
+
obs, reward, terminated, truncated, info = env.step(action)
|
| 229 |
+
if save_videos:
|
| 230 |
+
frame = env.render()
|
| 231 |
+
if frame is not None:
|
| 232 |
+
images.append(annotate_frame(frame, i + 1, int(info.get("score"))))
|
| 233 |
+
total_reward += reward
|
| 234 |
+
env.render()
|
| 235 |
+
episode_rewards.append(total_reward)
|
| 236 |
+
episode_scores.append(info.get("score"))
|
| 237 |
+
print(f"Episode {i+1}: Total Reward: {total_reward}")
|
| 238 |
+
|
| 239 |
+
# Compute statistics
|
| 240 |
+
mean_reward = np.mean(episode_rewards)
|
| 241 |
+
std_reward = np.std(episode_rewards)
|
| 242 |
+
max_reward = np.max(episode_rewards)
|
| 243 |
+
mean_score = np.max(episode_scores)
|
| 244 |
+
max_score = np.max(episode_scores)
|
| 245 |
+
print(f"\nEvaluation Statistics:")
|
| 246 |
+
print(f"Mean Reward: {mean_reward:.2f}")
|
| 247 |
+
print(f"Standard Deviation: {std_reward:.2f}")
|
| 248 |
+
print(f"Max Reward: {max_reward:.2f}")
|
| 249 |
+
print(f"Mean Score: {mean_score:.2f}")
|
| 250 |
+
print(f"Max Score: {max_score:.2f}")
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
if save_videos:
|
| 254 |
+
ensure_dir("output")
|
| 255 |
+
imageio.mimwrite(out_directory, images, fps=hyperparams["fps"])
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
def push_to_hf(repo_name, token=None):
|
| 260 |
+
"""
|
| 261 |
+
Push the project to Hugging Face Hub.
|
| 262 |
+
|
| 263 |
+
Args:
|
| 264 |
+
repo_name (str): Name of the HF repository (e.g., 'username/model-name')
|
| 265 |
+
token (str, optional): HF token. If None, uses environment variable HF_TOKEN
|
| 266 |
+
"""
|
| 267 |
+
if token:
|
| 268 |
+
login(token)
|
| 269 |
+
else:
|
| 270 |
+
login()
|
| 271 |
+
|
| 272 |
+
# Upload the project folder, excluding unnecessary files
|
| 273 |
+
ignore_patterns = [
|
| 274 |
+
"env/",
|
| 275 |
+
"__pycache__/",
|
| 276 |
+
"*.pyc",
|
| 277 |
+
".git/",
|
| 278 |
+
"*.log",
|
| 279 |
+
"text.ipynb",
|
| 280 |
+
# "*.mp4", # Optional: exclude videos if too large
|
| 281 |
+
# "*.gif" # Optional: exclude GIFs
|
| 282 |
+
]
|
| 283 |
+
|
| 284 |
+
try:
|
| 285 |
+
upload_folder(
|
| 286 |
+
folder_path=".",
|
| 287 |
+
repo_id=repo_name,
|
| 288 |
+
repo_type="model",
|
| 289 |
+
ignore_patterns=ignore_patterns
|
| 290 |
+
)
|
| 291 |
+
print(f"Project uploaded to https://huggingface.co/{repo_name}")
|
| 292 |
+
except Exception as e:
|
| 293 |
+
print(f"Upload failed: {e}")
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
if __name__ == "__main__":
|
| 298 |
+
env = gymnasium.make("FlappyBird-v0",render_mode="rgb_array",use_lidar=False)
|
| 299 |
+
policy_net = PolicyNetwork(input_dim=env.observation_space.shape[0], output_dim=env.action_space.n)
|
| 300 |
+
optimizer = torch.optim.Adam(policy_net.parameters(), lr=hyperparams["lr"])
|
| 301 |
+
|
| 302 |
+
ensure_dir = lambda p: os.makedirs(p, exist_ok=True)
|
| 303 |
+
|
| 304 |
+
# Load checkpoint if exists (prefer checkpoint.pth for resuming, else final_model.pth)
|
| 305 |
+
checkpoint_path = get_latest_checkpoint("checkpoints")
|
| 306 |
+
if checkpoint_path:
|
| 307 |
+
start_episode, rewards, losses = load_checkpoint(policy_net, optimizer, checkpoint_path)
|
| 308 |
+
else:
|
| 309 |
+
start_episode, rewards, losses = 0, [], []
|
| 310 |
+
|
| 311 |
+
if hyperparams["train"]:
|
| 312 |
+
rewards, losses = reinforce(policy_net, optimizer, env, hyperparams,start_episode=start_episode, rewards=rewards, losses=losses)
|
| 313 |
+
|
| 314 |
+
# Save final model
|
| 315 |
+
final_checkpoint_path = "checkpoints/final_model.pth"
|
| 316 |
+
ensure_dir("checkpoints")
|
| 317 |
+
torch.save({
|
| 318 |
+
'model_state_dict': policy_net.state_dict(),
|
| 319 |
+
'optimizer_state_dict': optimizer.state_dict(),
|
| 320 |
+
'episode': hyperparams["no_of_episodes"],
|
| 321 |
+
'rewards': rewards,
|
| 322 |
+
'losses': losses
|
| 323 |
+
}, final_checkpoint_path)
|
| 324 |
+
print(f"Final model saved to {final_checkpoint_path}")
|
| 325 |
+
|
| 326 |
+
if hyperparams["evaluate"]:
|
| 327 |
+
evaluate_policy(policy_net, env, episodes=hyperparams["eval_episodes"], save_videos=hyperparams["save_videos"], checkpoint_path=None, out_directory=hyperparams["out_directory"])
|
| 328 |
+
|
| 329 |
+
if hyperparams["push_hf"]:
|
| 330 |
+
if hyperparams["hf_repo"] is None:
|
| 331 |
+
print("Error: hf_repo is required when push_hf is True")
|
| 332 |
+
else:
|
| 333 |
+
push_to_hf(hyperparams["hf_repo"])
|
| 334 |
+
|
| 335 |
+
env.close()
|
checkpoints/checkpoint.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:07e044c7c4e27d05f6b4d36714994120b51996a39703a964b95cef214f3ce238
|
| 3 |
+
size 1490549
|
checkpoints/final_model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ea3fa287930789d32a4dac03f8ef60f5d7000b9020daf05758a4400c7727515
|
| 3 |
+
size 1490587
|
output/flappy_bird_evaluation.gif
ADDED

|
Git LFS Details
|
output/flappy_bird_evaluation.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:859c760509b5059fcd5798b260bcff082ce107a37a8af1f9d58c002f5b38e063
|
| 3 |
+
size 15957601
|
output/flappy_bird_training.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69aa820437344b05e9e3d009b96a36c3859df65914e1c305d87ef91ec7f696a1
|
| 3 |
+
size 2672703
|
output/loss_vs_episodes.png
ADDED
|
output/rewards_vs_episodes.png
ADDED
|
policy.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import torch
|
| 3 |
+
from torch.distributions import Categorical
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PolicyNetwork(nn.Module):
|
| 8 |
+
def __init__(self, input_dim, output_dim):
|
| 9 |
+
super(PolicyNetwork, self).__init__()
|
| 10 |
+
self.fc1 = nn.Linear(input_dim, 256) # Increased from 128
|
| 11 |
+
self.fc2 = nn.Linear(256, 128) # Increased from 64
|
| 12 |
+
self.fc3 = nn.Linear(128, 64) # New layer
|
| 13 |
+
self.fc4 = nn.Linear(64, output_dim)
|
| 14 |
+
self.relu = nn.ReLU()
|
| 15 |
+
self.softmax = nn.Softmax(dim=-1)
|
| 16 |
+
|
| 17 |
+
def forward(self, x):
|
| 18 |
+
x = self.relu(self.fc1(x))
|
| 19 |
+
x = self.relu(self.fc2(x))
|
| 20 |
+
x = self.relu(self.fc3(x))
|
| 21 |
+
x = self.softmax(self.fc4(x))
|
| 22 |
+
return x
|
| 23 |
+
|
| 24 |
+
def act(self, state):
|
| 25 |
+
state = torch.from_numpy(state).float().unsqueeze(0)
|
| 26 |
+
probs = self.forward(state)
|
| 27 |
+
m = Categorical(probs)
|
| 28 |
+
# action = np.argmax(m)
|
| 29 |
+
action = m.sample()
|
| 30 |
+
return action.item(), m.log_prob(action)
|
| 31 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch>=2.0.0
|
| 2 |
+
numpy>=1.21.0
|
| 3 |
+
matplotlib>=3.5.0
|
| 4 |
+
gymnasium>=0.29.0
|
| 5 |
+
flappy-bird-gymnasium>=0.4.0
|
| 6 |
+
imageio>=2.31.0
|
| 7 |
+
tqdm>=4.64.0
|
| 8 |
+
Pillow>=9.0.0
|
| 9 |
+
huggingface-hub>=0.17.0
|