
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- README.md +79 -0
- adapter_config.json +34 -0
- adapter_model.safetensors +3 -0
- all_results.json +12 -0
- checkpoint-450/README.md +202 -0
- checkpoint-450/adapter_config.json +34 -0
- checkpoint-450/adapter_model.safetensors +3 -0
- checkpoint-450/optimizer.pt +3 -0
- checkpoint-450/rng_state_0.pth +3 -0
- checkpoint-450/rng_state_1.pth +3 -0
- checkpoint-450/rng_state_2.pth +3 -0
- checkpoint-450/rng_state_3.pth +3 -0
- checkpoint-450/scheduler.pt +3 -0
- checkpoint-450/special_tokens_map.json +24 -0
- checkpoint-450/tokenizer.json +3 -0
- checkpoint-450/tokenizer_config.json +0 -0
- checkpoint-450/trainer_state.json +468 -0
- checkpoint-450/training_args.bin +3 -0
- eval_results.json +7 -0
- runs/Jan16_00-20-03_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736986825.ctua-mistral-sft-heat-333c1-hg6rc.1409.0 +3 -0
- runs/Jan16_00-20-03_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736994900.ctua-mistral-sft-heat-333c1-hg6rc.1409.1 +3 -0
- special_tokens_map.json +24 -0
- tokenizer.json +3 -0
- tokenizer_config.json +0 -0
- train_results.json +8 -0
- trainer_log.jsonl +61 -0
- trainer_state.json +477 -0
- training_args.bin +3 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
checkpoint-450/tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: mistralai/Mistral-Nemo-Instruct-2407
|
| 3 |
+
library_name: peft
|
| 4 |
+
license: other
|
| 5 |
+
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- lora
|
| 8 |
+
- generated_from_trainer
|
| 9 |
+
model-index:
|
| 10 |
+
- name: heat_transfer_sft_10000_mcq_2epoch
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# heat_transfer_sft_10000_mcq_2epoch
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [mistralai/Mistral-Nemo-Instruct-2407](https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407) on the heat_transfer_10000_mcq dataset.
|
| 20 |
+
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.0006
|
| 22 |
+
|
| 23 |
+
## Model description
|
| 24 |
+
|
| 25 |
+
More information needed
|
| 26 |
+
|
| 27 |
+
## Intended uses & limitations
|
| 28 |
+
|
| 29 |
+
More information needed
|
| 30 |
+
|
| 31 |
+
## Training and evaluation data
|
| 32 |
+
|
| 33 |
+
More information needed
|
| 34 |
+
|
| 35 |
+
## Training procedure
|
| 36 |
+
|
| 37 |
+
### Training hyperparameters
|
| 38 |
+
|
| 39 |
+
The following hyperparameters were used during training:
|
| 40 |
+
- learning_rate: 0.0001
|
| 41 |
+
- train_batch_size: 10
|
| 42 |
+
- eval_batch_size: 10
|
| 43 |
+
- seed: 42
|
| 44 |
+
- distributed_type: multi-GPU
|
| 45 |
+
- num_devices: 4
|
| 46 |
+
- total_train_batch_size: 40
|
| 47 |
+
- total_eval_batch_size: 40
|
| 48 |
+
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 49 |
+
- lr_scheduler_type: cosine
|
| 50 |
+
- num_epochs: 2
|
| 51 |
+
|
| 52 |
+
### Training results
|
| 53 |
+
|
| 54 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 55 |
+
|:-------------:|:------:|:----:|:---------------:|
|
| 56 |
+
| 0.004 | 0.1333 | 30 | 0.0038 |
|
| 57 |
+
| 0.0036 | 0.2667 | 60 | 0.0036 |
|
| 58 |
+
| 0.0035 | 0.4 | 90 | 0.0033 |
|
| 59 |
+
| 0.0024 | 0.5333 | 120 | 0.0021 |
|
| 60 |
+
| 0.0011 | 0.6667 | 150 | 0.0011 |
|
| 61 |
+
| 0.0011 | 0.8 | 180 | 0.0009 |
|
| 62 |
+
| 0.001 | 0.9333 | 210 | 0.0008 |
|
| 63 |
+
| 0.0008 | 1.0667 | 240 | 0.0008 |
|
| 64 |
+
| 0.0009 | 1.2 | 270 | 0.0007 |
|
| 65 |
+
| 0.0006 | 1.3333 | 300 | 0.0007 |
|
| 66 |
+
| 0.0006 | 1.4667 | 330 | 0.0006 |
|
| 67 |
+
| 0.0004 | 1.6 | 360 | 0.0006 |
|
| 68 |
+
| 0.0007 | 1.7333 | 390 | 0.0006 |
|
| 69 |
+
| 0.0005 | 1.8667 | 420 | 0.0006 |
|
| 70 |
+
| 0.0005 | 2.0 | 450 | 0.0006 |
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
### Framework versions
|
| 74 |
+
|
| 75 |
+
- PEFT 0.12.0
|
| 76 |
+
- Transformers 4.46.0
|
| 77 |
+
- Pytorch 2.4.0+cu121
|
| 78 |
+
- Datasets 2.21.0
|
| 79 |
+
- Tokenizers 0.20.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "mistralai/Mistral-Nemo-Instruct-2407",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"o_proj",
|
| 24 |
+
"up_proj",
|
| 25 |
+
"v_proj",
|
| 26 |
+
"k_proj",
|
| 27 |
+
"q_proj",
|
| 28 |
+
"down_proj",
|
| 29 |
+
"gate_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fc6f0f2265ec16ac2802075075347956a55aa064cd7390d745520d6fdc8c8a35
|
| 3 |
+
size 114106856
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"eval_loss": 0.0005785770481452346,
|
| 4 |
+
"eval_runtime": 108.2417,
|
| 5 |
+
"eval_samples_per_second": 9.239,
|
| 6 |
+
"eval_steps_per_second": 0.231,
|
| 7 |
+
"total_flos": 1.6644589041987092e+18,
|
| 8 |
+
"train_loss": 0.01136111196440955,
|
| 9 |
+
"train_runtime": 7966.0994,
|
| 10 |
+
"train_samples_per_second": 2.26,
|
| 11 |
+
"train_steps_per_second": 0.056
|
| 12 |
+
}
|
checkpoint-450/README.md
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: mistralai/Mistral-Nemo-Instruct-2407
|
| 3 |
+
library_name: peft
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Model Card for Model ID
|
| 7 |
+
|
| 8 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## Model Details
|
| 13 |
+
|
| 14 |
+
### Model Description
|
| 15 |
+
|
| 16 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
- **Developed by:** [More Information Needed]
|
| 21 |
+
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
+
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
+
- **Model type:** [More Information Needed]
|
| 24 |
+
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
+
- **License:** [More Information Needed]
|
| 26 |
+
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
+
|
| 28 |
+
### Model Sources [optional]
|
| 29 |
+
|
| 30 |
+
<!-- Provide the basic links for the model. -->
|
| 31 |
+
|
| 32 |
+
- **Repository:** [More Information Needed]
|
| 33 |
+
- **Paper [optional]:** [More Information Needed]
|
| 34 |
+
- **Demo [optional]:** [More Information Needed]
|
| 35 |
+
|
| 36 |
+
## Uses
|
| 37 |
+
|
| 38 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 39 |
+
|
| 40 |
+
### Direct Use
|
| 41 |
+
|
| 42 |
+
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 43 |
+
|
| 44 |
+
[More Information Needed]
|
| 45 |
+
|
| 46 |
+
### Downstream Use [optional]
|
| 47 |
+
|
| 48 |
+
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 49 |
+
|
| 50 |
+
[More Information Needed]
|
| 51 |
+
|
| 52 |
+
### Out-of-Scope Use
|
| 53 |
+
|
| 54 |
+
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 55 |
+
|
| 56 |
+
[More Information Needed]
|
| 57 |
+
|
| 58 |
+
## Bias, Risks, and Limitations
|
| 59 |
+
|
| 60 |
+
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 61 |
+
|
| 62 |
+
[More Information Needed]
|
| 63 |
+
|
| 64 |
+
### Recommendations
|
| 65 |
+
|
| 66 |
+
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 67 |
+
|
| 68 |
+
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 69 |
+
|
| 70 |
+
## How to Get Started with the Model
|
| 71 |
+
|
| 72 |
+
Use the code below to get started with the model.
|
| 73 |
+
|
| 74 |
+
[More Information Needed]
|
| 75 |
+
|
| 76 |
+
## Training Details
|
| 77 |
+
|
| 78 |
+
### Training Data
|
| 79 |
+
|
| 80 |
+
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 81 |
+
|
| 82 |
+
[More Information Needed]
|
| 83 |
+
|
| 84 |
+
### Training Procedure
|
| 85 |
+
|
| 86 |
+
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 87 |
+
|
| 88 |
+
#### Preprocessing [optional]
|
| 89 |
+
|
| 90 |
+
[More Information Needed]
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
#### Training Hyperparameters
|
| 94 |
+
|
| 95 |
+
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
+
|
| 97 |
+
#### Speeds, Sizes, Times [optional]
|
| 98 |
+
|
| 99 |
+
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 100 |
+
|
| 101 |
+
[More Information Needed]
|
| 102 |
+
|
| 103 |
+
## Evaluation
|
| 104 |
+
|
| 105 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 106 |
+
|
| 107 |
+
### Testing Data, Factors & Metrics
|
| 108 |
+
|
| 109 |
+
#### Testing Data
|
| 110 |
+
|
| 111 |
+
<!-- This should link to a Dataset Card if possible. -->
|
| 112 |
+
|
| 113 |
+
[More Information Needed]
|
| 114 |
+
|
| 115 |
+
#### Factors
|
| 116 |
+
|
| 117 |
+
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
+
|
| 119 |
+
[More Information Needed]
|
| 120 |
+
|
| 121 |
+
#### Metrics
|
| 122 |
+
|
| 123 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
+
|
| 125 |
+
[More Information Needed]
|
| 126 |
+
|
| 127 |
+
### Results
|
| 128 |
+
|
| 129 |
+
[More Information Needed]
|
| 130 |
+
|
| 131 |
+
#### Summary
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
## Model Examination [optional]
|
| 136 |
+
|
| 137 |
+
<!-- Relevant interpretability work for the model goes here -->
|
| 138 |
+
|
| 139 |
+
[More Information Needed]
|
| 140 |
+
|
| 141 |
+
## Environmental Impact
|
| 142 |
+
|
| 143 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 144 |
+
|
| 145 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 146 |
+
|
| 147 |
+
- **Hardware Type:** [More Information Needed]
|
| 148 |
+
- **Hours used:** [More Information Needed]
|
| 149 |
+
- **Cloud Provider:** [More Information Needed]
|
| 150 |
+
- **Compute Region:** [More Information Needed]
|
| 151 |
+
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
+
|
| 153 |
+
## Technical Specifications [optional]
|
| 154 |
+
|
| 155 |
+
### Model Architecture and Objective
|
| 156 |
+
|
| 157 |
+
[More Information Needed]
|
| 158 |
+
|
| 159 |
+
### Compute Infrastructure
|
| 160 |
+
|
| 161 |
+
[More Information Needed]
|
| 162 |
+
|
| 163 |
+
#### Hardware
|
| 164 |
+
|
| 165 |
+
[More Information Needed]
|
| 166 |
+
|
| 167 |
+
#### Software
|
| 168 |
+
|
| 169 |
+
[More Information Needed]
|
| 170 |
+
|
| 171 |
+
## Citation [optional]
|
| 172 |
+
|
| 173 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
+
|
| 175 |
+
**BibTeX:**
|
| 176 |
+
|
| 177 |
+
[More Information Needed]
|
| 178 |
+
|
| 179 |
+
**APA:**
|
| 180 |
+
|
| 181 |
+
[More Information Needed]
|
| 182 |
+
|
| 183 |
+
## Glossary [optional]
|
| 184 |
+
|
| 185 |
+
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 186 |
+
|
| 187 |
+
[More Information Needed]
|
| 188 |
+
|
| 189 |
+
## More Information [optional]
|
| 190 |
+
|
| 191 |
+
[More Information Needed]
|
| 192 |
+
|
| 193 |
+
## Model Card Authors [optional]
|
| 194 |
+
|
| 195 |
+
[More Information Needed]
|
| 196 |
+
|
| 197 |
+
## Model Card Contact
|
| 198 |
+
|
| 199 |
+
[More Information Needed]
|
| 200 |
+
### Framework versions
|
| 201 |
+
|
| 202 |
+
- PEFT 0.12.0
|
checkpoint-450/adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "mistralai/Mistral-Nemo-Instruct-2407",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"o_proj",
|
| 24 |
+
"up_proj",
|
| 25 |
+
"v_proj",
|
| 26 |
+
"k_proj",
|
| 27 |
+
"q_proj",
|
| 28 |
+
"down_proj",
|
| 29 |
+
"gate_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
checkpoint-450/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fc6f0f2265ec16ac2802075075347956a55aa064cd7390d745520d6fdc8c8a35
|
| 3 |
+
size 114106856
|
checkpoint-450/optimizer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:55ebcac98e01061440649acde501123e1c3b7c5d3a17667c4eae73641c8906a8
|
| 3 |
+
size 228536930
|
checkpoint-450/rng_state_0.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4f003069486a57c6ac033f30cf4c4213eb6b7d659bab68a5a50fdb8da7c4118
|
| 3 |
+
size 15024
|
checkpoint-450/rng_state_1.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a016ef89b4392d083b2c15a7cf06a39bc61a759f648cf6dc03f1c32b89a526aa
|
| 3 |
+
size 15024
|
checkpoint-450/rng_state_2.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9b56fe0893036dc052d18d90feba4328b90ea71561942150b07406ac3d7a700e
|
| 3 |
+
size 15024
|
checkpoint-450/rng_state_3.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c0c203d12c2c308dab785ed672c9ca27fb6a2f72acd1e1552d1516c7b0006013
|
| 3 |
+
size 15024
|
checkpoint-450/scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c9636ae38b683f4b5b714bdf172e563b0c593e0efe94f07eea78547963bfbfae
|
| 3 |
+
size 1064
|
checkpoint-450/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
checkpoint-450/tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0240ce510f08e6c2041724e9043e33be9d251d1e4a4d94eb68cd47b954b61d2
|
| 3 |
+
size 17078292
|
checkpoint-450/tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
checkpoint-450/trainer_state.json
ADDED
|
@@ -0,0 +1,468 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.0,
|
| 5 |
+
"eval_steps": 30,
|
| 6 |
+
"global_step": 450,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.044444444444444446,
|
| 13 |
+
"grad_norm": 0.318470299243927,
|
| 14 |
+
"learning_rate": 9.987820251299122e-05,
|
| 15 |
+
"loss": 0.4455,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.08888888888888889,
|
| 20 |
+
"grad_norm": 0.02355371043086052,
|
| 21 |
+
"learning_rate": 9.951340343707852e-05,
|
| 22 |
+
"loss": 0.0053,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.13333333333333333,
|
| 27 |
+
"grad_norm": 0.036702342331409454,
|
| 28 |
+
"learning_rate": 9.890738003669029e-05,
|
| 29 |
+
"loss": 0.004,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.13333333333333333,
|
| 34 |
+
"eval_loss": 0.0037715784274041653,
|
| 35 |
+
"eval_runtime": 108.061,
|
| 36 |
+
"eval_samples_per_second": 9.254,
|
| 37 |
+
"eval_steps_per_second": 0.231,
|
| 38 |
+
"step": 30
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 0.17777777777777778,
|
| 42 |
+
"grad_norm": 0.07428745925426483,
|
| 43 |
+
"learning_rate": 9.806308479691595e-05,
|
| 44 |
+
"loss": 0.0038,
|
| 45 |
+
"step": 40
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 0.2222222222222222,
|
| 49 |
+
"grad_norm": 0.07172686606645584,
|
| 50 |
+
"learning_rate": 9.698463103929542e-05,
|
| 51 |
+
"loss": 0.0038,
|
| 52 |
+
"step": 50
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 0.26666666666666666,
|
| 56 |
+
"grad_norm": 0.03130387142300606,
|
| 57 |
+
"learning_rate": 9.567727288213005e-05,
|
| 58 |
+
"loss": 0.0036,
|
| 59 |
+
"step": 60
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"epoch": 0.26666666666666666,
|
| 63 |
+
"eval_loss": 0.0035628757905215025,
|
| 64 |
+
"eval_runtime": 108.1607,
|
| 65 |
+
"eval_samples_per_second": 9.246,
|
| 66 |
+
"eval_steps_per_second": 0.231,
|
| 67 |
+
"step": 60
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"epoch": 0.3111111111111111,
|
| 71 |
+
"grad_norm": 0.02135792188346386,
|
| 72 |
+
"learning_rate": 9.414737964294636e-05,
|
| 73 |
+
"loss": 0.0036,
|
| 74 |
+
"step": 70
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 0.35555555555555557,
|
| 78 |
+
"grad_norm": 0.1094546914100647,
|
| 79 |
+
"learning_rate": 9.24024048078213e-05,
|
| 80 |
+
"loss": 0.0033,
|
| 81 |
+
"step": 80
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 0.4,
|
| 85 |
+
"grad_norm": 0.15919151902198792,
|
| 86 |
+
"learning_rate": 9.045084971874738e-05,
|
| 87 |
+
"loss": 0.0035,
|
| 88 |
+
"step": 90
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"epoch": 0.4,
|
| 92 |
+
"eval_loss": 0.003310541156679392,
|
| 93 |
+
"eval_runtime": 108.1107,
|
| 94 |
+
"eval_samples_per_second": 9.25,
|
| 95 |
+
"eval_steps_per_second": 0.231,
|
| 96 |
+
"step": 90
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"epoch": 0.4444444444444444,
|
| 100 |
+
"grad_norm": 0.024381157010793686,
|
| 101 |
+
"learning_rate": 8.83022221559489e-05,
|
| 102 |
+
"loss": 0.0029,
|
| 103 |
+
"step": 100
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"epoch": 0.4888888888888889,
|
| 107 |
+
"grad_norm": 0.05485767126083374,
|
| 108 |
+
"learning_rate": 8.596699001693255e-05,
|
| 109 |
+
"loss": 0.002,
|
| 110 |
+
"step": 110
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"epoch": 0.5333333333333333,
|
| 114 |
+
"grad_norm": 0.08088912814855576,
|
| 115 |
+
"learning_rate": 8.345653031794292e-05,
|
| 116 |
+
"loss": 0.0024,
|
| 117 |
+
"step": 120
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"epoch": 0.5333333333333333,
|
| 121 |
+
"eval_loss": 0.0021427080500870943,
|
| 122 |
+
"eval_runtime": 108.1623,
|
| 123 |
+
"eval_samples_per_second": 9.245,
|
| 124 |
+
"eval_steps_per_second": 0.231,
|
| 125 |
+
"step": 120
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"epoch": 0.5777777777777777,
|
| 129 |
+
"grad_norm": 0.09581312537193298,
|
| 130 |
+
"learning_rate": 8.07830737662829e-05,
|
| 131 |
+
"loss": 0.0019,
|
| 132 |
+
"step": 130
|
| 133 |
+
},
|
| 134 |
+
{
|
| 135 |
+
"epoch": 0.6222222222222222,
|
| 136 |
+
"grad_norm": 0.06600484997034073,
|
| 137 |
+
"learning_rate": 7.795964517353735e-05,
|
| 138 |
+
"loss": 0.0012,
|
| 139 |
+
"step": 140
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"epoch": 0.6666666666666666,
|
| 143 |
+
"grad_norm": 0.08135157078504562,
|
| 144 |
+
"learning_rate": 7.500000000000001e-05,
|
| 145 |
+
"loss": 0.0011,
|
| 146 |
+
"step": 150
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"epoch": 0.6666666666666666,
|
| 150 |
+
"eval_loss": 0.0011440212838351727,
|
| 151 |
+
"eval_runtime": 108.1819,
|
| 152 |
+
"eval_samples_per_second": 9.244,
|
| 153 |
+
"eval_steps_per_second": 0.231,
|
| 154 |
+
"step": 150
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"epoch": 0.7111111111111111,
|
| 158 |
+
"grad_norm": 0.0257169920951128,
|
| 159 |
+
"learning_rate": 7.191855733945387e-05,
|
| 160 |
+
"loss": 0.0018,
|
| 161 |
+
"step": 160
|
| 162 |
+
},
|
| 163 |
+
{
|
| 164 |
+
"epoch": 0.7555555555555555,
|
| 165 |
+
"grad_norm": 0.02252952568233013,
|
| 166 |
+
"learning_rate": 6.873032967079561e-05,
|
| 167 |
+
"loss": 0.0013,
|
| 168 |
+
"step": 170
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"epoch": 0.8,
|
| 172 |
+
"grad_norm": 0.015104785561561584,
|
| 173 |
+
"learning_rate": 6.545084971874738e-05,
|
| 174 |
+
"loss": 0.0011,
|
| 175 |
+
"step": 180
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"epoch": 0.8,
|
| 179 |
+
"eval_loss": 0.0008804052486084402,
|
| 180 |
+
"eval_runtime": 108.241,
|
| 181 |
+
"eval_samples_per_second": 9.239,
|
| 182 |
+
"eval_steps_per_second": 0.231,
|
| 183 |
+
"step": 180
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"epoch": 0.8444444444444444,
|
| 187 |
+
"grad_norm": 0.037444427609443665,
|
| 188 |
+
"learning_rate": 6.209609477998338e-05,
|
| 189 |
+
"loss": 0.0009,
|
| 190 |
+
"step": 190
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"epoch": 0.8888888888888888,
|
| 194 |
+
"grad_norm": 0.041397638618946075,
|
| 195 |
+
"learning_rate": 5.868240888334653e-05,
|
| 196 |
+
"loss": 0.0009,
|
| 197 |
+
"step": 200
|
| 198 |
+
},
|
| 199 |
+
{
|
| 200 |
+
"epoch": 0.9333333333333333,
|
| 201 |
+
"grad_norm": 0.04828115180134773,
|
| 202 |
+
"learning_rate": 5.522642316338268e-05,
|
| 203 |
+
"loss": 0.001,
|
| 204 |
+
"step": 210
|
| 205 |
+
},
|
| 206 |
+
{
|
| 207 |
+
"epoch": 0.9333333333333333,
|
| 208 |
+
"eval_loss": 0.0008426142740063369,
|
| 209 |
+
"eval_runtime": 108.1605,
|
| 210 |
+
"eval_samples_per_second": 9.246,
|
| 211 |
+
"eval_steps_per_second": 0.231,
|
| 212 |
+
"step": 210
|
| 213 |
+
},
|
| 214 |
+
{
|
| 215 |
+
"epoch": 0.9777777777777777,
|
| 216 |
+
"grad_norm": 0.09075287729501724,
|
| 217 |
+
"learning_rate": 5.174497483512506e-05,
|
| 218 |
+
"loss": 0.0011,
|
| 219 |
+
"step": 220
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"epoch": 1.0222222222222221,
|
| 223 |
+
"grad_norm": 0.025804603472352028,
|
| 224 |
+
"learning_rate": 4.825502516487497e-05,
|
| 225 |
+
"loss": 0.0009,
|
| 226 |
+
"step": 230
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"epoch": 1.0666666666666667,
|
| 230 |
+
"grad_norm": 0.04228019714355469,
|
| 231 |
+
"learning_rate": 4.477357683661734e-05,
|
| 232 |
+
"loss": 0.0008,
|
| 233 |
+
"step": 240
|
| 234 |
+
},
|
| 235 |
+
{
|
| 236 |
+
"epoch": 1.0666666666666667,
|
| 237 |
+
"eval_loss": 0.000761281349696219,
|
| 238 |
+
"eval_runtime": 108.2466,
|
| 239 |
+
"eval_samples_per_second": 9.238,
|
| 240 |
+
"eval_steps_per_second": 0.231,
|
| 241 |
+
"step": 240
|
| 242 |
+
},
|
| 243 |
+
{
|
| 244 |
+
"epoch": 1.1111111111111112,
|
| 245 |
+
"grad_norm": 0.07708187401294708,
|
| 246 |
+
"learning_rate": 4.131759111665349e-05,
|
| 247 |
+
"loss": 0.0008,
|
| 248 |
+
"step": 250
|
| 249 |
+
},
|
| 250 |
+
{
|
| 251 |
+
"epoch": 1.1555555555555554,
|
| 252 |
+
"grad_norm": 0.090398870408535,
|
| 253 |
+
"learning_rate": 3.790390522001662e-05,
|
| 254 |
+
"loss": 0.0007,
|
| 255 |
+
"step": 260
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"epoch": 1.2,
|
| 259 |
+
"grad_norm": 0.10483791679143906,
|
| 260 |
+
"learning_rate": 3.4549150281252636e-05,
|
| 261 |
+
"loss": 0.0009,
|
| 262 |
+
"step": 270
|
| 263 |
+
},
|
| 264 |
+
{
|
| 265 |
+
"epoch": 1.2,
|
| 266 |
+
"eval_loss": 0.0007036189781501889,
|
| 267 |
+
"eval_runtime": 108.3447,
|
| 268 |
+
"eval_samples_per_second": 9.23,
|
| 269 |
+
"eval_steps_per_second": 0.231,
|
| 270 |
+
"step": 270
|
| 271 |
+
},
|
| 272 |
+
{
|
| 273 |
+
"epoch": 1.2444444444444445,
|
| 274 |
+
"grad_norm": 0.046087298542261124,
|
| 275 |
+
"learning_rate": 3.12696703292044e-05,
|
| 276 |
+
"loss": 0.0008,
|
| 277 |
+
"step": 280
|
| 278 |
+
},
|
| 279 |
+
{
|
| 280 |
+
"epoch": 1.2888888888888888,
|
| 281 |
+
"grad_norm": 0.016715016216039658,
|
| 282 |
+
"learning_rate": 2.8081442660546125e-05,
|
| 283 |
+
"loss": 0.0007,
|
| 284 |
+
"step": 290
|
| 285 |
+
},
|
| 286 |
+
{
|
| 287 |
+
"epoch": 1.3333333333333333,
|
| 288 |
+
"grad_norm": 0.0191776305437088,
|
| 289 |
+
"learning_rate": 2.500000000000001e-05,
|
| 290 |
+
"loss": 0.0006,
|
| 291 |
+
"step": 300
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"epoch": 1.3333333333333333,
|
| 295 |
+
"eval_loss": 0.0006860981229692698,
|
| 296 |
+
"eval_runtime": 108.3015,
|
| 297 |
+
"eval_samples_per_second": 9.233,
|
| 298 |
+
"eval_steps_per_second": 0.231,
|
| 299 |
+
"step": 300
|
| 300 |
+
},
|
| 301 |
+
{
|
| 302 |
+
"epoch": 1.3777777777777778,
|
| 303 |
+
"grad_norm": 0.03184030205011368,
|
| 304 |
+
"learning_rate": 2.2040354826462668e-05,
|
| 305 |
+
"loss": 0.0007,
|
| 306 |
+
"step": 310
|
| 307 |
+
},
|
| 308 |
+
{
|
| 309 |
+
"epoch": 1.4222222222222223,
|
| 310 |
+
"grad_norm": 0.025107963010668755,
|
| 311 |
+
"learning_rate": 1.9216926233717085e-05,
|
| 312 |
+
"loss": 0.0007,
|
| 313 |
+
"step": 320
|
| 314 |
+
},
|
| 315 |
+
{
|
| 316 |
+
"epoch": 1.4666666666666668,
|
| 317 |
+
"grad_norm": 0.023573119193315506,
|
| 318 |
+
"learning_rate": 1.6543469682057106e-05,
|
| 319 |
+
"loss": 0.0006,
|
| 320 |
+
"step": 330
|
| 321 |
+
},
|
| 322 |
+
{
|
| 323 |
+
"epoch": 1.4666666666666668,
|
| 324 |
+
"eval_loss": 0.0006219326751306653,
|
| 325 |
+
"eval_runtime": 108.2828,
|
| 326 |
+
"eval_samples_per_second": 9.235,
|
| 327 |
+
"eval_steps_per_second": 0.231,
|
| 328 |
+
"step": 330
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"epoch": 1.511111111111111,
|
| 332 |
+
"grad_norm": 0.04575636237859726,
|
| 333 |
+
"learning_rate": 1.4033009983067452e-05,
|
| 334 |
+
"loss": 0.0007,
|
| 335 |
+
"step": 340
|
| 336 |
+
},
|
| 337 |
+
{
|
| 338 |
+
"epoch": 1.5555555555555556,
|
| 339 |
+
"grad_norm": 0.1070500984787941,
|
| 340 |
+
"learning_rate": 1.1697777844051105e-05,
|
| 341 |
+
"loss": 0.0007,
|
| 342 |
+
"step": 350
|
| 343 |
+
},
|
| 344 |
+
{
|
| 345 |
+
"epoch": 1.6,
|
| 346 |
+
"grad_norm": 0.03425155580043793,
|
| 347 |
+
"learning_rate": 9.549150281252633e-06,
|
| 348 |
+
"loss": 0.0004,
|
| 349 |
+
"step": 360
|
| 350 |
+
},
|
| 351 |
+
{
|
| 352 |
+
"epoch": 1.6,
|
| 353 |
+
"eval_loss": 0.0006177299073897302,
|
| 354 |
+
"eval_runtime": 108.3475,
|
| 355 |
+
"eval_samples_per_second": 9.23,
|
| 356 |
+
"eval_steps_per_second": 0.231,
|
| 357 |
+
"step": 360
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"epoch": 1.6444444444444444,
|
| 361 |
+
"grad_norm": 0.030520088970661163,
|
| 362 |
+
"learning_rate": 7.597595192178702e-06,
|
| 363 |
+
"loss": 0.0006,
|
| 364 |
+
"step": 370
|
| 365 |
+
},
|
| 366 |
+
{
|
| 367 |
+
"epoch": 1.6888888888888889,
|
| 368 |
+
"grad_norm": 0.010435817763209343,
|
| 369 |
+
"learning_rate": 5.852620357053651e-06,
|
| 370 |
+
"loss": 0.0005,
|
| 371 |
+
"step": 380
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"epoch": 1.7333333333333334,
|
| 375 |
+
"grad_norm": 0.020339515060186386,
|
| 376 |
+
"learning_rate": 4.322727117869951e-06,
|
| 377 |
+
"loss": 0.0007,
|
| 378 |
+
"step": 390
|
| 379 |
+
},
|
| 380 |
+
{
|
| 381 |
+
"epoch": 1.7333333333333334,
|
| 382 |
+
"eval_loss": 0.0006012282683514059,
|
| 383 |
+
"eval_runtime": 108.2882,
|
| 384 |
+
"eval_samples_per_second": 9.235,
|
| 385 |
+
"eval_steps_per_second": 0.231,
|
| 386 |
+
"step": 390
|
| 387 |
+
},
|
| 388 |
+
{
|
| 389 |
+
"epoch": 1.7777777777777777,
|
| 390 |
+
"grad_norm": 0.10952532291412354,
|
| 391 |
+
"learning_rate": 3.0153689607045845e-06,
|
| 392 |
+
"loss": 0.0008,
|
| 393 |
+
"step": 400
|
| 394 |
+
},
|
| 395 |
+
{
|
| 396 |
+
"epoch": 1.8222222222222222,
|
| 397 |
+
"grad_norm": 0.017915133386850357,
|
| 398 |
+
"learning_rate": 1.9369152030840556e-06,
|
| 399 |
+
"loss": 0.0007,
|
| 400 |
+
"step": 410
|
| 401 |
+
},
|
| 402 |
+
{
|
| 403 |
+
"epoch": 1.8666666666666667,
|
| 404 |
+
"grad_norm": 0.04453803971409798,
|
| 405 |
+
"learning_rate": 1.0926199633097157e-06,
|
| 406 |
+
"loss": 0.0005,
|
| 407 |
+
"step": 420
|
| 408 |
+
},
|
| 409 |
+
{
|
| 410 |
+
"epoch": 1.8666666666666667,
|
| 411 |
+
"eval_loss": 0.0006457158015109599,
|
| 412 |
+
"eval_runtime": 108.2276,
|
| 413 |
+
"eval_samples_per_second": 9.24,
|
| 414 |
+
"eval_steps_per_second": 0.231,
|
| 415 |
+
"step": 420
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"epoch": 1.911111111111111,
|
| 419 |
+
"grad_norm": 0.02466416358947754,
|
| 420 |
+
"learning_rate": 4.865965629214819e-07,
|
| 421 |
+
"loss": 0.0006,
|
| 422 |
+
"step": 430
|
| 423 |
+
},
|
| 424 |
+
{
|
| 425 |
+
"epoch": 1.9555555555555557,
|
| 426 |
+
"grad_norm": 0.030644970014691353,
|
| 427 |
+
"learning_rate": 1.2179748700879012e-07,
|
| 428 |
+
"loss": 0.0005,
|
| 429 |
+
"step": 440
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"epoch": 2.0,
|
| 433 |
+
"grad_norm": 0.01875125616788864,
|
| 434 |
+
"learning_rate": 0.0,
|
| 435 |
+
"loss": 0.0005,
|
| 436 |
+
"step": 450
|
| 437 |
+
},
|
| 438 |
+
{
|
| 439 |
+
"epoch": 2.0,
|
| 440 |
+
"eval_loss": 0.0005785770481452346,
|
| 441 |
+
"eval_runtime": 108.2462,
|
| 442 |
+
"eval_samples_per_second": 9.238,
|
| 443 |
+
"eval_steps_per_second": 0.231,
|
| 444 |
+
"step": 450
|
| 445 |
+
}
|
| 446 |
+
],
|
| 447 |
+
"logging_steps": 10,
|
| 448 |
+
"max_steps": 450,
|
| 449 |
+
"num_input_tokens_seen": 0,
|
| 450 |
+
"num_train_epochs": 2,
|
| 451 |
+
"save_steps": 500,
|
| 452 |
+
"stateful_callbacks": {
|
| 453 |
+
"TrainerControl": {
|
| 454 |
+
"args": {
|
| 455 |
+
"should_epoch_stop": false,
|
| 456 |
+
"should_evaluate": false,
|
| 457 |
+
"should_log": false,
|
| 458 |
+
"should_save": true,
|
| 459 |
+
"should_training_stop": true
|
| 460 |
+
},
|
| 461 |
+
"attributes": {}
|
| 462 |
+
}
|
| 463 |
+
},
|
| 464 |
+
"total_flos": 1.6644589041987092e+18,
|
| 465 |
+
"train_batch_size": 10,
|
| 466 |
+
"trial_name": null,
|
| 467 |
+
"trial_params": null
|
| 468 |
+
}
|
checkpoint-450/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e320b14d8cc20928e14b19c6f82f7a45efb3a789e0b326fd634100dbe07f3034
|
| 3 |
+
size 5496
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"eval_loss": 0.0005785770481452346,
|
| 4 |
+
"eval_runtime": 108.2417,
|
| 5 |
+
"eval_samples_per_second": 9.239,
|
| 6 |
+
"eval_steps_per_second": 0.231
|
| 7 |
+
}
|
runs/Jan16_00-20-03_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736986825.ctua-mistral-sft-heat-333c1-hg6rc.1409.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa9e6f7c9b6f671aa45909afe22b6a7e6a3b3e341eb89a548bf39a37e779f7b7
|
| 3 |
+
size 19182
|
runs/Jan16_00-20-03_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736994900.ctua-mistral-sft-heat-333c1-hg6rc.1409.1
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dec3c0e0fdcaa787c55dd82bd79228e8be2e3a60e2aaf5eee1b79984725f2d4a
|
| 3 |
+
size 359
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0240ce510f08e6c2041724e9043e33be9d251d1e4a4d94eb68cd47b954b61d2
|
| 3 |
+
size 17078292
|
tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"total_flos": 1.6644589041987092e+18,
|
| 4 |
+
"train_loss": 0.01136111196440955,
|
| 5 |
+
"train_runtime": 7966.0994,
|
| 6 |
+
"train_samples_per_second": 2.26,
|
| 7 |
+
"train_steps_per_second": 0.056
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 450, "loss": 0.4455, "lr": 9.987820251299122e-05, "epoch": 0.044444444444444446, "percentage": 2.22, "elapsed_time": "0:02:20", "remaining_time": "1:42:57"}
|
| 2 |
+
{"current_steps": 20, "total_steps": 450, "loss": 0.0053, "lr": 9.951340343707852e-05, "epoch": 0.08888888888888889, "percentage": 4.44, "elapsed_time": "0:04:41", "remaining_time": "1:40:45"}
|
| 3 |
+
{"current_steps": 30, "total_steps": 450, "loss": 0.004, "lr": 9.890738003669029e-05, "epoch": 0.13333333333333333, "percentage": 6.67, "elapsed_time": "0:07:02", "remaining_time": "1:38:29"}
|
| 4 |
+
{"current_steps": 30, "total_steps": 450, "eval_loss": 0.0037715784274041653, "epoch": 0.13333333333333333, "percentage": 6.67, "elapsed_time": "0:08:50", "remaining_time": "2:03:42"}
|
| 5 |
+
{"current_steps": 40, "total_steps": 450, "loss": 0.0038, "lr": 9.806308479691595e-05, "epoch": 0.17777777777777778, "percentage": 8.89, "elapsed_time": "0:11:11", "remaining_time": "1:54:37"}
|
| 6 |
+
{"current_steps": 50, "total_steps": 450, "loss": 0.0038, "lr": 9.698463103929542e-05, "epoch": 0.2222222222222222, "percentage": 11.11, "elapsed_time": "0:13:31", "remaining_time": "1:48:14"}
|
| 7 |
+
{"current_steps": 60, "total_steps": 450, "loss": 0.0036, "lr": 9.567727288213005e-05, "epoch": 0.26666666666666666, "percentage": 13.33, "elapsed_time": "0:15:52", "remaining_time": "1:43:12"}
|
| 8 |
+
{"current_steps": 60, "total_steps": 450, "eval_loss": 0.0035628757905215025, "epoch": 0.26666666666666666, "percentage": 13.33, "elapsed_time": "0:17:40", "remaining_time": "1:54:55"}
|
| 9 |
+
{"current_steps": 70, "total_steps": 450, "loss": 0.0036, "lr": 9.414737964294636e-05, "epoch": 0.3111111111111111, "percentage": 15.56, "elapsed_time": "0:20:01", "remaining_time": "1:48:43"}
|
| 10 |
+
{"current_steps": 80, "total_steps": 450, "loss": 0.0033, "lr": 9.24024048078213e-05, "epoch": 0.35555555555555557, "percentage": 17.78, "elapsed_time": "0:22:22", "remaining_time": "1:43:29"}
|
| 11 |
+
{"current_steps": 90, "total_steps": 450, "loss": 0.0035, "lr": 9.045084971874738e-05, "epoch": 0.4, "percentage": 20.0, "elapsed_time": "0:24:43", "remaining_time": "1:38:53"}
|
| 12 |
+
{"current_steps": 90, "total_steps": 450, "eval_loss": 0.003310541156679392, "epoch": 0.4, "percentage": 20.0, "elapsed_time": "0:26:31", "remaining_time": "1:46:06"}
|
| 13 |
+
{"current_steps": 100, "total_steps": 450, "loss": 0.0029, "lr": 8.83022221559489e-05, "epoch": 0.4444444444444444, "percentage": 22.22, "elapsed_time": "0:28:52", "remaining_time": "1:41:03"}
|
| 14 |
+
{"current_steps": 110, "total_steps": 450, "loss": 0.002, "lr": 8.596699001693255e-05, "epoch": 0.4888888888888889, "percentage": 24.44, "elapsed_time": "0:31:13", "remaining_time": "1:36:30"}
|
| 15 |
+
{"current_steps": 120, "total_steps": 450, "loss": 0.0024, "lr": 8.345653031794292e-05, "epoch": 0.5333333333333333, "percentage": 26.67, "elapsed_time": "0:33:34", "remaining_time": "1:32:19"}
|
| 16 |
+
{"current_steps": 120, "total_steps": 450, "eval_loss": 0.0021427080500870943, "epoch": 0.5333333333333333, "percentage": 26.67, "elapsed_time": "0:35:22", "remaining_time": "1:37:17"}
|
| 17 |
+
{"current_steps": 130, "total_steps": 450, "loss": 0.0019, "lr": 8.07830737662829e-05, "epoch": 0.5777777777777777, "percentage": 28.89, "elapsed_time": "0:37:43", "remaining_time": "1:32:51"}
|
| 18 |
+
{"current_steps": 140, "total_steps": 450, "loss": 0.0012, "lr": 7.795964517353735e-05, "epoch": 0.6222222222222222, "percentage": 31.11, "elapsed_time": "0:40:04", "remaining_time": "1:28:44"}
|
| 19 |
+
{"current_steps": 150, "total_steps": 450, "loss": 0.0011, "lr": 7.500000000000001e-05, "epoch": 0.6666666666666666, "percentage": 33.33, "elapsed_time": "0:42:25", "remaining_time": "1:24:50"}
|
| 20 |
+
{"current_steps": 150, "total_steps": 450, "eval_loss": 0.0011440212838351727, "epoch": 0.6666666666666666, "percentage": 33.33, "elapsed_time": "0:44:13", "remaining_time": "1:28:27"}
|
| 21 |
+
{"current_steps": 160, "total_steps": 450, "loss": 0.0018, "lr": 7.191855733945387e-05, "epoch": 0.7111111111111111, "percentage": 35.56, "elapsed_time": "0:46:34", "remaining_time": "1:24:25"}
|
| 22 |
+
{"current_steps": 170, "total_steps": 450, "loss": 0.0013, "lr": 6.873032967079561e-05, "epoch": 0.7555555555555555, "percentage": 37.78, "elapsed_time": "0:48:55", "remaining_time": "1:20:34"}
|
| 23 |
+
{"current_steps": 180, "total_steps": 450, "loss": 0.0011, "lr": 6.545084971874738e-05, "epoch": 0.8, "percentage": 40.0, "elapsed_time": "0:51:16", "remaining_time": "1:16:54"}
|
| 24 |
+
{"current_steps": 180, "total_steps": 450, "eval_loss": 0.0008804052486084402, "epoch": 0.8, "percentage": 40.0, "elapsed_time": "0:53:04", "remaining_time": "1:19:36"}
|
| 25 |
+
{"current_steps": 190, "total_steps": 450, "loss": 0.0009, "lr": 6.209609477998338e-05, "epoch": 0.8444444444444444, "percentage": 42.22, "elapsed_time": "0:55:25", "remaining_time": "1:15:50"}
|
| 26 |
+
{"current_steps": 200, "total_steps": 450, "loss": 0.0009, "lr": 5.868240888334653e-05, "epoch": 0.8888888888888888, "percentage": 44.44, "elapsed_time": "0:57:46", "remaining_time": "1:12:12"}
|
| 27 |
+
{"current_steps": 210, "total_steps": 450, "loss": 0.001, "lr": 5.522642316338268e-05, "epoch": 0.9333333333333333, "percentage": 46.67, "elapsed_time": "1:00:07", "remaining_time": "1:08:42"}
|
| 28 |
+
{"current_steps": 210, "total_steps": 450, "eval_loss": 0.0008426142740063369, "epoch": 0.9333333333333333, "percentage": 46.67, "elapsed_time": "1:01:55", "remaining_time": "1:10:46"}
|
| 29 |
+
{"current_steps": 220, "total_steps": 450, "loss": 0.0011, "lr": 5.174497483512506e-05, "epoch": 0.9777777777777777, "percentage": 48.89, "elapsed_time": "1:04:16", "remaining_time": "1:07:11"}
|
| 30 |
+
{"current_steps": 230, "total_steps": 450, "loss": 0.0009, "lr": 4.825502516487497e-05, "epoch": 1.0222222222222221, "percentage": 51.11, "elapsed_time": "1:06:37", "remaining_time": "1:03:43"}
|
| 31 |
+
{"current_steps": 240, "total_steps": 450, "loss": 0.0008, "lr": 4.477357683661734e-05, "epoch": 1.0666666666666667, "percentage": 53.33, "elapsed_time": "1:08:58", "remaining_time": "1:00:20"}
|
| 32 |
+
{"current_steps": 240, "total_steps": 450, "eval_loss": 0.000761281349696219, "epoch": 1.0666666666666667, "percentage": 53.33, "elapsed_time": "1:10:46", "remaining_time": "1:01:55"}
|
| 33 |
+
{"current_steps": 250, "total_steps": 450, "loss": 0.0008, "lr": 4.131759111665349e-05, "epoch": 1.1111111111111112, "percentage": 55.56, "elapsed_time": "1:13:07", "remaining_time": "0:58:29"}
|
| 34 |
+
{"current_steps": 260, "total_steps": 450, "loss": 0.0007, "lr": 3.790390522001662e-05, "epoch": 1.1555555555555554, "percentage": 57.78, "elapsed_time": "1:15:28", "remaining_time": "0:55:09"}
|
| 35 |
+
{"current_steps": 270, "total_steps": 450, "loss": 0.0009, "lr": 3.4549150281252636e-05, "epoch": 1.2, "percentage": 60.0, "elapsed_time": "1:17:49", "remaining_time": "0:51:52"}
|
| 36 |
+
{"current_steps": 270, "total_steps": 450, "eval_loss": 0.0007036189781501889, "epoch": 1.2, "percentage": 60.0, "elapsed_time": "1:19:37", "remaining_time": "0:53:04"}
|
| 37 |
+
{"current_steps": 280, "total_steps": 450, "loss": 0.0008, "lr": 3.12696703292044e-05, "epoch": 1.2444444444444445, "percentage": 62.22, "elapsed_time": "1:21:58", "remaining_time": "0:49:46"}
|
| 38 |
+
{"current_steps": 290, "total_steps": 450, "loss": 0.0007, "lr": 2.8081442660546125e-05, "epoch": 1.2888888888888888, "percentage": 64.44, "elapsed_time": "1:24:19", "remaining_time": "0:46:31"}
|
| 39 |
+
{"current_steps": 300, "total_steps": 450, "loss": 0.0006, "lr": 2.500000000000001e-05, "epoch": 1.3333333333333333, "percentage": 66.67, "elapsed_time": "1:26:40", "remaining_time": "0:43:20"}
|
| 40 |
+
{"current_steps": 300, "total_steps": 450, "eval_loss": 0.0006860981229692698, "epoch": 1.3333333333333333, "percentage": 66.67, "elapsed_time": "1:28:28", "remaining_time": "0:44:14"}
|
| 41 |
+
{"current_steps": 310, "total_steps": 450, "loss": 0.0007, "lr": 2.2040354826462668e-05, "epoch": 1.3777777777777778, "percentage": 68.89, "elapsed_time": "1:30:49", "remaining_time": "0:41:01"}
|
| 42 |
+
{"current_steps": 320, "total_steps": 450, "loss": 0.0007, "lr": 1.9216926233717085e-05, "epoch": 1.4222222222222223, "percentage": 71.11, "elapsed_time": "1:33:10", "remaining_time": "0:37:51"}
|
| 43 |
+
{"current_steps": 330, "total_steps": 450, "loss": 0.0006, "lr": 1.6543469682057106e-05, "epoch": 1.4666666666666668, "percentage": 73.33, "elapsed_time": "1:35:31", "remaining_time": "0:34:44"}
|
| 44 |
+
{"current_steps": 330, "total_steps": 450, "eval_loss": 0.0006219326751306653, "epoch": 1.4666666666666668, "percentage": 73.33, "elapsed_time": "1:37:19", "remaining_time": "0:35:23"}
|
| 45 |
+
{"current_steps": 340, "total_steps": 450, "loss": 0.0007, "lr": 1.4033009983067452e-05, "epoch": 1.511111111111111, "percentage": 75.56, "elapsed_time": "1:39:40", "remaining_time": "0:32:14"}
|
| 46 |
+
{"current_steps": 350, "total_steps": 450, "loss": 0.0007, "lr": 1.1697777844051105e-05, "epoch": 1.5555555555555556, "percentage": 77.78, "elapsed_time": "1:42:01", "remaining_time": "0:29:09"}
|
| 47 |
+
{"current_steps": 360, "total_steps": 450, "loss": 0.0004, "lr": 9.549150281252633e-06, "epoch": 1.6, "percentage": 80.0, "elapsed_time": "1:44:22", "remaining_time": "0:26:05"}
|
| 48 |
+
{"current_steps": 360, "total_steps": 450, "eval_loss": 0.0006177299073897302, "epoch": 1.6, "percentage": 80.0, "elapsed_time": "1:46:10", "remaining_time": "0:26:32"}
|
| 49 |
+
{"current_steps": 370, "total_steps": 450, "loss": 0.0006, "lr": 7.597595192178702e-06, "epoch": 1.6444444444444444, "percentage": 82.22, "elapsed_time": "1:48:31", "remaining_time": "0:23:27"}
|
| 50 |
+
{"current_steps": 380, "total_steps": 450, "loss": 0.0005, "lr": 5.852620357053651e-06, "epoch": 1.6888888888888889, "percentage": 84.44, "elapsed_time": "1:50:52", "remaining_time": "0:20:25"}
|
| 51 |
+
{"current_steps": 390, "total_steps": 450, "loss": 0.0007, "lr": 4.322727117869951e-06, "epoch": 1.7333333333333334, "percentage": 86.67, "elapsed_time": "1:53:13", "remaining_time": "0:17:25"}
|
| 52 |
+
{"current_steps": 390, "total_steps": 450, "eval_loss": 0.0006012282683514059, "epoch": 1.7333333333333334, "percentage": 86.67, "elapsed_time": "1:55:01", "remaining_time": "0:17:41"}
|
| 53 |
+
{"current_steps": 400, "total_steps": 450, "loss": 0.0008, "lr": 3.0153689607045845e-06, "epoch": 1.7777777777777777, "percentage": 88.89, "elapsed_time": "1:57:22", "remaining_time": "0:14:40"}
|
| 54 |
+
{"current_steps": 410, "total_steps": 450, "loss": 0.0007, "lr": 1.9369152030840556e-06, "epoch": 1.8222222222222222, "percentage": 91.11, "elapsed_time": "1:59:43", "remaining_time": "0:11:40"}
|
| 55 |
+
{"current_steps": 420, "total_steps": 450, "loss": 0.0005, "lr": 1.0926199633097157e-06, "epoch": 1.8666666666666667, "percentage": 93.33, "elapsed_time": "2:02:04", "remaining_time": "0:08:43"}
|
| 56 |
+
{"current_steps": 420, "total_steps": 450, "eval_loss": 0.0006457158015109599, "epoch": 1.8666666666666667, "percentage": 93.33, "elapsed_time": "2:03:52", "remaining_time": "0:08:50"}
|
| 57 |
+
{"current_steps": 430, "total_steps": 450, "loss": 0.0006, "lr": 4.865965629214819e-07, "epoch": 1.911111111111111, "percentage": 95.56, "elapsed_time": "2:06:13", "remaining_time": "0:05:52"}
|
| 58 |
+
{"current_steps": 440, "total_steps": 450, "loss": 0.0005, "lr": 1.2179748700879012e-07, "epoch": 1.9555555555555557, "percentage": 97.78, "elapsed_time": "2:08:34", "remaining_time": "0:02:55"}
|
| 59 |
+
{"current_steps": 450, "total_steps": 450, "loss": 0.0005, "lr": 0.0, "epoch": 2.0, "percentage": 100.0, "elapsed_time": "2:10:54", "remaining_time": "0:00:00"}
|
| 60 |
+
{"current_steps": 450, "total_steps": 450, "eval_loss": 0.0005785770481452346, "epoch": 2.0, "percentage": 100.0, "elapsed_time": "2:12:43", "remaining_time": "0:00:00"}
|
| 61 |
+
{"current_steps": 450, "total_steps": 450, "epoch": 2.0, "percentage": 100.0, "elapsed_time": "2:12:44", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,477 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.0,
|
| 5 |
+
"eval_steps": 30,
|
| 6 |
+
"global_step": 450,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.044444444444444446,
|
| 13 |
+
"grad_norm": 0.318470299243927,
|
| 14 |
+
"learning_rate": 9.987820251299122e-05,
|
| 15 |
+
"loss": 0.4455,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.08888888888888889,
|
| 20 |
+
"grad_norm": 0.02355371043086052,
|
| 21 |
+
"learning_rate": 9.951340343707852e-05,
|
| 22 |
+
"loss": 0.0053,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.13333333333333333,
|
| 27 |
+
"grad_norm": 0.036702342331409454,
|
| 28 |
+
"learning_rate": 9.890738003669029e-05,
|
| 29 |
+
"loss": 0.004,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.13333333333333333,
|
| 34 |
+
"eval_loss": 0.0037715784274041653,
|
| 35 |
+
"eval_runtime": 108.061,
|
| 36 |
+
"eval_samples_per_second": 9.254,
|
| 37 |
+
"eval_steps_per_second": 0.231,
|
| 38 |
+
"step": 30
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 0.17777777777777778,
|
| 42 |
+
"grad_norm": 0.07428745925426483,
|
| 43 |
+
"learning_rate": 9.806308479691595e-05,
|
| 44 |
+
"loss": 0.0038,
|
| 45 |
+
"step": 40
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 0.2222222222222222,
|
| 49 |
+
"grad_norm": 0.07172686606645584,
|
| 50 |
+
"learning_rate": 9.698463103929542e-05,
|
| 51 |
+
"loss": 0.0038,
|
| 52 |
+
"step": 50
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 0.26666666666666666,
|
| 56 |
+
"grad_norm": 0.03130387142300606,
|
| 57 |
+
"learning_rate": 9.567727288213005e-05,
|
| 58 |
+
"loss": 0.0036,
|
| 59 |
+
"step": 60
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"epoch": 0.26666666666666666,
|
| 63 |
+
"eval_loss": 0.0035628757905215025,
|
| 64 |
+
"eval_runtime": 108.1607,
|
| 65 |
+
"eval_samples_per_second": 9.246,
|
| 66 |
+
"eval_steps_per_second": 0.231,
|
| 67 |
+
"step": 60
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"epoch": 0.3111111111111111,
|
| 71 |
+
"grad_norm": 0.02135792188346386,
|
| 72 |
+
"learning_rate": 9.414737964294636e-05,
|
| 73 |
+
"loss": 0.0036,
|
| 74 |
+
"step": 70
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 0.35555555555555557,
|
| 78 |
+
"grad_norm": 0.1094546914100647,
|
| 79 |
+
"learning_rate": 9.24024048078213e-05,
|
| 80 |
+
"loss": 0.0033,
|
| 81 |
+
"step": 80
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 0.4,
|
| 85 |
+
"grad_norm": 0.15919151902198792,
|
| 86 |
+
"learning_rate": 9.045084971874738e-05,
|
| 87 |
+
"loss": 0.0035,
|
| 88 |
+
"step": 90
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"epoch": 0.4,
|
| 92 |
+
"eval_loss": 0.003310541156679392,
|
| 93 |
+
"eval_runtime": 108.1107,
|
| 94 |
+
"eval_samples_per_second": 9.25,
|
| 95 |
+
"eval_steps_per_second": 0.231,
|
| 96 |
+
"step": 90
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"epoch": 0.4444444444444444,
|
| 100 |
+
"grad_norm": 0.024381157010793686,
|
| 101 |
+
"learning_rate": 8.83022221559489e-05,
|
| 102 |
+
"loss": 0.0029,
|
| 103 |
+
"step": 100
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"epoch": 0.4888888888888889,
|
| 107 |
+
"grad_norm": 0.05485767126083374,
|
| 108 |
+
"learning_rate": 8.596699001693255e-05,
|
| 109 |
+
"loss": 0.002,
|
| 110 |
+
"step": 110
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"epoch": 0.5333333333333333,
|
| 114 |
+
"grad_norm": 0.08088912814855576,
|
| 115 |
+
"learning_rate": 8.345653031794292e-05,
|
| 116 |
+
"loss": 0.0024,
|
| 117 |
+
"step": 120
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"epoch": 0.5333333333333333,
|
| 121 |
+
"eval_loss": 0.0021427080500870943,
|
| 122 |
+
"eval_runtime": 108.1623,
|
| 123 |
+
"eval_samples_per_second": 9.245,
|
| 124 |
+
"eval_steps_per_second": 0.231,
|
| 125 |
+
"step": 120
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"epoch": 0.5777777777777777,
|
| 129 |
+
"grad_norm": 0.09581312537193298,
|
| 130 |
+
"learning_rate": 8.07830737662829e-05,
|
| 131 |
+
"loss": 0.0019,
|
| 132 |
+
"step": 130
|
| 133 |
+
},
|
| 134 |
+
{
|
| 135 |
+
"epoch": 0.6222222222222222,
|
| 136 |
+
"grad_norm": 0.06600484997034073,
|
| 137 |
+
"learning_rate": 7.795964517353735e-05,
|
| 138 |
+
"loss": 0.0012,
|
| 139 |
+
"step": 140
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"epoch": 0.6666666666666666,
|
| 143 |
+
"grad_norm": 0.08135157078504562,
|
| 144 |
+
"learning_rate": 7.500000000000001e-05,
|
| 145 |
+
"loss": 0.0011,
|
| 146 |
+
"step": 150
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"epoch": 0.6666666666666666,
|
| 150 |
+
"eval_loss": 0.0011440212838351727,
|
| 151 |
+
"eval_runtime": 108.1819,
|
| 152 |
+
"eval_samples_per_second": 9.244,
|
| 153 |
+
"eval_steps_per_second": 0.231,
|
| 154 |
+
"step": 150
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"epoch": 0.7111111111111111,
|
| 158 |
+
"grad_norm": 0.0257169920951128,
|
| 159 |
+
"learning_rate": 7.191855733945387e-05,
|
| 160 |
+
"loss": 0.0018,
|
| 161 |
+
"step": 160
|
| 162 |
+
},
|
| 163 |
+
{
|
| 164 |
+
"epoch": 0.7555555555555555,
|
| 165 |
+
"grad_norm": 0.02252952568233013,
|
| 166 |
+
"learning_rate": 6.873032967079561e-05,
|
| 167 |
+
"loss": 0.0013,
|
| 168 |
+
"step": 170
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"epoch": 0.8,
|
| 172 |
+
"grad_norm": 0.015104785561561584,
|
| 173 |
+
"learning_rate": 6.545084971874738e-05,
|
| 174 |
+
"loss": 0.0011,
|
| 175 |
+
"step": 180
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"epoch": 0.8,
|
| 179 |
+
"eval_loss": 0.0008804052486084402,
|
| 180 |
+
"eval_runtime": 108.241,
|
| 181 |
+
"eval_samples_per_second": 9.239,
|
| 182 |
+
"eval_steps_per_second": 0.231,
|
| 183 |
+
"step": 180
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"epoch": 0.8444444444444444,
|
| 187 |
+
"grad_norm": 0.037444427609443665,
|
| 188 |
+
"learning_rate": 6.209609477998338e-05,
|
| 189 |
+
"loss": 0.0009,
|
| 190 |
+
"step": 190
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"epoch": 0.8888888888888888,
|
| 194 |
+
"grad_norm": 0.041397638618946075,
|
| 195 |
+
"learning_rate": 5.868240888334653e-05,
|
| 196 |
+
"loss": 0.0009,
|
| 197 |
+
"step": 200
|
| 198 |
+
},
|
| 199 |
+
{
|
| 200 |
+
"epoch": 0.9333333333333333,
|
| 201 |
+
"grad_norm": 0.04828115180134773,
|
| 202 |
+
"learning_rate": 5.522642316338268e-05,
|
| 203 |
+
"loss": 0.001,
|
| 204 |
+
"step": 210
|
| 205 |
+
},
|
| 206 |
+
{
|
| 207 |
+
"epoch": 0.9333333333333333,
|
| 208 |
+
"eval_loss": 0.0008426142740063369,
|
| 209 |
+
"eval_runtime": 108.1605,
|
| 210 |
+
"eval_samples_per_second": 9.246,
|
| 211 |
+
"eval_steps_per_second": 0.231,
|
| 212 |
+
"step": 210
|
| 213 |
+
},
|
| 214 |
+
{
|
| 215 |
+
"epoch": 0.9777777777777777,
|
| 216 |
+
"grad_norm": 0.09075287729501724,
|
| 217 |
+
"learning_rate": 5.174497483512506e-05,
|
| 218 |
+
"loss": 0.0011,
|
| 219 |
+
"step": 220
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"epoch": 1.0222222222222221,
|
| 223 |
+
"grad_norm": 0.025804603472352028,
|
| 224 |
+
"learning_rate": 4.825502516487497e-05,
|
| 225 |
+
"loss": 0.0009,
|
| 226 |
+
"step": 230
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"epoch": 1.0666666666666667,
|
| 230 |
+
"grad_norm": 0.04228019714355469,
|
| 231 |
+
"learning_rate": 4.477357683661734e-05,
|
| 232 |
+
"loss": 0.0008,
|
| 233 |
+
"step": 240
|
| 234 |
+
},
|
| 235 |
+
{
|
| 236 |
+
"epoch": 1.0666666666666667,
|
| 237 |
+
"eval_loss": 0.000761281349696219,
|
| 238 |
+
"eval_runtime": 108.2466,
|
| 239 |
+
"eval_samples_per_second": 9.238,
|
| 240 |
+
"eval_steps_per_second": 0.231,
|
| 241 |
+
"step": 240
|
| 242 |
+
},
|
| 243 |
+
{
|
| 244 |
+
"epoch": 1.1111111111111112,
|
| 245 |
+
"grad_norm": 0.07708187401294708,
|
| 246 |
+
"learning_rate": 4.131759111665349e-05,
|
| 247 |
+
"loss": 0.0008,
|
| 248 |
+
"step": 250
|
| 249 |
+
},
|
| 250 |
+
{
|
| 251 |
+
"epoch": 1.1555555555555554,
|
| 252 |
+
"grad_norm": 0.090398870408535,
|
| 253 |
+
"learning_rate": 3.790390522001662e-05,
|
| 254 |
+
"loss": 0.0007,
|
| 255 |
+
"step": 260
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"epoch": 1.2,
|
| 259 |
+
"grad_norm": 0.10483791679143906,
|
| 260 |
+
"learning_rate": 3.4549150281252636e-05,
|
| 261 |
+
"loss": 0.0009,
|
| 262 |
+
"step": 270
|
| 263 |
+
},
|
| 264 |
+
{
|
| 265 |
+
"epoch": 1.2,
|
| 266 |
+
"eval_loss": 0.0007036189781501889,
|
| 267 |
+
"eval_runtime": 108.3447,
|
| 268 |
+
"eval_samples_per_second": 9.23,
|
| 269 |
+
"eval_steps_per_second": 0.231,
|
| 270 |
+
"step": 270
|
| 271 |
+
},
|
| 272 |
+
{
|
| 273 |
+
"epoch": 1.2444444444444445,
|
| 274 |
+
"grad_norm": 0.046087298542261124,
|
| 275 |
+
"learning_rate": 3.12696703292044e-05,
|
| 276 |
+
"loss": 0.0008,
|
| 277 |
+
"step": 280
|
| 278 |
+
},
|
| 279 |
+
{
|
| 280 |
+
"epoch": 1.2888888888888888,
|
| 281 |
+
"grad_norm": 0.016715016216039658,
|
| 282 |
+
"learning_rate": 2.8081442660546125e-05,
|
| 283 |
+
"loss": 0.0007,
|
| 284 |
+
"step": 290
|
| 285 |
+
},
|
| 286 |
+
{
|
| 287 |
+
"epoch": 1.3333333333333333,
|
| 288 |
+
"grad_norm": 0.0191776305437088,
|
| 289 |
+
"learning_rate": 2.500000000000001e-05,
|
| 290 |
+
"loss": 0.0006,
|
| 291 |
+
"step": 300
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"epoch": 1.3333333333333333,
|
| 295 |
+
"eval_loss": 0.0006860981229692698,
|
| 296 |
+
"eval_runtime": 108.3015,
|
| 297 |
+
"eval_samples_per_second": 9.233,
|
| 298 |
+
"eval_steps_per_second": 0.231,
|
| 299 |
+
"step": 300
|
| 300 |
+
},
|
| 301 |
+
{
|
| 302 |
+
"epoch": 1.3777777777777778,
|
| 303 |
+
"grad_norm": 0.03184030205011368,
|
| 304 |
+
"learning_rate": 2.2040354826462668e-05,
|
| 305 |
+
"loss": 0.0007,
|
| 306 |
+
"step": 310
|
| 307 |
+
},
|
| 308 |
+
{
|
| 309 |
+
"epoch": 1.4222222222222223,
|
| 310 |
+
"grad_norm": 0.025107963010668755,
|
| 311 |
+
"learning_rate": 1.9216926233717085e-05,
|
| 312 |
+
"loss": 0.0007,
|
| 313 |
+
"step": 320
|
| 314 |
+
},
|
| 315 |
+
{
|
| 316 |
+
"epoch": 1.4666666666666668,
|
| 317 |
+
"grad_norm": 0.023573119193315506,
|
| 318 |
+
"learning_rate": 1.6543469682057106e-05,
|
| 319 |
+
"loss": 0.0006,
|
| 320 |
+
"step": 330
|
| 321 |
+
},
|
| 322 |
+
{
|
| 323 |
+
"epoch": 1.4666666666666668,
|
| 324 |
+
"eval_loss": 0.0006219326751306653,
|
| 325 |
+
"eval_runtime": 108.2828,
|
| 326 |
+
"eval_samples_per_second": 9.235,
|
| 327 |
+
"eval_steps_per_second": 0.231,
|
| 328 |
+
"step": 330
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"epoch": 1.511111111111111,
|
| 332 |
+
"grad_norm": 0.04575636237859726,
|
| 333 |
+
"learning_rate": 1.4033009983067452e-05,
|
| 334 |
+
"loss": 0.0007,
|
| 335 |
+
"step": 340
|
| 336 |
+
},
|
| 337 |
+
{
|
| 338 |
+
"epoch": 1.5555555555555556,
|
| 339 |
+
"grad_norm": 0.1070500984787941,
|
| 340 |
+
"learning_rate": 1.1697777844051105e-05,
|
| 341 |
+
"loss": 0.0007,
|
| 342 |
+
"step": 350
|
| 343 |
+
},
|
| 344 |
+
{
|
| 345 |
+
"epoch": 1.6,
|
| 346 |
+
"grad_norm": 0.03425155580043793,
|
| 347 |
+
"learning_rate": 9.549150281252633e-06,
|
| 348 |
+
"loss": 0.0004,
|
| 349 |
+
"step": 360
|
| 350 |
+
},
|
| 351 |
+
{
|
| 352 |
+
"epoch": 1.6,
|
| 353 |
+
"eval_loss": 0.0006177299073897302,
|
| 354 |
+
"eval_runtime": 108.3475,
|
| 355 |
+
"eval_samples_per_second": 9.23,
|
| 356 |
+
"eval_steps_per_second": 0.231,
|
| 357 |
+
"step": 360
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"epoch": 1.6444444444444444,
|
| 361 |
+
"grad_norm": 0.030520088970661163,
|
| 362 |
+
"learning_rate": 7.597595192178702e-06,
|
| 363 |
+
"loss": 0.0006,
|
| 364 |
+
"step": 370
|
| 365 |
+
},
|
| 366 |
+
{
|
| 367 |
+
"epoch": 1.6888888888888889,
|
| 368 |
+
"grad_norm": 0.010435817763209343,
|
| 369 |
+
"learning_rate": 5.852620357053651e-06,
|
| 370 |
+
"loss": 0.0005,
|
| 371 |
+
"step": 380
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"epoch": 1.7333333333333334,
|
| 375 |
+
"grad_norm": 0.020339515060186386,
|
| 376 |
+
"learning_rate": 4.322727117869951e-06,
|
| 377 |
+
"loss": 0.0007,
|
| 378 |
+
"step": 390
|
| 379 |
+
},
|
| 380 |
+
{
|
| 381 |
+
"epoch": 1.7333333333333334,
|
| 382 |
+
"eval_loss": 0.0006012282683514059,
|
| 383 |
+
"eval_runtime": 108.2882,
|
| 384 |
+
"eval_samples_per_second": 9.235,
|
| 385 |
+
"eval_steps_per_second": 0.231,
|
| 386 |
+
"step": 390
|
| 387 |
+
},
|
| 388 |
+
{
|
| 389 |
+
"epoch": 1.7777777777777777,
|
| 390 |
+
"grad_norm": 0.10952532291412354,
|
| 391 |
+
"learning_rate": 3.0153689607045845e-06,
|
| 392 |
+
"loss": 0.0008,
|
| 393 |
+
"step": 400
|
| 394 |
+
},
|
| 395 |
+
{
|
| 396 |
+
"epoch": 1.8222222222222222,
|
| 397 |
+
"grad_norm": 0.017915133386850357,
|
| 398 |
+
"learning_rate": 1.9369152030840556e-06,
|
| 399 |
+
"loss": 0.0007,
|
| 400 |
+
"step": 410
|
| 401 |
+
},
|
| 402 |
+
{
|
| 403 |
+
"epoch": 1.8666666666666667,
|
| 404 |
+
"grad_norm": 0.04453803971409798,
|
| 405 |
+
"learning_rate": 1.0926199633097157e-06,
|
| 406 |
+
"loss": 0.0005,
|
| 407 |
+
"step": 420
|
| 408 |
+
},
|
| 409 |
+
{
|
| 410 |
+
"epoch": 1.8666666666666667,
|
| 411 |
+
"eval_loss": 0.0006457158015109599,
|
| 412 |
+
"eval_runtime": 108.2276,
|
| 413 |
+
"eval_samples_per_second": 9.24,
|
| 414 |
+
"eval_steps_per_second": 0.231,
|
| 415 |
+
"step": 420
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"epoch": 1.911111111111111,
|
| 419 |
+
"grad_norm": 0.02466416358947754,
|
| 420 |
+
"learning_rate": 4.865965629214819e-07,
|
| 421 |
+
"loss": 0.0006,
|
| 422 |
+
"step": 430
|
| 423 |
+
},
|
| 424 |
+
{
|
| 425 |
+
"epoch": 1.9555555555555557,
|
| 426 |
+
"grad_norm": 0.030644970014691353,
|
| 427 |
+
"learning_rate": 1.2179748700879012e-07,
|
| 428 |
+
"loss": 0.0005,
|
| 429 |
+
"step": 440
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"epoch": 2.0,
|
| 433 |
+
"grad_norm": 0.01875125616788864,
|
| 434 |
+
"learning_rate": 0.0,
|
| 435 |
+
"loss": 0.0005,
|
| 436 |
+
"step": 450
|
| 437 |
+
},
|
| 438 |
+
{
|
| 439 |
+
"epoch": 2.0,
|
| 440 |
+
"eval_loss": 0.0005785770481452346,
|
| 441 |
+
"eval_runtime": 108.2462,
|
| 442 |
+
"eval_samples_per_second": 9.238,
|
| 443 |
+
"eval_steps_per_second": 0.231,
|
| 444 |
+
"step": 450
|
| 445 |
+
},
|
| 446 |
+
{
|
| 447 |
+
"epoch": 2.0,
|
| 448 |
+
"step": 450,
|
| 449 |
+
"total_flos": 1.6644589041987092e+18,
|
| 450 |
+
"train_loss": 0.01136111196440955,
|
| 451 |
+
"train_runtime": 7966.0994,
|
| 452 |
+
"train_samples_per_second": 2.26,
|
| 453 |
+
"train_steps_per_second": 0.056
|
| 454 |
+
}
|
| 455 |
+
],
|
| 456 |
+
"logging_steps": 10,
|
| 457 |
+
"max_steps": 450,
|
| 458 |
+
"num_input_tokens_seen": 0,
|
| 459 |
+
"num_train_epochs": 2,
|
| 460 |
+
"save_steps": 500,
|
| 461 |
+
"stateful_callbacks": {
|
| 462 |
+
"TrainerControl": {
|
| 463 |
+
"args": {
|
| 464 |
+
"should_epoch_stop": false,
|
| 465 |
+
"should_evaluate": false,
|
| 466 |
+
"should_log": false,
|
| 467 |
+
"should_save": true,
|
| 468 |
+
"should_training_stop": true
|
| 469 |
+
},
|
| 470 |
+
"attributes": {}
|
| 471 |
+
}
|
| 472 |
+
},
|
| 473 |
+
"total_flos": 1.6644589041987092e+18,
|
| 474 |
+
"train_batch_size": 10,
|
| 475 |
+
"trial_name": null,
|
| 476 |
+
"trial_params": null
|
| 477 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e320b14d8cc20928e14b19c6f82f7a45efb3a789e0b326fd634100dbe07f3034
|
| 3 |
+
size 5496
|
training_eval_loss.png
ADDED
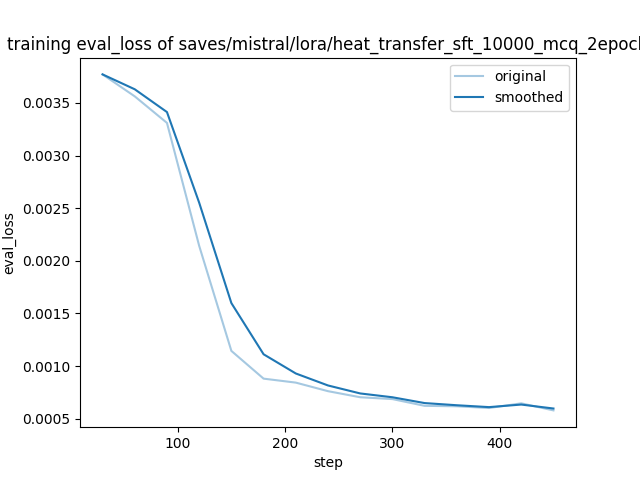
|
training_loss.png
ADDED
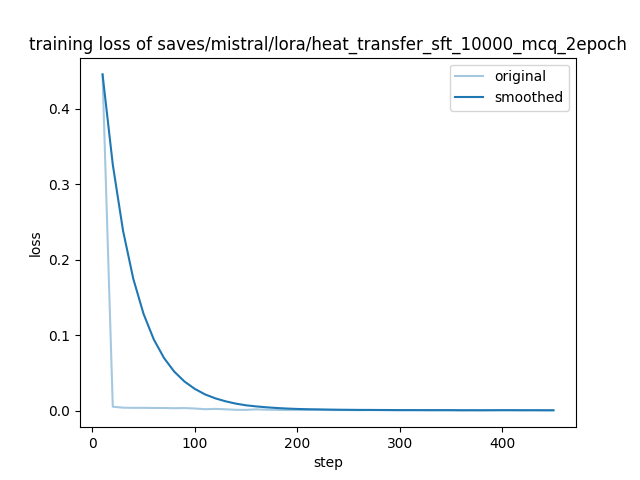
|