
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- README.md +67 -0
- adapter_config.json +34 -0
- adapter_model.safetensors +3 -0
- all_results.json +12 -0
- checkpoint-113/README.md +202 -0
- checkpoint-113/adapter_config.json +34 -0
- checkpoint-113/adapter_model.safetensors +3 -0
- checkpoint-113/optimizer.pt +3 -0
- checkpoint-113/rng_state_0.pth +3 -0
- checkpoint-113/rng_state_1.pth +3 -0
- checkpoint-113/rng_state_2.pth +3 -0
- checkpoint-113/rng_state_3.pth +3 -0
- checkpoint-113/scheduler.pt +3 -0
- checkpoint-113/special_tokens_map.json +24 -0
- checkpoint-113/tokenizer.json +3 -0
- checkpoint-113/tokenizer_config.json +0 -0
- checkpoint-113/trainer_state.json +134 -0
- checkpoint-113/training_args.bin +3 -0
- eval_results.json +7 -0
- runs/Jan15_22-30-44_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736980852.ctua-mistral-sft-heat-333c1-hg6rc.318.0 +3 -0
- runs/Jan15_22-30-44_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736982668.ctua-mistral-sft-heat-333c1-hg6rc.318.1 +3 -0
- special_tokens_map.json +24 -0
- tokenizer.json +3 -0
- tokenizer_config.json +0 -0
- train_results.json +8 -0
- trainer_log.jsonl +15 -0
- trainer_state.json +143 -0
- training_args.bin +3 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
checkpoint-113/tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: mistralai/Mistral-Nemo-Instruct-2407
|
| 3 |
+
library_name: peft
|
| 4 |
+
license: other
|
| 5 |
+
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- lora
|
| 8 |
+
- generated_from_trainer
|
| 9 |
+
model-index:
|
| 10 |
+
- name: heat_transfer_sft_5000_mcq_1epoch
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# heat_transfer_sft_5000_mcq_1epoch
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [mistralai/Mistral-Nemo-Instruct-2407](https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407) on the heat_transfer_5000_mcq dataset.
|
| 20 |
+
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.0035
|
| 22 |
+
|
| 23 |
+
## Model description
|
| 24 |
+
|
| 25 |
+
More information needed
|
| 26 |
+
|
| 27 |
+
## Intended uses & limitations
|
| 28 |
+
|
| 29 |
+
More information needed
|
| 30 |
+
|
| 31 |
+
## Training and evaluation data
|
| 32 |
+
|
| 33 |
+
More information needed
|
| 34 |
+
|
| 35 |
+
## Training procedure
|
| 36 |
+
|
| 37 |
+
### Training hyperparameters
|
| 38 |
+
|
| 39 |
+
The following hyperparameters were used during training:
|
| 40 |
+
- learning_rate: 0.0001
|
| 41 |
+
- train_batch_size: 10
|
| 42 |
+
- eval_batch_size: 10
|
| 43 |
+
- seed: 42
|
| 44 |
+
- distributed_type: multi-GPU
|
| 45 |
+
- num_devices: 4
|
| 46 |
+
- total_train_batch_size: 40
|
| 47 |
+
- total_eval_batch_size: 40
|
| 48 |
+
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 49 |
+
- lr_scheduler_type: cosine
|
| 50 |
+
- num_epochs: 1
|
| 51 |
+
|
| 52 |
+
### Training results
|
| 53 |
+
|
| 54 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 55 |
+
|:-------------:|:------:|:----:|:---------------:|
|
| 56 |
+
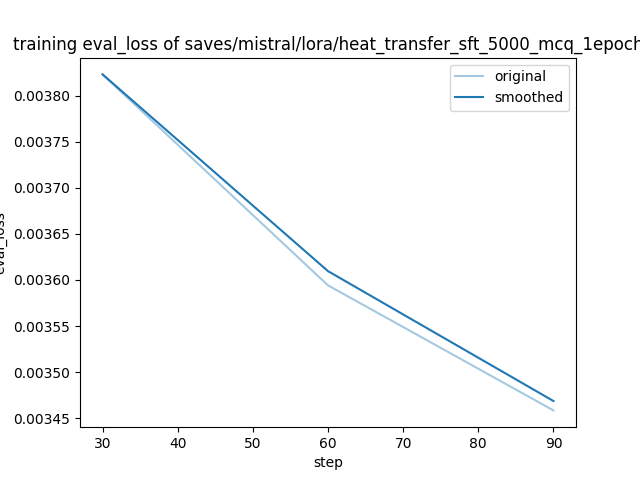
| 0.004 | 0.2655 | 30 | 0.0038 |
|
| 57 |
+
| 0.0037 | 0.5310 | 60 | 0.0036 |
|
| 58 |
+
| 0.0035 | 0.7965 | 90 | 0.0035 |
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
### Framework versions
|
| 62 |
+
|
| 63 |
+
- PEFT 0.12.0
|
| 64 |
+
- Transformers 4.46.0
|
| 65 |
+
- Pytorch 2.4.0+cu121
|
| 66 |
+
- Datasets 2.21.0
|
| 67 |
+
- Tokenizers 0.20.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "mistralai/Mistral-Nemo-Instruct-2407",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"q_proj",
|
| 24 |
+
"down_proj",
|
| 25 |
+
"k_proj",
|
| 26 |
+
"o_proj",
|
| 27 |
+
"gate_proj",
|
| 28 |
+
"v_proj",
|
| 29 |
+
"up_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:52802d6fe841aab344f58af86ae4e93858c4cfa88133b5fa9682f91d0290f6e4
|
| 3 |
+
size 114106856
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 0.0034613024909049273,
|
| 4 |
+
"eval_runtime": 56.0786,
|
| 5 |
+
"eval_samples_per_second": 8.916,
|
| 6 |
+
"eval_steps_per_second": 0.232,
|
| 7 |
+
"total_flos": 4.179655240942879e+17,
|
| 8 |
+
"train_loss": 0.042722021724072703,
|
| 9 |
+
"train_runtime": 1759.0892,
|
| 10 |
+
"train_samples_per_second": 2.558,
|
| 11 |
+
"train_steps_per_second": 0.064
|
| 12 |
+
}
|
checkpoint-113/README.md
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: mistralai/Mistral-Nemo-Instruct-2407
|
| 3 |
+
library_name: peft
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Model Card for Model ID
|
| 7 |
+
|
| 8 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## Model Details
|
| 13 |
+
|
| 14 |
+
### Model Description
|
| 15 |
+
|
| 16 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
- **Developed by:** [More Information Needed]
|
| 21 |
+
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
+
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
+
- **Model type:** [More Information Needed]
|
| 24 |
+
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
+
- **License:** [More Information Needed]
|
| 26 |
+
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
+
|
| 28 |
+
### Model Sources [optional]
|
| 29 |
+
|
| 30 |
+
<!-- Provide the basic links for the model. -->
|
| 31 |
+
|
| 32 |
+
- **Repository:** [More Information Needed]
|
| 33 |
+
- **Paper [optional]:** [More Information Needed]
|
| 34 |
+
- **Demo [optional]:** [More Information Needed]
|
| 35 |
+
|
| 36 |
+
## Uses
|
| 37 |
+
|
| 38 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 39 |
+
|
| 40 |
+
### Direct Use
|
| 41 |
+
|
| 42 |
+
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 43 |
+
|
| 44 |
+
[More Information Needed]
|
| 45 |
+
|
| 46 |
+
### Downstream Use [optional]
|
| 47 |
+
|
| 48 |
+
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 49 |
+
|
| 50 |
+
[More Information Needed]
|
| 51 |
+
|
| 52 |
+
### Out-of-Scope Use
|
| 53 |
+
|
| 54 |
+
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 55 |
+
|
| 56 |
+
[More Information Needed]
|
| 57 |
+
|
| 58 |
+
## Bias, Risks, and Limitations
|
| 59 |
+
|
| 60 |
+
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 61 |
+
|
| 62 |
+
[More Information Needed]
|
| 63 |
+
|
| 64 |
+
### Recommendations
|
| 65 |
+
|
| 66 |
+
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 67 |
+
|
| 68 |
+
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 69 |
+
|
| 70 |
+
## How to Get Started with the Model
|
| 71 |
+
|
| 72 |
+
Use the code below to get started with the model.
|
| 73 |
+
|
| 74 |
+
[More Information Needed]
|
| 75 |
+
|
| 76 |
+
## Training Details
|
| 77 |
+
|
| 78 |
+
### Training Data
|
| 79 |
+
|
| 80 |
+
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 81 |
+
|
| 82 |
+
[More Information Needed]
|
| 83 |
+
|
| 84 |
+
### Training Procedure
|
| 85 |
+
|
| 86 |
+
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 87 |
+
|
| 88 |
+
#### Preprocessing [optional]
|
| 89 |
+
|
| 90 |
+
[More Information Needed]
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
#### Training Hyperparameters
|
| 94 |
+
|
| 95 |
+
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
+
|
| 97 |
+
#### Speeds, Sizes, Times [optional]
|
| 98 |
+
|
| 99 |
+
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 100 |
+
|
| 101 |
+
[More Information Needed]
|
| 102 |
+
|
| 103 |
+
## Evaluation
|
| 104 |
+
|
| 105 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 106 |
+
|
| 107 |
+
### Testing Data, Factors & Metrics
|
| 108 |
+
|
| 109 |
+
#### Testing Data
|
| 110 |
+
|
| 111 |
+
<!-- This should link to a Dataset Card if possible. -->
|
| 112 |
+
|
| 113 |
+
[More Information Needed]
|
| 114 |
+
|
| 115 |
+
#### Factors
|
| 116 |
+
|
| 117 |
+
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
+
|
| 119 |
+
[More Information Needed]
|
| 120 |
+
|
| 121 |
+
#### Metrics
|
| 122 |
+
|
| 123 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
+
|
| 125 |
+
[More Information Needed]
|
| 126 |
+
|
| 127 |
+
### Results
|
| 128 |
+
|
| 129 |
+
[More Information Needed]
|
| 130 |
+
|
| 131 |
+
#### Summary
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
## Model Examination [optional]
|
| 136 |
+
|
| 137 |
+
<!-- Relevant interpretability work for the model goes here -->
|
| 138 |
+
|
| 139 |
+
[More Information Needed]
|
| 140 |
+
|
| 141 |
+
## Environmental Impact
|
| 142 |
+
|
| 143 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 144 |
+
|
| 145 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 146 |
+
|
| 147 |
+
- **Hardware Type:** [More Information Needed]
|
| 148 |
+
- **Hours used:** [More Information Needed]
|
| 149 |
+
- **Cloud Provider:** [More Information Needed]
|
| 150 |
+
- **Compute Region:** [More Information Needed]
|
| 151 |
+
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
+
|
| 153 |
+
## Technical Specifications [optional]
|
| 154 |
+
|
| 155 |
+
### Model Architecture and Objective
|
| 156 |
+
|
| 157 |
+
[More Information Needed]
|
| 158 |
+
|
| 159 |
+
### Compute Infrastructure
|
| 160 |
+
|
| 161 |
+
[More Information Needed]
|
| 162 |
+
|
| 163 |
+
#### Hardware
|
| 164 |
+
|
| 165 |
+
[More Information Needed]
|
| 166 |
+
|
| 167 |
+
#### Software
|
| 168 |
+
|
| 169 |
+
[More Information Needed]
|
| 170 |
+
|
| 171 |
+
## Citation [optional]
|
| 172 |
+
|
| 173 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
+
|
| 175 |
+
**BibTeX:**
|
| 176 |
+
|
| 177 |
+
[More Information Needed]
|
| 178 |
+
|
| 179 |
+
**APA:**
|
| 180 |
+
|
| 181 |
+
[More Information Needed]
|
| 182 |
+
|
| 183 |
+
## Glossary [optional]
|
| 184 |
+
|
| 185 |
+
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 186 |
+
|
| 187 |
+
[More Information Needed]
|
| 188 |
+
|
| 189 |
+
## More Information [optional]
|
| 190 |
+
|
| 191 |
+
[More Information Needed]
|
| 192 |
+
|
| 193 |
+
## Model Card Authors [optional]
|
| 194 |
+
|
| 195 |
+
[More Information Needed]
|
| 196 |
+
|
| 197 |
+
## Model Card Contact
|
| 198 |
+
|
| 199 |
+
[More Information Needed]
|
| 200 |
+
### Framework versions
|
| 201 |
+
|
| 202 |
+
- PEFT 0.12.0
|
checkpoint-113/adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "mistralai/Mistral-Nemo-Instruct-2407",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"q_proj",
|
| 24 |
+
"down_proj",
|
| 25 |
+
"k_proj",
|
| 26 |
+
"o_proj",
|
| 27 |
+
"gate_proj",
|
| 28 |
+
"v_proj",
|
| 29 |
+
"up_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
checkpoint-113/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:52802d6fe841aab344f58af86ae4e93858c4cfa88133b5fa9682f91d0290f6e4
|
| 3 |
+
size 114106856
|
checkpoint-113/optimizer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9ccb2969b63c6ba3c81bd2d8d6260b6a9b782673417dc4260e73c2ad95cd6e93
|
| 3 |
+
size 228536930
|
checkpoint-113/rng_state_0.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:70cc56408014c410353d4dd58ae9b03f4be043f5f800324f66fd8e20e99b840e
|
| 3 |
+
size 15024
|
checkpoint-113/rng_state_1.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:49d1438e98cc9c53a6852464635ce62e9788e61eb3646b73e33813f487c4b6ae
|
| 3 |
+
size 15024
|
checkpoint-113/rng_state_2.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4388add9cec90932f8ff0100d27a0574d98e1bad52ff89d44e31967d2b4fbfde
|
| 3 |
+
size 15024
|
checkpoint-113/rng_state_3.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a705d6dfaae4f2c1b4b2be6b25a6eb521ffae6fcba21cc1531e97b60037ed079
|
| 3 |
+
size 15024
|
checkpoint-113/scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f8fe79dd2d524c3a47ebbac1a1fc359d4473e07185866008e654d72a772ea4f
|
| 3 |
+
size 1064
|
checkpoint-113/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
checkpoint-113/tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0240ce510f08e6c2041724e9043e33be9d251d1e4a4d94eb68cd47b954b61d2
|
| 3 |
+
size 17078292
|
checkpoint-113/tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
checkpoint-113/trainer_state.json
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 1.0,
|
| 5 |
+
"eval_steps": 30,
|
| 6 |
+
"global_step": 113,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.08849557522123894,
|
| 13 |
+
"grad_norm": 0.5378276109695435,
|
| 14 |
+
"learning_rate": 9.808007740920646e-05,
|
| 15 |
+
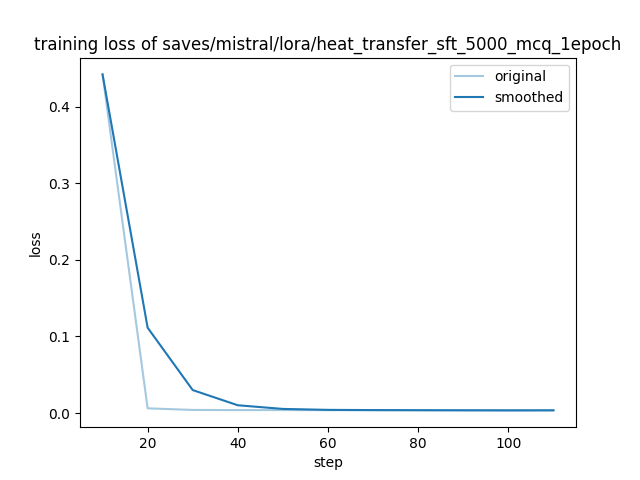
"loss": 0.4426,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.17699115044247787,
|
| 20 |
+
"grad_norm": 0.08370009064674377,
|
| 21 |
+
"learning_rate": 9.246775374701139e-05,
|
| 22 |
+
"loss": 0.0061,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.26548672566371684,
|
| 27 |
+
"grad_norm": 0.010601534508168697,
|
| 28 |
+
"learning_rate": 8.359403809285053e-05,
|
| 29 |
+
"loss": 0.004,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.26548672566371684,
|
| 34 |
+
"eval_loss": 0.0038232754450291395,
|
| 35 |
+
"eval_runtime": 56.0996,
|
| 36 |
+
"eval_samples_per_second": 8.913,
|
| 37 |
+
"eval_steps_per_second": 0.232,
|
| 38 |
+
"step": 30
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 0.35398230088495575,
|
| 42 |
+
"grad_norm": 0.03688598424196243,
|
| 43 |
+
"learning_rate": 7.214040433267198e-05,
|
| 44 |
+
"loss": 0.0038,
|
| 45 |
+
"step": 40
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 0.4424778761061947,
|
| 49 |
+
"grad_norm": 0.013299869373440742,
|
| 50 |
+
"learning_rate": 5.8986456074589404e-05,
|
| 51 |
+
"loss": 0.0038,
|
| 52 |
+
"step": 50
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 0.5309734513274337,
|
| 56 |
+
"grad_norm": 0.08473875373601913,
|
| 57 |
+
"learning_rate": 4.5142375815355706e-05,
|
| 58 |
+
"loss": 0.0037,
|
| 59 |
+
"step": 60
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"epoch": 0.5309734513274337,
|
| 63 |
+
"eval_loss": 0.0035941482055932283,
|
| 64 |
+
"eval_runtime": 56.1024,
|
| 65 |
+
"eval_samples_per_second": 8.912,
|
| 66 |
+
"eval_steps_per_second": 0.232,
|
| 67 |
+
"step": 60
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"epoch": 0.6194690265486725,
|
| 71 |
+
"grad_norm": 0.008843529969453812,
|
| 72 |
+
"learning_rate": 3.167134605250938e-05,
|
| 73 |
+
"loss": 0.0037,
|
| 74 |
+
"step": 70
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 0.7079646017699115,
|
| 78 |
+
"grad_norm": 0.006533902138471603,
|
| 79 |
+
"learning_rate": 1.960790016056801e-05,
|
| 80 |
+
"loss": 0.0036,
|
| 81 |
+
"step": 80
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 0.7964601769911505,
|
| 85 |
+
"grad_norm": 0.06442264467477798,
|
| 86 |
+
"learning_rate": 9.878473431161767e-06,
|
| 87 |
+
"loss": 0.0035,
|
| 88 |
+
"step": 90
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"epoch": 0.7964601769911505,
|
| 92 |
+
"eval_loss": 0.003458332037553191,
|
| 93 |
+
"eval_runtime": 56.0617,
|
| 94 |
+
"eval_samples_per_second": 8.919,
|
| 95 |
+
"eval_steps_per_second": 0.232,
|
| 96 |
+
"step": 90
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"epoch": 0.8849557522123894,
|
| 100 |
+
"grad_norm": 0.06732333451509476,
|
| 101 |
+
"learning_rate": 3.230255711220992e-06,
|
| 102 |
+
"loss": 0.0034,
|
| 103 |
+
"step": 100
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"epoch": 0.9734513274336283,
|
| 107 |
+
"grad_norm": 0.01167540717869997,
|
| 108 |
+
"learning_rate": 1.7380953630678488e-07,
|
| 109 |
+
"loss": 0.0035,
|
| 110 |
+
"step": 110
|
| 111 |
+
}
|
| 112 |
+
],
|
| 113 |
+
"logging_steps": 10,
|
| 114 |
+
"max_steps": 113,
|
| 115 |
+
"num_input_tokens_seen": 0,
|
| 116 |
+
"num_train_epochs": 1,
|
| 117 |
+
"save_steps": 500,
|
| 118 |
+
"stateful_callbacks": {
|
| 119 |
+
"TrainerControl": {
|
| 120 |
+
"args": {
|
| 121 |
+
"should_epoch_stop": false,
|
| 122 |
+
"should_evaluate": false,
|
| 123 |
+
"should_log": false,
|
| 124 |
+
"should_save": true,
|
| 125 |
+
"should_training_stop": true
|
| 126 |
+
},
|
| 127 |
+
"attributes": {}
|
| 128 |
+
}
|
| 129 |
+
},
|
| 130 |
+
"total_flos": 4.179655240942879e+17,
|
| 131 |
+
"train_batch_size": 10,
|
| 132 |
+
"trial_name": null,
|
| 133 |
+
"trial_params": null
|
| 134 |
+
}
|
checkpoint-113/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:01687fe13b6d2acb8aad42cae42ab3c27f8a0188559a24b4698d38478233a06e
|
| 3 |
+
size 5496
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 0.0034613024909049273,
|
| 4 |
+
"eval_runtime": 56.0786,
|
| 5 |
+
"eval_samples_per_second": 8.916,
|
| 6 |
+
"eval_steps_per_second": 0.232
|
| 7 |
+
}
|
runs/Jan15_22-30-44_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736980852.ctua-mistral-sft-heat-333c1-hg6rc.318.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:027cc5a95d57175d717f2e13f62a904c1541920e6ef4eb1e3373ffb5ad4858a2
|
| 3 |
+
size 8756
|
runs/Jan15_22-30-44_ctua-mistral-sft-heat-333c1-hg6rc/events.out.tfevents.1736982668.ctua-mistral-sft-heat-333c1-hg6rc.318.1
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6a08812bf12130bb9fc8b2bd93cf0a6d4b8609dc501e4a3d8bb1155b7417cfdc
|
| 3 |
+
size 354
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0240ce510f08e6c2041724e9043e33be9d251d1e4a4d94eb68cd47b954b61d2
|
| 3 |
+
size 17078292
|
tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"total_flos": 4.179655240942879e+17,
|
| 4 |
+
"train_loss": 0.042722021724072703,
|
| 5 |
+
"train_runtime": 1759.0892,
|
| 6 |
+
"train_samples_per_second": 2.558,
|
| 7 |
+
"train_steps_per_second": 0.064
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 113, "loss": 0.4426, "lr": 9.808007740920646e-05, "epoch": 0.08849557522123894, "percentage": 8.85, "elapsed_time": "0:02:20", "remaining_time": "0:24:02"}
|
| 2 |
+
{"current_steps": 20, "total_steps": 113, "loss": 0.0061, "lr": 9.246775374701139e-05, "epoch": 0.17699115044247787, "percentage": 17.7, "elapsed_time": "0:04:40", "remaining_time": "0:21:44"}
|
| 3 |
+
{"current_steps": 30, "total_steps": 113, "loss": 0.004, "lr": 8.359403809285053e-05, "epoch": 0.26548672566371684, "percentage": 26.55, "elapsed_time": "0:07:01", "remaining_time": "0:19:25"}
|
| 4 |
+
{"current_steps": 30, "total_steps": 113, "eval_loss": 0.0038232754450291395, "epoch": 0.26548672566371684, "percentage": 26.55, "elapsed_time": "0:07:57", "remaining_time": "0:22:00"}
|
| 5 |
+
{"current_steps": 40, "total_steps": 113, "loss": 0.0038, "lr": 7.214040433267198e-05, "epoch": 0.35398230088495575, "percentage": 35.4, "elapsed_time": "0:10:17", "remaining_time": "0:18:47"}
|
| 6 |
+
{"current_steps": 50, "total_steps": 113, "loss": 0.0038, "lr": 5.8986456074589404e-05, "epoch": 0.4424778761061947, "percentage": 44.25, "elapsed_time": "0:12:38", "remaining_time": "0:15:55"}
|
| 7 |
+
{"current_steps": 60, "total_steps": 113, "loss": 0.0037, "lr": 4.5142375815355706e-05, "epoch": 0.5309734513274337, "percentage": 53.1, "elapsed_time": "0:14:58", "remaining_time": "0:13:14"}
|
| 8 |
+
{"current_steps": 60, "total_steps": 113, "eval_loss": 0.0035941482055932283, "epoch": 0.5309734513274337, "percentage": 53.1, "elapsed_time": "0:15:54", "remaining_time": "0:14:03"}
|
| 9 |
+
{"current_steps": 70, "total_steps": 113, "loss": 0.0037, "lr": 3.167134605250938e-05, "epoch": 0.6194690265486725, "percentage": 61.95, "elapsed_time": "0:18:15", "remaining_time": "0:11:12"}
|
| 10 |
+
{"current_steps": 80, "total_steps": 113, "loss": 0.0036, "lr": 1.960790016056801e-05, "epoch": 0.7079646017699115, "percentage": 70.8, "elapsed_time": "0:20:36", "remaining_time": "0:08:29"}
|
| 11 |
+
{"current_steps": 90, "total_steps": 113, "loss": 0.0035, "lr": 9.878473431161767e-06, "epoch": 0.7964601769911505, "percentage": 79.65, "elapsed_time": "0:22:56", "remaining_time": "0:05:51"}
|
| 12 |
+
{"current_steps": 90, "total_steps": 113, "eval_loss": 0.003458332037553191, "epoch": 0.7964601769911505, "percentage": 79.65, "elapsed_time": "0:23:52", "remaining_time": "0:06:06"}
|
| 13 |
+
{"current_steps": 100, "total_steps": 113, "loss": 0.0034, "lr": 3.230255711220992e-06, "epoch": 0.8849557522123894, "percentage": 88.5, "elapsed_time": "0:26:13", "remaining_time": "0:03:24"}
|
| 14 |
+
{"current_steps": 110, "total_steps": 113, "loss": 0.0035, "lr": 1.7380953630678488e-07, "epoch": 0.9734513274336283, "percentage": 97.35, "elapsed_time": "0:28:33", "remaining_time": "0:00:46"}
|
| 15 |
+
{"current_steps": 113, "total_steps": 113, "epoch": 1.0, "percentage": 100.0, "elapsed_time": "0:29:17", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 1.0,
|
| 5 |
+
"eval_steps": 30,
|
| 6 |
+
"global_step": 113,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.08849557522123894,
|
| 13 |
+
"grad_norm": 0.5378276109695435,
|
| 14 |
+
"learning_rate": 9.808007740920646e-05,
|
| 15 |
+
"loss": 0.4426,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.17699115044247787,
|
| 20 |
+
"grad_norm": 0.08370009064674377,
|
| 21 |
+
"learning_rate": 9.246775374701139e-05,
|
| 22 |
+
"loss": 0.0061,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.26548672566371684,
|
| 27 |
+
"grad_norm": 0.010601534508168697,
|
| 28 |
+
"learning_rate": 8.359403809285053e-05,
|
| 29 |
+
"loss": 0.004,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.26548672566371684,
|
| 34 |
+
"eval_loss": 0.0038232754450291395,
|
| 35 |
+
"eval_runtime": 56.0996,
|
| 36 |
+
"eval_samples_per_second": 8.913,
|
| 37 |
+
"eval_steps_per_second": 0.232,
|
| 38 |
+
"step": 30
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 0.35398230088495575,
|
| 42 |
+
"grad_norm": 0.03688598424196243,
|
| 43 |
+
"learning_rate": 7.214040433267198e-05,
|
| 44 |
+
"loss": 0.0038,
|
| 45 |
+
"step": 40
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 0.4424778761061947,
|
| 49 |
+
"grad_norm": 0.013299869373440742,
|
| 50 |
+
"learning_rate": 5.8986456074589404e-05,
|
| 51 |
+
"loss": 0.0038,
|
| 52 |
+
"step": 50
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 0.5309734513274337,
|
| 56 |
+
"grad_norm": 0.08473875373601913,
|
| 57 |
+
"learning_rate": 4.5142375815355706e-05,
|
| 58 |
+
"loss": 0.0037,
|
| 59 |
+
"step": 60
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"epoch": 0.5309734513274337,
|
| 63 |
+
"eval_loss": 0.0035941482055932283,
|
| 64 |
+
"eval_runtime": 56.1024,
|
| 65 |
+
"eval_samples_per_second": 8.912,
|
| 66 |
+
"eval_steps_per_second": 0.232,
|
| 67 |
+
"step": 60
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"epoch": 0.6194690265486725,
|
| 71 |
+
"grad_norm": 0.008843529969453812,
|
| 72 |
+
"learning_rate": 3.167134605250938e-05,
|
| 73 |
+
"loss": 0.0037,
|
| 74 |
+
"step": 70
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 0.7079646017699115,
|
| 78 |
+
"grad_norm": 0.006533902138471603,
|
| 79 |
+
"learning_rate": 1.960790016056801e-05,
|
| 80 |
+
"loss": 0.0036,
|
| 81 |
+
"step": 80
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 0.7964601769911505,
|
| 85 |
+
"grad_norm": 0.06442264467477798,
|
| 86 |
+
"learning_rate": 9.878473431161767e-06,
|
| 87 |
+
"loss": 0.0035,
|
| 88 |
+
"step": 90
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"epoch": 0.7964601769911505,
|
| 92 |
+
"eval_loss": 0.003458332037553191,
|
| 93 |
+
"eval_runtime": 56.0617,
|
| 94 |
+
"eval_samples_per_second": 8.919,
|
| 95 |
+
"eval_steps_per_second": 0.232,
|
| 96 |
+
"step": 90
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"epoch": 0.8849557522123894,
|
| 100 |
+
"grad_norm": 0.06732333451509476,
|
| 101 |
+
"learning_rate": 3.230255711220992e-06,
|
| 102 |
+
"loss": 0.0034,
|
| 103 |
+
"step": 100
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"epoch": 0.9734513274336283,
|
| 107 |
+
"grad_norm": 0.01167540717869997,
|
| 108 |
+
"learning_rate": 1.7380953630678488e-07,
|
| 109 |
+
"loss": 0.0035,
|
| 110 |
+
"step": 110
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"epoch": 1.0,
|
| 114 |
+
"step": 113,
|
| 115 |
+
"total_flos": 4.179655240942879e+17,
|
| 116 |
+
"train_loss": 0.042722021724072703,
|
| 117 |
+
"train_runtime": 1759.0892,
|
| 118 |
+
"train_samples_per_second": 2.558,
|
| 119 |
+
"train_steps_per_second": 0.064
|
| 120 |
+
}
|
| 121 |
+
],
|
| 122 |
+
"logging_steps": 10,
|
| 123 |
+
"max_steps": 113,
|
| 124 |
+
"num_input_tokens_seen": 0,
|
| 125 |
+
"num_train_epochs": 1,
|
| 126 |
+
"save_steps": 500,
|
| 127 |
+
"stateful_callbacks": {
|
| 128 |
+
"TrainerControl": {
|
| 129 |
+
"args": {
|
| 130 |
+
"should_epoch_stop": false,
|
| 131 |
+
"should_evaluate": false,
|
| 132 |
+
"should_log": false,
|
| 133 |
+
"should_save": true,
|
| 134 |
+
"should_training_stop": true
|
| 135 |
+
},
|
| 136 |
+
"attributes": {}
|
| 137 |
+
}
|
| 138 |
+
},
|
| 139 |
+
"total_flos": 4.179655240942879e+17,
|
| 140 |
+
"train_batch_size": 10,
|
| 141 |
+
"trial_name": null,
|
| 142 |
+
"trial_params": null
|
| 143 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:01687fe13b6d2acb8aad42cae42ab3c27f8a0188559a24b4698d38478233a06e
|
| 3 |
+
size 5496
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|