
Commit ·
4afa049
1
Parent(s): 2bfdac7
Upload folder using huggingface_hub
Browse files- .gitattributes +30 -35
- README.md +339 -0
- config.json +28 -0
- generation_config.json +14 -0
- images/1280X12180.PNG +3 -0
- images/20240220-164216.jpg +3 -0
- images/61.png +0 -0
- images/62.png +0 -0
- images/63.png +0 -0
- images/64.png +3 -0
- images/640 3.png +3 -0
- images/640 4.png +3 -0
- images/640 5.png +0 -0
- images/640 7.png +3 -0
- images/640 8.png +0 -0
- images/640 9.png +0 -0
- images/640.png +0 -0
- images/6402.png +3 -0
- images/6406.png +3 -0
- images/641.png +0 -0
- images/730deaf7-f202-4dd3-99e1-f659106f02fa.png +3 -0
- images/c93a1385-6c8b-4e88-80b8-965ca366b8d6.png +3 -0
- images/dmsj.png +3 -0
- images/gjsy.png +3 -0
- images/gjsy1.png +3 -0
- images/image-1.png +0 -0
- images/image-2.png +3 -0
- images/image-3.png +3 -0
- images/image-4.png +3 -0
- images/image.png +0 -0
- images/log1.png +3 -0
- images/log2.png +3 -0
- images/nx1.png +0 -0
- images/nx2.png +0 -0
- images/nx3.png +3 -0
- images/st1.png +3 -0
- images/st2.png +3 -0
- images/st3.png +3 -0
- images/st4.png +3 -0
- images/version.PNG +3 -0
- model-00001-of-00006.safetensors +3 -0
- model-00002-of-00006.safetensors +3 -0
- model-00003-of-00006.safetensors +3 -0
- model-00004-of-00006.safetensors +3 -0
- model-00005-of-00006.safetensors +3 -0
- model-00006-of-00006.safetensors +3 -0
- model.safetensors.index.json +586 -0
- tokenization_baichuan.py +232 -0
- tokenizer.json +0 -0
- tokenizer_config.json +207 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,30 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
images/1280X12180.PNG filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
images/20240220-164216.jpg filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
images/64.png filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
images/640[[:space:]]3.png filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
images/640[[:space:]]4.png filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
images/640[[:space:]]7.png filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
images/6402.png filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
images/6406.png filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
images/730deaf7-f202-4dd3-99e1-f659106f02fa.png filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
images/c93a1385-6c8b-4e88-80b8-965ca366b8d6.png filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
images/dmsj.png filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
images/gjsy.png filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
images/gjsy1.png filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
images/image-2.png filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
images/image-3.png filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
images/image-4.png filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
images/log1.png filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
images/log2.png filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
images/nx3.png filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
images/st1.png filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
images/st2.png filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
images/st3.png filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
images/st4.png filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
images/version.PNG filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
model-00001-of-00006.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
model-00002-of-00006.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
model-00003-of-00006.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
model-00004-of-00006.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
model-00005-of-00006.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
model-00006-of-00006.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
README.md
ADDED
|
@@ -0,0 +1,339 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
base_model:
|
| 7 |
+
- Qwen/Qwen2.5-14B-Instruct
|
| 8 |
+
tags:
|
| 9 |
+
- cybersecurity
|
| 10 |
+
- security
|
| 11 |
+
- network-security
|
| 12 |
+
---
|
| 13 |
+
# 🌐 SecGPT:全球首个网络安全开源大模型
|
| 14 |
+
|
| 15 |
+
## 🔍 模型简介
|
| 16 |
+
|
| 17 |
+
**SecGPT** 是由 **云起无垠** 于 2023 年正式推出的开源大模型,专为网络安全场景打造,旨在以人工智能技术全面提升安全防护效率与效果。
|
| 18 |
+
|
| 19 |
+
> ✅ 我们的愿景:推动网络安全智能化,为社会构建更安全的数字空间
|
| 20 |
+
> 🚀 我们的使命:让每一家企业,都能拥有一个“懂安全”的智能助手
|
| 21 |
+
|
| 22 |
+
SecGPT 融合了自然语言理解、代码生成、安全知识推理等核心能力,已成功落地多个关键安全任务场景:
|
| 23 |
+
|
| 24 |
+
- **🛠 漏洞分析**:理解漏洞成因、评估影响范围、生成修复建议
|
| 25 |
+
- **🧭 日志与流量溯源**:还原攻击路径、分析攻击链,辅助事件复盘
|
| 26 |
+
- **⚠️ 异常检测**:识别潜在威胁,提升安全感知与响应能力
|
| 27 |
+
- **🎯 攻防推理**:服务于红队演练、蓝队分析,支撑实战决策
|
| 28 |
+
- **📜 命令解析**:分析攻击脚本,识别意图与高危操作
|
| 29 |
+
- **💬 安全知识问答**:团队“即问即答”的知识引擎
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## 🔧 最新动态
|
| 34 |
+
|
| 35 |
+
- **2025年4月**:SecGPT V2.0 发布,全面升级安全理解与任务执行能力
|
| 36 |
+
- **2024年3月**:轻量化版本 SecGPT-Mini 正式开源,可在 CPU 上高效运行
|
| 37 |
+
- **2023年12月**:SecGPT 正式发布,成为全球首个开源网络安全大模型
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## 📂 开源资源
|
| 42 |
+
|
| 43 |
+
- ##### 模型源码与文档:
|
| 44 |
+
|
| 45 |
+
- https://github.com/Clouditera/secgpt
|
| 46 |
+
|
| 47 |
+
- **数据集下载地址:**
|
| 48 |
+
- https://huggingface.co/datasets/clouditera/security-paper-datasets
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## 🔧 模型部署
|
| 54 |
+
|
| 55 |
+
SecGPT 支持通过 vLLM 高性能推理框架部署,适用于 **低延迟、高并发、大吞吐量** 的安全模型服务场景。
|
| 56 |
+
|
| 57 |
+
环境准备与服务启动:
|
| 58 |
+
|
| 59 |
+
```shell
|
| 60 |
+
# 创建 Python 环境(建议 Python 3.10+)
|
| 61 |
+
conda create -n secgpt-vllm python=3.10 -y
|
| 62 |
+
conda activate secgpt-vllm
|
| 63 |
+
|
| 64 |
+
# 安装 vLLM(需具备 PyTorch + CUDA)
|
| 65 |
+
pip install --upgrade pip
|
| 66 |
+
pip install vllm
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
# 启动server 服务
|
| 70 |
+
CUDA_VISIBLE_DEVICES= xxx(GPU index) \
|
| 71 |
+
vllm serve ./secgpt \
|
| 72 |
+
--tokenizer ./secgpt \
|
| 73 |
+
--tensor-parallel-size 4 \
|
| 74 |
+
--max-model-len 32768 \
|
| 75 |
+
--gpu-memory-utilization 0.9 \
|
| 76 |
+
--dtype bfloat16 \
|
| 77 |
+
|
| 78 |
+
# 示例请求
|
| 79 |
+
curl http://localhost:8000/v1/chat/completions \
|
| 80 |
+
-H "Content-Type: application/json" \
|
| 81 |
+
-d '{
|
| 82 |
+
"model": "secgpt",
|
| 83 |
+
"messages": [{"role": "user", "content": "什么是 XSS 攻击?"}],
|
| 84 |
+
"temperature": 0.7
|
| 85 |
+
}'
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
## 本轮更新亮点:
|
| 93 |
+
|
| 94 |
+
### 1. 更强的基座能力:通用+安全深度融合
|
| 95 |
+
|
| 96 |
+
我们基于 **Qwen2.5-Instruct 系列** 与 **DeepSeek-R1 系列** 模型,结合自建安全任务集与安全知识库, 在 **8台A100 GPU** 集群上持续训练一周以上,完成大规模预训练 + 指令微调 + 强化学习, 显著提升模型在安全场景中的**理解、推理与响应能力**。
|
| 97 |
+
|
| 98 |
+
下图展示了一次训练过程中各关键指标的演化轨迹:
|
| 99 |
+
|
| 100 |
+
- **训练与验证损失(train/loss 与 eval/loss)**:二者均呈现出平稳下降趋势,说明模型在训练集与验证集上均持续收敛,未出现过拟合迹象。
|
| 101 |
+
- **学习率曲线(train/learning_rate)**:采用典型的 Warmup + 衰减策略,有效提升了早期训练的稳定性与收敛速度。
|
| 102 |
+
- **梯度范数(train/grad_norm)**:整体波动平稳,仅在少数步数存在轻微尖峰,未出现梯度爆炸或消失,表明训练过程健康稳定。
|
| 103 |
+
- **评估表现**:`eval/runtime` 与 `eval/samples_per_second` 波动范围小,说明在评估过程中系统资源使用高效,推理吞吐量稳定。
|
| 104 |
+
- **其他指标**如训练轮数(train/epoch)、输入 token 数量(train/num_input_tokens_seen)等也表明训练过程如期进行,达成预期计划。
|
| 105 |
+
|
| 106 |
+

|
| 107 |
+
|
| 108 |
+
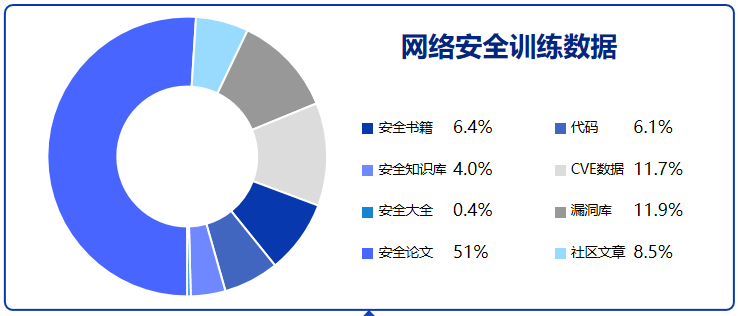
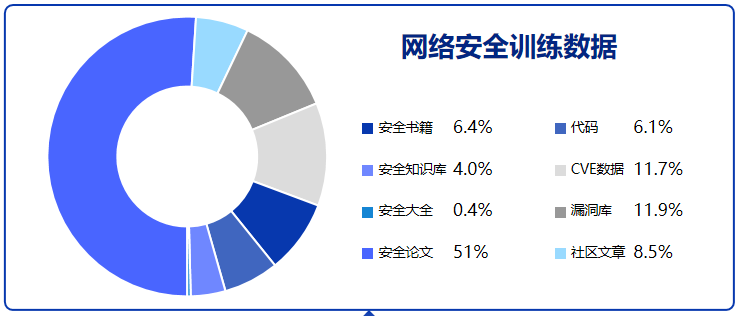
### 2. 更大的高质量安全语料库:私有 + 公共数据双轮驱动
|
| 109 |
+
|
| 110 |
+
我们已构建了一个超大规模、结构完备的网络安全语料库,总量超过 **5TB**、共计 **106,721 个原始文件**,其中超过 **40% 内容为人工精选与结构化处理**。私有数据部分系统整合了具备 **70+ 字段 / 14 类结构标签体系** 的安全数据资源,经过统一清洗、语义标注与重构,构建出 **数百亿 Tokens 级**的高质量语料,为大模型深度推理能力提供坚实支撑。
|
| 111 |
+
|
| 112 |
+
下图展示了该语料库的构成维度,整体采集逻辑遵循“**理论支撑 — 实战对抗 — 应用落地**”三层结构体系:
|
| 113 |
+
|
| 114 |
+
- **理论支撑**:涵盖法律法规、学术论文、行业报告等权威资料,为模型提供稳固的知识基座;
|
| 115 |
+
- **实战对抗**:包括漏洞详情、CTF题库、日志流量、恶意样本与逆向分析等数据,提升模型对真实攻击行为的识别与追踪能力;
|
| 116 |
+
- **应用落地**:涵盖安全社区博客、教育培训资料、安全知识图谱与自动化策略,增强模型在安全运营、辅助决策等场景中的适配能力。
|
| 117 |
+
|
| 118 |
+

|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
## 🧪 模型评测与能力分析
|
| 123 |
+
|
| 124 |
+
### 1. 模型能力评测:全面指标跃升,实战智能初现
|
| 125 |
+
|
| 126 |
+
为全面评估 SecGPT 的安全实战能力,我们构建了一套覆盖**安全证书问答、安全通识、编程能力、知识理解与推理能力**的综合评估体系,主要采用以下标准化数据集:CISSP、CS-EVAL、CEVAL、GSM8K、BBH。
|
| 127 |
+
|
| 128 |
+
| **评测集名称** | **简要说明** | **参考链接** |
|
| 129 |
+
| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
| 130 |
+
| **CISSP** | 权威信息安全认证体系,考察模型在安全管理、访问控制、风险治理等领域的专业知识覆盖度与答题准确率,适用于评估模型在通用信息安全领域的掌握程度。 | [ISC² 官方网站](https://www.isc2.org/Certifications/CISSP) [认证考试指南](https://web.lib.xjtu.edu.cn/info/1117/6461.htm) |
|
| 131 |
+
| **CS-Eval** | 面向网络安全任务的大模型能力综合评测集,覆盖 11 个网络安全主类、42 个子类,共计 4369 道题目,包含选择题、判断题、知识抽取等题型,兼顾知识性与实战性,用于评估模型的安全通识与任务执行能力。 | [ModelScope 数据集](https://modelscope.cn/datasets/cseval/cs-eval/) [论文介绍 (arXiv)](https://arxiv.org/abs/2411.16239) |
|
| 132 |
+
| **C-Eval** | 中文能力评估。由上海交通大学、清华大学和爱丁堡大学的研究人员在2023年5月联合推出。包含13948个多项选择题,涵盖了52个不同的学科和四个难度级别。 | [论文链接 (arXiv)](https://arxiv.org/abs/2305.08322) [CSDN 实践介绍](https://blog.csdn.net/2401_85343303/article/details/139698577) |
|
| 133 |
+
| **GSM8K** | 解决数学问题的能力。Google开发的一个数学问题求解数据集,包含大约8,000个高中到大学水平的数学问题。 | [GSM8K ](https://github.com/openai/grade-school-math) [GitHub](https://github.com/openai/grade-school-math) |
|
| 134 |
+
| **BBH** | 复杂语言理解能力。由Google、斯坦福等研究人员开发的数据集,包含大量复杂语言理解任务的集合,可能包含需要深度推理、常识运用或复杂认知技能的任务。 | [论文链接 (arXiv)](https://arxiv.org/abs/2206.04615) |
|
| 135 |
+
|
| 136 |
+
在与原始模型 SecGPT-mini 的对比中,训练后的模型在所有指标上均实现大幅跃升,具体如下:
|
| 137 |
+
|
| 138 |
+
#### 1.1 模型纵向评测对比
|
| 139 |
+
|
| 140 |
+
| **模型版本** | **CISSP** | **CS-EVAL** | **CEVAL** | **GSM8K** | **BBH** |
|
| 141 |
+
| --------------- | ------------ | ------------- | ------------ | ------------ | ------------ |
|
| 142 |
+
| **SecGPT-mini** | 25.67 | 39.64 | 37.50 | 3.87 | 21.80 |
|
| 143 |
+
| **SecGPT-1.5B** | 71.09🔺+45.42 | 81.53 🔺+41.89 | 53.5 🔺+16.00 | 57.47🔺+53.60 | 45.17🔺+23.37 |
|
| 144 |
+
| **SecGPT-7B** | 78.23🔺+52.97 | 85.12 🔺+45.48 | 72.89🔺+35.39 | 76.88🔺+73.01 | 67.08🔺+45.28 |
|
| 145 |
+
| **SecGPT-14B** | 77.37🔺+51.70 | 86.12 🔺+46.48 | 59.45🔺+29.95 | 88.25🔺+84.38 | 75.90🔺+54.10 |
|
| 146 |
+
|
| 147 |
+
📈 **能力跃升解读:**
|
| 148 |
+
|
| 149 |
+
- **mini → 1.5B**:具备“能答对”的基础问答能力,适配中低复杂度任务;
|
| 150 |
+
- **1.5B → 7B**:推理深度、泛化能力显著增强,能理解任务意图并构建较为完整的解决路径;
|
| 151 |
+
- **7B → 14B**:能力跃迁至“类专家”级,能够处理高复杂度推理、安全策略制定等高阶任务。
|
| 152 |
+
|
| 153 |
+
#### 1.2 模型横向评测对比
|
| 154 |
+
|
| 155 |
+
相较于基础模型 Qwen2.5-Instruct,SecGPT 在所有评测指标上均实现实质性超越,反映出我们在数据构建、微调范式、安全任务精调机制上的整体优化成效:
|
| 156 |
+
|
| 157 |
+
| 模型版本 | **CISSP** ↑ | **CS-EVAL ↑** | **CEVAL ↑** | **GSM8K ↑** | **BBH ↑** |
|
| 158 |
+
| ---------------- | ------------ | -------------- | ----------- | ----------- | --------- |
|
| 159 |
+
| **Qwen2.5-1.5B** | 52.97 | 71.66 | 59.91 | 61.03 | 43.44 |
|
| 160 |
+
| **SecGPT-1.5B** | 71.09 | 81.53 | 53.5 | 57.47 | 45.17 |
|
| 161 |
+
| **Qwen2.5-7B** | 66.30 | 84.66 | 74.97 | 80.36 | 71.20 |
|
| 162 |
+
| **SecGPT-7B** | 78.23 | 85.12 | 72.89 | 76.88 | 67.08 |
|
| 163 |
+
| **Qwen2.5-14B** | 71.09 | 86.22 | 68.57 | 90.03 | 78.25 |
|
| 164 |
+
| **SecGPT-14B** | 77.37 | 86.12 | 59.45 | 88.25 | 75.90 |
|
| 165 |
+
|
| 166 |
+
💡 **洞察亮点:**
|
| 167 |
+
|
| 168 |
+
- 在 CISSP 和 CS-EVAL 等安全类数据集上,SecGPT 在所有参数规模下均表现优于 Qwen2.5 同规格版本;
|
| 169 |
+
- 表明我们构建的安全任务指令集与精调策略已显著提升模型的实��应用能力与专业问答深度。
|
| 170 |
+
|
| 171 |
+
### 2. 安全能力提升:更全、更准、更专业
|
| 172 |
+
|
| 173 |
+
本轮升级中,SecGPT 在安全知识问答方面完成了从**信息整合**到**逻辑输出**的能力跃迁,具体体现在:
|
| 174 |
+
|
| 175 |
+
- **知识覆盖更全面**:引入了涵盖法律法规、攻击战术、逆向分析等14类安全知识领域的结构化语料;
|
| 176 |
+
- **答案生成更精准**:通过多轮对话控制与语义优化技术,提升了问答对齐率与上下文记忆稳定性;
|
| 177 |
+
- **推理能力更突出**:具备多段知识联结与复合逻辑推演能力,能完成如攻击链分析、威胁研判等复杂任务。
|
| 178 |
+
|
| 179 |
+
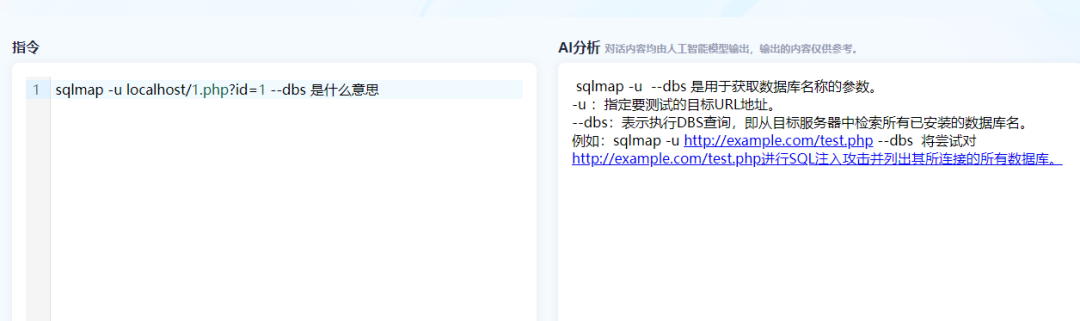
#### 2.1 渗透测试场景能力:
|
| 180 |
+
|
| 181 |
+
SecGPT 能够模拟渗透攻击流程,从信息收集、漏洞利用到提权横向,具备关键工具命令分析、Payload 构造、利用链生成等能力。
|
| 182 |
+
|
| 183 |
+

|
| 184 |
+
|
| 185 |
+

|
| 186 |
+
|
| 187 |
+

|
| 188 |
+
|
| 189 |
+

|
| 190 |
+
|
| 191 |
+
#### 2.2 日志分析和流量分析能力
|
| 192 |
+
|
| 193 |
+
在安全日志与网络流量场景下,SecGPT 能自动识别异常事件、构建攻击链图谱、抽取关键 IOC(Indicator of Compromise),辅助完成事件溯源与告警分类。
|
| 194 |
+
|
| 195 |
+

|
| 196 |
+
|
| 197 |
+

|
| 198 |
+
|
| 199 |
+
#### 2.3 逆向分析能力
|
| 200 |
+
|
| 201 |
+
基于对反汇编、API 调用序列、加壳行为等低层数据的理解,SecGPT 能辅助完成恶意样本的静态分析、特征提取与家族归类,具备一定的逆向辅助解读能力。
|
| 202 |
+
|
| 203 |
+

|
| 204 |
+
|
| 205 |
+

|
| 206 |
+
|
| 207 |
+

|
| 208 |
+
|
| 209 |
+
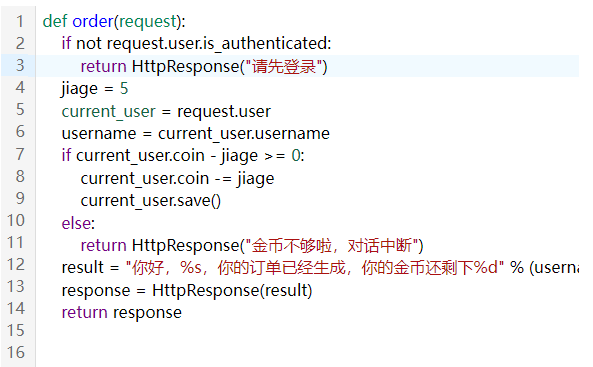
#### 2.4 代码审计能力
|
| 210 |
+
|
| 211 |
+
```typescript
|
| 212 |
+
import java.util.*;
|
| 213 |
+
import java.util.stream.Collectors;
|
| 214 |
+
|
| 215 |
+
public class AverageCalculator {
|
| 216 |
+
|
| 217 |
+
public static double calculateAverage(Object input, boolean strict) {
|
| 218 |
+
if (strict) {
|
| 219 |
+
System.out.println("Running in STRICT mode");
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
@SuppressWarnings("unchecked")
|
| 223 |
+
List<Number> numbers = (List<Number>) input;
|
| 224 |
+
double total = 0;
|
| 225 |
+
for (Number num : numbers) {
|
| 226 |
+
total += num.doubleValue();
|
| 227 |
+
}
|
| 228 |
+
return total / numbers.size();
|
| 229 |
+
} else {
|
| 230 |
+
System.out.println("Running in SAFE mode");
|
| 231 |
+
|
| 232 |
+
List<Double> parsed = parseInputSafe(input);
|
| 233 |
+
double total = parsed.stream().mapToDouble(Double::doubleValue).sum();
|
| 234 |
+
return total / parsed.size();
|
| 235 |
+
}
|
| 236 |
+
}
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
public static List<Double> parseInputSafe(Object input) {
|
| 240 |
+
List<Double> result = new ArrayList<>();
|
| 241 |
+
|
| 242 |
+
if (input instanceof String) {
|
| 243 |
+
String s = (String) input;
|
| 244 |
+
if (!s.matches("\\d+")) {
|
| 245 |
+
throw new IllegalArgumentException("String must contain only digits.");
|
| 246 |
+
}
|
| 247 |
+
for (char c : s.toCharArray()) {
|
| 248 |
+
result.add(Double.parseDouble(String.valueOf(c)));
|
| 249 |
+
}
|
| 250 |
+
} else if (input instanceof List<?>) {
|
| 251 |
+
for (Object obj : (List<?>) input) {
|
| 252 |
+
try {
|
| 253 |
+
result.add(Double.parseDouble(obj.toString()));
|
| 254 |
+
} catch (NumberFormatException e) {
|
| 255 |
+
throw new IllegalArgumentException("Invalid element in list: " + obj);
|
| 256 |
+
}
|
| 257 |
+
}
|
| 258 |
+
} else {
|
| 259 |
+
throw new IllegalArgumentException("Unsupported input type: " + input.getClass());
|
| 260 |
+
}
|
| 261 |
+
|
| 262 |
+
return result;
|
| 263 |
+
}
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
public static void main(String[] args) {
|
| 267 |
+
List<TestCase> testCases = Arrays.asList(
|
| 268 |
+
new TestCase("12345", false),
|
| 269 |
+
new TestCase("12345", true),
|
| 270 |
+
new TestCase(Arrays.asList(1, 2, "3", "4"), false),
|
| 271 |
+
new TestCase(Arrays.asList(1, 2, 3, "four"), false),
|
| 272 |
+
new TestCase(Arrays.asList(1, 2, 3, "four"), true)
|
| 273 |
+
);
|
| 274 |
+
|
| 275 |
+
for (int i = 0; i < testCases.size(); i++) {
|
| 276 |
+
TestCase tc = testCases.get(i);
|
| 277 |
+
System.out.println("\n--- Test Case " + (i + 1) + " | strict=" + tc.strict + " ---");
|
| 278 |
+
try {
|
| 279 |
+
double avg = calculateAverage(tc.input, tc.strict);
|
| 280 |
+
System.out.println("✅ Average: " + avg);
|
| 281 |
+
} catch (Exception e) {
|
| 282 |
+
System.out.println("❌ Error: " + e.getMessage());
|
| 283 |
+
}
|
| 284 |
+
}
|
| 285 |
+
}
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
static class TestCase {
|
| 289 |
+
Object input;
|
| 290 |
+
boolean strict;
|
| 291 |
+
|
| 292 |
+
TestCase(Object input, boolean strict) {
|
| 293 |
+
this.input = input;
|
| 294 |
+
this.strict = strict;
|
| 295 |
+
}
|
| 296 |
+
}
|
| 297 |
+
}
|
| 298 |
+
```
|
| 299 |
+
|
| 300 |
+

|
| 301 |
+
|
| 302 |
+
#### 2.5 工具使用
|
| 303 |
+
|
| 304 |
+

|
| 305 |
+
|
| 306 |
+

|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
## 📮 联系我们
|
| 315 |
+
<div align=center><img src="images/20240220-164216.jpg" alt="" width="40%" height="40%">
|
| 316 |
+
</div>
|
| 317 |
+
SecGPT 是一个面向网络安全领域的大模型开源项目,我们相信开放、协作、共享的力量,能够不断推动行业智能化进程。
|
| 318 |
+
|
| 319 |
+
我们诚挚邀请全球的安全研究者、工程师、爱好者共同参与 SecGPT 的建设与优化:
|
| 320 |
+
|
| 321 |
+
- 🧠 提出使用建议或功能需求
|
| 322 |
+
- 🐞 反馈问题并提交 Issue
|
| 323 |
+
- 💻 贡献代码与安全任务数据集
|
| 324 |
+
- 📢 参与使用经验交流与最佳实践分享
|
| 325 |
+
|
| 326 |
+
📬 若您对模型有任何疑问或合作意向,欢迎通过 GitHub 参与贡献或联系云起无垠团队。我们期待与更多志同道合的伙伴一起,共建“真正懂安全”的 AI 系统。
|
| 327 |
+
|
| 328 |
+
## ⭐ Star History
|
| 329 |
+
|
| 330 |
+
[](https://star-history.com/#Clouditera/secgpt&Date)
|
| 331 |
+
|
| 332 |
+
## ⚠️ 免责声明
|
| 333 |
+
|
| 334 |
+
在使用 SecGPT 时,请您注意以下事项:
|
| 335 |
+
|
| 336 |
+
- 本项目为研究与交流目的所构建,输出内容可能受限于模型训练数据的覆盖范围;
|
| 337 |
+
- 用户在使用模型过程中,应自行判断其输出的正确性与适用性;
|
| 338 |
+
- 若您计划将本模型用于 **公开发布或商业化部署**,请务必明确承担相关法律和合规责任;
|
| 339 |
+
- 本项目的开发者对因使用本模型(包括但不限于模型本身、训练数据、输出内容)所可能产生的任何直接或间接损害概不负责。
|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen2ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 151643,
|
| 7 |
+
"eos_token_id": 151645,
|
| 8 |
+
"hidden_act": "silu",
|
| 9 |
+
"hidden_size": 5120,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 13824,
|
| 12 |
+
"max_position_embeddings": 32768,
|
| 13 |
+
"max_window_layers": 70,
|
| 14 |
+
"model_type": "qwen2",
|
| 15 |
+
"num_attention_heads": 40,
|
| 16 |
+
"num_hidden_layers": 48,
|
| 17 |
+
"num_key_value_heads": 8,
|
| 18 |
+
"rms_norm_eps": 1e-06,
|
| 19 |
+
"rope_scaling": null,
|
| 20 |
+
"rope_theta": 1000000.0,
|
| 21 |
+
"sliding_window": 131072,
|
| 22 |
+
"tie_word_embeddings": false,
|
| 23 |
+
"torch_dtype": "float16",
|
| 24 |
+
"transformers_version": "4.50.0",
|
| 25 |
+
"use_cache": true,
|
| 26 |
+
"use_sliding_window": false,
|
| 27 |
+
"vocab_size": 152064
|
| 28 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151643,
|
| 9 |
+
"repetition_penalty": 1.05,
|
| 10 |
+
"temperature": 0.7,
|
| 11 |
+
"top_k": 20,
|
| 12 |
+
"top_p": 0.8,
|
| 13 |
+
"transformers_version": "4.50.0"
|
| 14 |
+
}
|
images/1280X12180.PNG
ADDED

|
Git LFS Details
|
images/20240220-164216.jpg
ADDED

|
Git LFS Details
|
images/61.png
ADDED

|
images/62.png
ADDED

|
images/63.png
ADDED

|
images/64.png
ADDED

|
Git LFS Details
|
images/640 3.png
ADDED

|
Git LFS Details
|
images/640 4.png
ADDED

|
Git LFS Details
|
images/640 5.png
ADDED
|
images/640 7.png
ADDED

|
Git LFS Details
|
images/640 8.png
ADDED
|
images/640 9.png
ADDED

|
images/640.png
ADDED
|
images/6402.png
ADDED

|
Git LFS Details
|
images/6406.png
ADDED

|
Git LFS Details
|
images/641.png
ADDED

|
images/730deaf7-f202-4dd3-99e1-f659106f02fa.png
ADDED

|
Git LFS Details
|
images/c93a1385-6c8b-4e88-80b8-965ca366b8d6.png
ADDED

|
Git LFS Details
|
images/dmsj.png
ADDED

|
Git LFS Details
|
images/gjsy.png
ADDED

|
Git LFS Details
|
images/gjsy1.png
ADDED

|
Git LFS Details
|
images/image-1.png
ADDED

|
images/image-2.png
ADDED

|
Git LFS Details
|
images/image-3.png
ADDED

|
Git LFS Details
|
images/image-4.png
ADDED

|
Git LFS Details
|
images/image.png
ADDED
|
images/log1.png
ADDED

|
Git LFS Details
|
images/log2.png
ADDED

|
Git LFS Details
|
images/nx1.png
ADDED
|
images/nx2.png
ADDED

|
images/nx3.png
ADDED

|
Git LFS Details
|
images/st1.png
ADDED

|
Git LFS Details
|
images/st2.png
ADDED

|
Git LFS Details
|
images/st3.png
ADDED

|
Git LFS Details
|
images/st4.png
ADDED

|
Git LFS Details
|
images/version.PNG
ADDED

|
Git LFS Details
|
model-00001-of-00006.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c8bb2a21480ef119bc464164162e8a0d1cff22b03941856e8f685ea8c3ea0d7
|
| 3 |
+
size 4986211200
|
model-00002-of-00006.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f50351e6c1c5ed15db61afc99cbbbc67dc67025375af4d1310af63f0b0f8792
|
| 3 |
+
size 4954847240
|
model-00003-of-00006.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:977276a98feb09a8f4717415d4764a32094fdcd237d68ae0e87c0bfe487be0ae
|
| 3 |
+
size 4954847280
|
model-00004-of-00006.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3300add0c300b58db0571a6467c4b03e5e8025a19858081c7844d500a67a6635
|
| 3 |
+
size 4954847280
|
model-00005-of-00006.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8276d31683b896302d86b0e0ea60b954ada7d3902aacee1145ebf33ace943adf
|
| 3 |
+
size 4954847280
|
model-00006-of-00006.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bcd6d61bb95c4591236e3fbf1875abca9d11429136096553eb27996eeb17496a
|
| 3 |
+
size 4734533096
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,586 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 29540067328
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00006-of-00006.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00006.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 20 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 21 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 22 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 23 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 24 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 27 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 28 |
+
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 29 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 30 |
+
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 31 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 32 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 33 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 34 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 35 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 36 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 37 |
+
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 38 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 39 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 40 |
+
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 41 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 42 |
+
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 43 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 44 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 45 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 46 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 47 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 48 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 49 |
+
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 50 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 51 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 52 |
+
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 53 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 54 |
+
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 55 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 56 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 57 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 58 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 59 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 60 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 61 |
+
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 62 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 63 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 64 |
+
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 65 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 66 |
+
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 67 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 68 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 69 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 70 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 71 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 72 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 73 |
+
"model.layers.13.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 74 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 75 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 76 |
+
"model.layers.13.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 77 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 78 |
+
"model.layers.13.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 79 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 80 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 81 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 82 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 83 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 84 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 85 |
+
"model.layers.14.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 86 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 87 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 88 |
+
"model.layers.14.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 89 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 90 |
+
"model.layers.14.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 91 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 92 |
+
"model.layers.15.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 93 |
+
"model.layers.15.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 94 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 95 |
+
"model.layers.15.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 96 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 97 |
+
"model.layers.15.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 98 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 99 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 100 |
+
"model.layers.15.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 101 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 102 |
+
"model.layers.15.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 103 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 104 |
+
"model.layers.16.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 105 |
+
"model.layers.16.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 106 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 107 |
+
"model.layers.16.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 108 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 109 |
+
"model.layers.16.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 110 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 111 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 112 |
+
"model.layers.16.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 113 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 114 |
+
"model.layers.16.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 115 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 116 |
+
"model.layers.17.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 117 |
+
"model.layers.17.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 118 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 119 |
+
"model.layers.17.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 120 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 121 |
+
"model.layers.17.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 122 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 123 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 124 |
+
"model.layers.17.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 125 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 126 |
+
"model.layers.17.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 127 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 128 |
+
"model.layers.18.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 129 |
+
"model.layers.18.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 130 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 131 |
+
"model.layers.18.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 132 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 133 |
+
"model.layers.18.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 134 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 135 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 136 |
+
"model.layers.18.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 137 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 138 |
+
"model.layers.18.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 139 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 140 |
+
"model.layers.19.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 141 |
+
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 142 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 143 |
+
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 144 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 145 |
+
"model.layers.19.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 146 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 147 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 148 |
+
"model.layers.19.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 149 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 150 |
+
"model.layers.19.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 151 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 152 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 153 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 154 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 155 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 156 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 157 |
+
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 158 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 159 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 160 |
+
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 161 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 162 |
+
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 163 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 164 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 165 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 166 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 167 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 168 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 169 |
+
"model.layers.20.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 170 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 171 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 172 |
+
"model.layers.20.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 173 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 174 |
+
"model.layers.20.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 175 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 176 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 177 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 178 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 179 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 180 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 181 |
+
"model.layers.21.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 182 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 183 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 184 |
+
"model.layers.21.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 185 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 186 |
+
"model.layers.21.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 187 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 188 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 189 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 190 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 191 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 192 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 193 |
+
"model.layers.22.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 194 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 195 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 196 |
+
"model.layers.22.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 197 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 198 |
+
"model.layers.22.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 199 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 200 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 201 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 202 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 203 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 204 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 205 |
+
"model.layers.23.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 206 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 207 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 208 |
+
"model.layers.23.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 209 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 210 |
+
"model.layers.23.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 211 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 212 |
+
"model.layers.24.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 213 |
+
"model.layers.24.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 214 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 215 |
+
"model.layers.24.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 216 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 217 |
+
"model.layers.24.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 218 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 219 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 220 |
+
"model.layers.24.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 221 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 222 |
+
"model.layers.24.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 223 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 224 |
+
"model.layers.25.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 225 |
+
"model.layers.25.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 226 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 227 |
+
"model.layers.25.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 228 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 229 |
+
"model.layers.25.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 230 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 231 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 232 |
+
"model.layers.25.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 233 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 234 |
+
"model.layers.25.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 235 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 236 |
+
"model.layers.26.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 237 |
+
"model.layers.26.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 238 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 239 |
+
"model.layers.26.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 240 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 241 |
+
"model.layers.26.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 242 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 243 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 244 |
+
"model.layers.26.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 245 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 246 |
+
"model.layers.26.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 247 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 248 |
+
"model.layers.27.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 249 |
+
"model.layers.27.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 250 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 251 |
+
"model.layers.27.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 252 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 253 |
+
"model.layers.27.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 254 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 255 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 256 |
+
"model.layers.27.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 257 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 258 |
+
"model.layers.27.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 259 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 260 |
+
"model.layers.28.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 261 |
+
"model.layers.28.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 262 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 263 |
+
"model.layers.28.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 264 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 265 |
+
"model.layers.28.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 266 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 267 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 268 |
+
"model.layers.28.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 269 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 270 |
+
"model.layers.28.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 271 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 272 |
+
"model.layers.29.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 273 |
+
"model.layers.29.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 274 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 275 |
+
"model.layers.29.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 276 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 277 |
+
"model.layers.29.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 278 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 279 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 280 |
+
"model.layers.29.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 281 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 282 |
+
"model.layers.29.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 283 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 284 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 285 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 286 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 287 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 288 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 289 |
+
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 290 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 291 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 292 |
+
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 293 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 294 |
+
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 295 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 296 |
+
"model.layers.30.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 297 |
+
"model.layers.30.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 298 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 299 |
+
"model.layers.30.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 300 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 301 |
+
"model.layers.30.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 302 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 303 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 304 |
+
"model.layers.30.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 305 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 306 |
+
"model.layers.30.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 307 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 308 |
+
"model.layers.31.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 309 |
+
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 310 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 311 |
+
"model.layers.31.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 312 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 313 |
+
"model.layers.31.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 314 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 315 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 316 |
+
"model.layers.31.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 317 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 318 |
+
"model.layers.31.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 319 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 320 |
+
"model.layers.32.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 321 |
+
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 322 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 323 |
+
"model.layers.32.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 324 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 325 |
+
"model.layers.32.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 326 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 327 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 328 |
+
"model.layers.32.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 329 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 330 |
+
"model.layers.32.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 331 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 332 |
+
"model.layers.33.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 333 |
+
"model.layers.33.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 334 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 335 |
+
"model.layers.33.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 336 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 337 |
+
"model.layers.33.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 338 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 339 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 340 |
+
"model.layers.33.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 341 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 342 |
+
"model.layers.33.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 343 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 344 |
+
"model.layers.34.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 345 |
+
"model.layers.34.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 346 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 347 |
+
"model.layers.34.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 348 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 349 |
+
"model.layers.34.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 350 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 351 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 352 |
+
"model.layers.34.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 353 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 354 |
+
"model.layers.34.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 355 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 356 |
+
"model.layers.35.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 357 |
+
"model.layers.35.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 358 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 359 |
+
"model.layers.35.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 360 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 361 |
+
"model.layers.35.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 362 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 363 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 364 |
+
"model.layers.35.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 365 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 366 |
+
"model.layers.35.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 367 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 368 |
+
"model.layers.36.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 369 |
+
"model.layers.36.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 370 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 371 |
+
"model.layers.36.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 372 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 373 |
+
"model.layers.36.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 374 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 375 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 376 |
+
"model.layers.36.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 377 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 378 |
+
"model.layers.36.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 379 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 380 |
+
"model.layers.37.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 381 |
+
"model.layers.37.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 382 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 383 |
+
"model.layers.37.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 384 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 385 |
+
"model.layers.37.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 386 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 387 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 388 |
+
"model.layers.37.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 389 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 390 |
+
"model.layers.37.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 391 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 392 |
+
"model.layers.38.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 393 |
+
"model.layers.38.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 394 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 395 |
+
"model.layers.38.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 396 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 397 |
+
"model.layers.38.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 398 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 399 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 400 |
+
"model.layers.38.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 401 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 402 |
+
"model.layers.38.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 403 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 404 |
+
"model.layers.39.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 405 |
+
"model.layers.39.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 406 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 407 |
+
"model.layers.39.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 408 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 409 |
+
"model.layers.39.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 410 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 411 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 412 |
+
"model.layers.39.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 413 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 414 |
+
"model.layers.39.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 415 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 416 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 417 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 418 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 419 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 420 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 421 |
+
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 422 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 423 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 424 |
+
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 425 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 426 |
+
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 427 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 428 |
+
"model.layers.40.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 429 |
+
"model.layers.40.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 430 |
+
"model.layers.40.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 431 |
+
"model.layers.40.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 432 |
+
"model.layers.40.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 433 |
+
"model.layers.40.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 434 |
+
"model.layers.40.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 435 |
+
"model.layers.40.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 436 |
+
"model.layers.40.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 437 |
+
"model.layers.40.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 438 |
+
"model.layers.40.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 439 |
+
"model.layers.40.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 440 |
+
"model.layers.41.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 441 |
+
"model.layers.41.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 442 |
+
"model.layers.41.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 443 |
+
"model.layers.41.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 444 |
+
"model.layers.41.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 445 |
+
"model.layers.41.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 446 |
+
"model.layers.41.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 447 |
+
"model.layers.41.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 448 |
+
"model.layers.41.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 449 |
+
"model.layers.41.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 450 |
+
"model.layers.41.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 451 |
+
"model.layers.41.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 452 |
+
"model.layers.42.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 453 |
+
"model.layers.42.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 454 |
+
"model.layers.42.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 455 |
+
"model.layers.42.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 456 |
+
"model.layers.42.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 457 |
+
"model.layers.42.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 458 |
+
"model.layers.42.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 459 |
+
"model.layers.42.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 460 |
+
"model.layers.42.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 461 |
+
"model.layers.42.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 462 |
+
"model.layers.42.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 463 |
+
"model.layers.42.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 464 |
+
"model.layers.43.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 465 |
+
"model.layers.43.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 466 |
+
"model.layers.43.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 467 |
+
"model.layers.43.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 468 |
+
"model.layers.43.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 469 |
+
"model.layers.43.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 470 |
+
"model.layers.43.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 471 |
+
"model.layers.43.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 472 |
+
"model.layers.43.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 473 |
+
"model.layers.43.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 474 |
+
"model.layers.43.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 475 |
+
"model.layers.43.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 476 |
+
"model.layers.44.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 477 |
+
"model.layers.44.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 478 |
+
"model.layers.44.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 479 |
+
"model.layers.44.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 480 |
+
"model.layers.44.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 481 |
+
"model.layers.44.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 482 |
+
"model.layers.44.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 483 |
+
"model.layers.44.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 484 |
+
"model.layers.44.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 485 |
+
"model.layers.44.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 486 |
+
"model.layers.44.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 487 |
+
"model.layers.44.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 488 |
+
"model.layers.45.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 489 |
+
"model.layers.45.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 490 |
+
"model.layers.45.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 491 |
+
"model.layers.45.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 492 |
+
"model.layers.45.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 493 |
+
"model.layers.45.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 494 |
+
"model.layers.45.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 495 |
+
"model.layers.45.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 496 |
+
"model.layers.45.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 497 |
+
"model.layers.45.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 498 |
+
"model.layers.45.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 499 |
+
"model.layers.45.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 500 |
+
"model.layers.46.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 501 |
+
"model.layers.46.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 502 |
+
"model.layers.46.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 503 |
+
"model.layers.46.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 504 |
+
"model.layers.46.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 505 |
+
"model.layers.46.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 506 |
+
"model.layers.46.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 507 |
+
"model.layers.46.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 508 |
+
"model.layers.46.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 509 |
+
"model.layers.46.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 510 |
+
"model.layers.46.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 511 |
+
"model.layers.46.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 512 |
+
"model.layers.47.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 513 |
+
"model.layers.47.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 514 |
+
"model.layers.47.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 515 |
+
"model.layers.47.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 516 |
+
"model.layers.47.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 517 |
+
"model.layers.47.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 518 |
+
"model.layers.47.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 519 |
+
"model.layers.47.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 520 |
+
"model.layers.47.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 521 |
+
"model.layers.47.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 522 |
+
"model.layers.47.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 523 |
+
"model.layers.47.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 524 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 525 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 526 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 527 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 528 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 529 |
+
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 530 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 531 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 532 |
+
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 533 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 534 |
+
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 535 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 536 |
+
"model.layers.6.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 537 |
+
"model.layers.6.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 538 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 539 |
+
"model.layers.6.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 540 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 541 |
+
"model.layers.6.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 542 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 543 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 544 |
+
"model.layers.6.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 545 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 546 |
+
"model.layers.6.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 547 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 548 |
+
"model.layers.7.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 549 |
+
"model.layers.7.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 550 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 551 |
+
"model.layers.7.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 552 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 553 |
+
"model.layers.7.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 554 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 555 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 556 |
+
"model.layers.7.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 557 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 558 |
+
"model.layers.7.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 559 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 560 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 561 |
+
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 562 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 563 |
+
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 564 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 565 |
+
"model.layers.8.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 566 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 567 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 568 |
+
"model.layers.8.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 569 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 570 |
+
"model.layers.8.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 571 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 572 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 573 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 574 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 575 |
+
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 576 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 577 |
+
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 578 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 579 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 580 |
+
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 581 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 582 |
+
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 583 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 584 |
+
"model.norm.weight": "model-00006-of-00006.safetensors"
|
| 585 |
+
}
|
| 586 |
+
}
|
tokenization_baichuan.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023, Baichuan Intelligent Technology. All rights reserved.
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
from shutil import copyfile
|
| 5 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import sentencepiece as spm
|
| 8 |
+
from transformers.tokenization_utils import AddedToken, PreTrainedTokenizer
|
| 9 |
+
from transformers.utils import logging
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
logger = logging.get_logger(__name__)
|
| 13 |
+
|
| 14 |
+
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
|
| 15 |
+
|
| 16 |
+
PRETRAINED_VOCAB_FILES_MAP = {
|
| 17 |
+
"vocab_file": {},
|
| 18 |
+
"tokenizer_file": {},
|
| 19 |
+
}
|
| 20 |
+
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {}
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class BaichuanTokenizer(PreTrainedTokenizer):
|
| 24 |
+
"""
|
| 25 |
+
Construct a Baichuan tokenizer. Based on byte-level Byte-Pair-Encoding.
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
vocab_file (`str`):
|
| 29 |
+
Path to the vocabulary file.
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 33 |
+
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
| 34 |
+
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
| 35 |
+
model_input_names = ["input_ids", "attention_mask"]
|
| 36 |
+
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
vocab_file,
|
| 40 |
+
unk_token="<unk>",
|
| 41 |
+
bos_token="<s>",
|
| 42 |
+
eos_token="</s>",
|
| 43 |
+
pad_token=None,
|
| 44 |
+
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
| 45 |
+
add_bos_token=True,
|
| 46 |
+
add_eos_token=False,
|
| 47 |
+
clean_up_tokenization_spaces=False,
|
| 48 |
+
**kwargs,
|
| 49 |
+
):
|
| 50 |
+
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
|
| 51 |
+
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
|
| 52 |
+
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
|
| 53 |
+
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
|
| 54 |
+
pad_token = AddedToken(pad_token, lstrip=False, rstrip=False) if isinstance(pad_token, str) else pad_token
|
| 55 |
+
super().__init__(
|
| 56 |
+
bos_token=bos_token,
|
| 57 |
+
eos_token=eos_token,
|
| 58 |
+
unk_token=unk_token,
|
| 59 |
+
pad_token=pad_token,
|
| 60 |
+
add_bos_token=add_bos_token,
|
| 61 |
+
add_eos_token=add_eos_token,
|
| 62 |
+
sp_model_kwargs=self.sp_model_kwargs,
|
| 63 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 64 |
+
**kwargs,
|
| 65 |
+
)
|
| 66 |
+
self.vocab_file = vocab_file
|
| 67 |
+
self.add_bos_token = add_bos_token
|
| 68 |
+
self.add_eos_token = add_eos_token
|
| 69 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 70 |
+
self.sp_model.Load(vocab_file)
|
| 71 |
+
|
| 72 |
+
def __getstate__(self):
|
| 73 |
+
state = self.__dict__.copy()
|
| 74 |
+
state["sp_model"] = None
|
| 75 |
+
return state
|
| 76 |
+
|
| 77 |
+
def __setstate__(self, d):
|
| 78 |
+
self.__dict__ = d
|
| 79 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 80 |
+
self.sp_model.Load(self.vocab_file)
|
| 81 |
+
|
| 82 |
+
@property
|
| 83 |
+
def vocab_size(self):
|
| 84 |
+
"""Returns vocab size"""
|
| 85 |
+
return self.sp_model.get_piece_size()
|
| 86 |
+
|
| 87 |
+
def get_vocab(self):
|
| 88 |
+
"""Returns vocab as a dict"""
|
| 89 |
+
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
| 90 |
+
vocab.update(self.added_tokens_encoder)
|
| 91 |
+
return vocab
|
| 92 |
+
|
| 93 |
+
def _tokenize(self, text):
|
| 94 |
+
"""Returns a tokenized string."""
|
| 95 |
+
return self.sp_model.encode(text, out_type=str)
|
| 96 |
+
|
| 97 |
+
def _convert_token_to_id(self, token):
|
| 98 |
+
"""Converts a token (str) in an id using the vocab."""
|
| 99 |
+
return self.sp_model.piece_to_id(token)
|
| 100 |
+
|
| 101 |
+
def _convert_id_to_token(self, index):
|
| 102 |
+
"""Converts an index (integer) in a token (str) using the vocab."""
|
| 103 |
+
token = self.sp_model.IdToPiece(index)
|
| 104 |
+
return token
|
| 105 |
+
|
| 106 |
+
def convert_tokens_to_string(self, tokens):
|
| 107 |
+
"""Converts a sequence of tokens (string) in a single string."""
|
| 108 |
+
current_sub_tokens = []
|
| 109 |
+
out_string = ""
|
| 110 |
+
prev_is_special = False
|
| 111 |
+
for i, token in enumerate(tokens):
|
| 112 |
+
# make sure that special tokens are not decoded using sentencepiece model
|
| 113 |
+
if token in self.all_special_tokens:
|
| 114 |
+
if not prev_is_special and i != 0:
|
| 115 |
+
out_string += " "
|
| 116 |
+
out_string += self.sp_model.decode(current_sub_tokens) + token
|
| 117 |
+
prev_is_special = True
|
| 118 |
+
current_sub_tokens = []
|
| 119 |
+
else:
|
| 120 |
+
current_sub_tokens.append(token)
|
| 121 |
+
prev_is_special = False
|
| 122 |
+
out_string += self.sp_model.decode(current_sub_tokens)
|
| 123 |
+
return out_string
|
| 124 |
+
|
| 125 |
+
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
| 126 |
+
"""
|
| 127 |
+
Save the vocabulary and special tokens file to a directory.
|
| 128 |
+
|
| 129 |
+
Args:
|
| 130 |
+
save_directory (`str`):
|
| 131 |
+
The directory in which to save the vocabulary.
|
| 132 |
+
|
| 133 |
+
Returns:
|
| 134 |
+
`Tuple(str)`: Paths to the files saved.
|
| 135 |
+
"""
|
| 136 |
+
if not os.path.isdir(save_directory):
|
| 137 |
+
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
|
| 138 |
+
return
|
| 139 |
+
out_vocab_file = os.path.join(
|
| 140 |
+
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
|
| 144 |
+
copyfile(self.vocab_file, out_vocab_file)
|
| 145 |
+
elif not os.path.isfile(self.vocab_file):
|
| 146 |
+
with open(out_vocab_file, "wb") as fi:
|
| 147 |
+
content_spiece_model = self.sp_model.serialized_model_proto()
|
| 148 |
+
fi.write(content_spiece_model)
|
| 149 |
+
|
| 150 |
+
return (out_vocab_file,)
|
| 151 |
+
|
| 152 |
+
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
| 153 |
+
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
|
| 154 |
+
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
|
| 155 |
+
|
| 156 |
+
output = bos_token_id + token_ids_0 + eos_token_id
|
| 157 |
+
|
| 158 |
+
if token_ids_1 is not None:
|
| 159 |
+
output = output + bos_token_id + token_ids_1 + eos_token_id
|
| 160 |
+
|
| 161 |
+
return output
|
| 162 |
+
|
| 163 |
+
def get_special_tokens_mask(
|
| 164 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
|
| 165 |
+
) -> List[int]:
|
| 166 |
+
"""
|
| 167 |
+
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
|
| 168 |
+
special tokens using the tokenizer `prepare_for_model` method.
|
| 169 |
+
|
| 170 |
+
Args:
|
| 171 |
+
token_ids_0 (`List[int]`):
|
| 172 |
+
List of IDs.
|
| 173 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 174 |
+
Optional second list of IDs for sequence pairs.
|
| 175 |
+
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
|
| 176 |
+
Whether or not the token list is already formatted with special tokens for the model.
|
| 177 |
+
|
| 178 |
+
Returns:
|
| 179 |
+
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
|
| 180 |
+
"""
|
| 181 |
+
if already_has_special_tokens:
|
| 182 |
+
return super().get_special_tokens_mask(
|
| 183 |
+
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
bos_token_id = [1] if self.add_bos_token else []
|
| 187 |
+
eos_token_id = [1] if self.add_eos_token else []
|
| 188 |
+
|
| 189 |
+
if token_ids_1 is None:
|
| 190 |
+
return bos_token_id + ([0] * len(token_ids_0)) + eos_token_id
|
| 191 |
+
return (
|
| 192 |
+
bos_token_id
|
| 193 |
+
+ ([0] * len(token_ids_0))
|
| 194 |
+
+ eos_token_id
|
| 195 |
+
+ bos_token_id
|
| 196 |
+
+ ([0] * len(token_ids_1))
|
| 197 |
+
+ eos_token_id
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
def create_token_type_ids_from_sequences(
|
| 201 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
| 202 |
+
) -> List[int]:
|
| 203 |
+
"""
|
| 204 |
+
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
|
| 205 |
+
sequence pair mask has the following format:
|
| 206 |
+
|
| 207 |
+
```
|
| 208 |
+
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
|
| 209 |
+
| first sequence | second sequence |
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
if token_ids_1 is None, only returns the first portion of the mask (0s).
|
| 213 |
+
|
| 214 |
+
Args:
|
| 215 |
+
token_ids_0 (`List[int]`):
|
| 216 |
+
List of ids.
|
| 217 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 218 |
+
Optional second list of IDs for sequence pairs.
|
| 219 |
+
|
| 220 |
+
Returns:
|
| 221 |
+
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
|
| 222 |
+
"""
|
| 223 |
+
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
|
| 224 |
+
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
|
| 225 |
+
|
| 226 |
+
output = [0] * len(bos_token_id + token_ids_0 + eos_token_id)
|
| 227 |
+
|
| 228 |
+
if token_ids_1 is not None:
|
| 229 |
+
output += [1] * len(bos_token_id + token_ids_1 + eos_token_id)
|
| 230 |
+
|
| 231 |
+
return output
|
| 232 |
+
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 199 |
+
"clean_up_tokenization_spaces": false,
|
| 200 |
+
"eos_token": "<|im_end|>",
|
| 201 |
+
"errors": "replace",
|
| 202 |
+
"model_max_length": 131072,
|
| 203 |
+
"pad_token": "<|endoftext|>",
|
| 204 |
+
"split_special_tokens": false,
|
| 205 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 206 |
+
"unk_token": null
|
| 207 |
+
}
|