---
license: apache-2.0
library_name: mlx
pipeline_tag: text-generation
tags:
- 1-bit
- mlx
- mlx-swift
- apple-silicon
- on-device
- prismml
- bonsai
---

Prism ML Website |
Whitepaper |
Demo & Examples |
Colab Notebook |
Discord
# Bonsai-8B-mlx-1bit
End-to-end 1-bit language model for Apple Silicon
> **12.8x** smaller than FP16 | **8.4x** faster on M4 Pro | **44** tok/s on iPhone | runs on Mac, iPhone, iPad
## Highlights
- **1.28 GB** parameter memory (down from 16.38 GB FP16) — runs comfortably on any Mac or iPhone
- **End-to-end 1-bit weights** across embeddings, attention projections, MLP projections, and LM head
- **MLX-native format** (1-bit g128) with inline dequantization kernels — no FP16 materialization
- **Competitive benchmarks**: 70.5 avg score across 6 categories, matching full-precision 8B models at 1/14th the size
- **Cross-platform companion**: also available as [GGUF Q1_0_g128](https://huggingface.co/prism-ml/Bonsai-8B-gguf) for llama.cpp

## Resources
- **[Google Colab](https://colab.research.google.com/drive/1EzyAaQ2nwDv_1X0jaC5XiVC3ZREg9bdG?usp=sharing)** — try Bonsai in your browser, no setup required
- **[Whitepaper](https://github.com/PrismML-Eng/Bonsai-demo/blob/main/1-bit-bonsai-8b-whitepaper.pdf)** — for more details on Bonsai, check out our whitepaper
- **[Demo repo](https://github.com/PrismML-Eng/Bonsai-demo)** — comprehensive examples for serving, benchmarking, and integrating Bonsai
- **[Discord](https://discord.gg/prismml)** — join the community for support, discussion, and updates
- **1-bit kernels**: [MLX fork](https://github.com/PrismML-Eng/mlx) (Apple Silicon) · [mlx-swift fork](https://github.com/PrismML-Eng/mlx-swift) (iOS/macOS) · [llama.cpp fork](https://github.com/PrismML-Eng/llama.cpp) (CUDA + Metal)
- **[Locally AI](https://locallyai.app/)** — we have partnered with Locally AI for iPhone support
## Model Overview
| Item | Specification |
| :------------- | :--------------------------------------------------------------------- |
| Parameters | 8.19B (~6.95B non-embedding) |
| Architecture | Qwen3-8B dense: GQA (32 query / 8 KV heads), SwiGLU MLP, RoPE, RMSNorm |
| Layers | 36 Transformer decoder blocks |
| Context length | 65,536 tokens |
| Vocab size | 151,936 |
| Weight format | MLX 1-bit g128 |
| Deployed size | **1.28 GB** (12.8x smaller than FP16) |
| 1-bit coverage | Embeddings, attention projections, MLP projections, LM head |
| License | Apache 2.0 |
## Quantization Format: 1-bit g128
Each weight is a single bit: `0` maps to `−scale`, `1` maps to `+scale`. Every group of 128 weights shares one FP16 scale factor.
MLX's quantization formats generally store both a scale and a bias per group: `w = mlx_scale * bit + mlx_bias`. To pack our scale-only 1-bit weights into this format:
```
mlx_scale = 2 * original_scale
mlx_bias = −original_scale
```
This reconstructs `−scale` when `bit=0` and `+scale` when `bit=1`. Because MLX stores two FP16 values per group (scale + bias) instead of one, the effective bits per weight is slightly higher than the GGUF format:
- **MLX 1-bit g128**: **1.25 bpw** (1 sign bit + two 16-bit values amortized over 128 weights)
- **GGUF Q1_0_g128**: **1.125 bpw** (1 sign bit + one 16-bit scale amortized over 128 weights)
### Memory Requirement
Parameter memory only (weights and scales loaded into memory):
| Format | Size | Reduction | Ratio |
| :----------------- | ----------: | --------: | --------: |
| FP16 | 16.38 GB | — | 1.0x |
| **MLX 1-bit g128** | **1.28 GB** | **92.2%** | **12.8x** |
| GGUF Q1_0_g128 | 1.15 GB | 93.0% | 14.2x |
The model directory on disk is ~1.30 GB (~16 MB larger) because it also includes tokenizer, config, and other metadata files alongside the weights.
## Best Practices
### Generation Parameters
| Parameter | Default | Suggested range |
| :----------------- | :------ | :-------------- |
| Temperature | 0.5 | 0.5 -- 0.7 |
| Top-k | 20 | 20 -- 40 |
| Top-p | 0.9 | 0.85 -- 0.95 |
| Repetition penalty | 1.0 | |
| Presence penalty | 0.0 | |
### System Prompt
You can use a simple system prompt such as:
```
You are a helpful assistant
```
## Quickstart
### MLX (Python)
> **Requires PrismML fork of MLX** with 1-bit kernel support (upstream PR pending):
> ```bash
> pip install mlx-lm
> pip install mlx @ git+https://github.com/PrismML-Eng/mlx.git@prism
> ```
```python
from mlx_lm import load, generate
model, tokenizer = load("prism-ml/Bonsai-8B-mlx-1bit")
response = generate(
model,
tokenizer,
prompt="Explain quantum computing in simple terms.",
max_tokens=256,
)
print(response)
```
### MLX Swift (iOS / macOS)
1-bit Bonsai 8B runs natively on iPhone and iPad via MLX Swift at **44 tok/s** on iPhone 17 Pro Max. Requires our [mlx-swift fork with 1-bit kernels](https://github.com/PrismML-Eng/mlx-swift) (upstream PR pending).
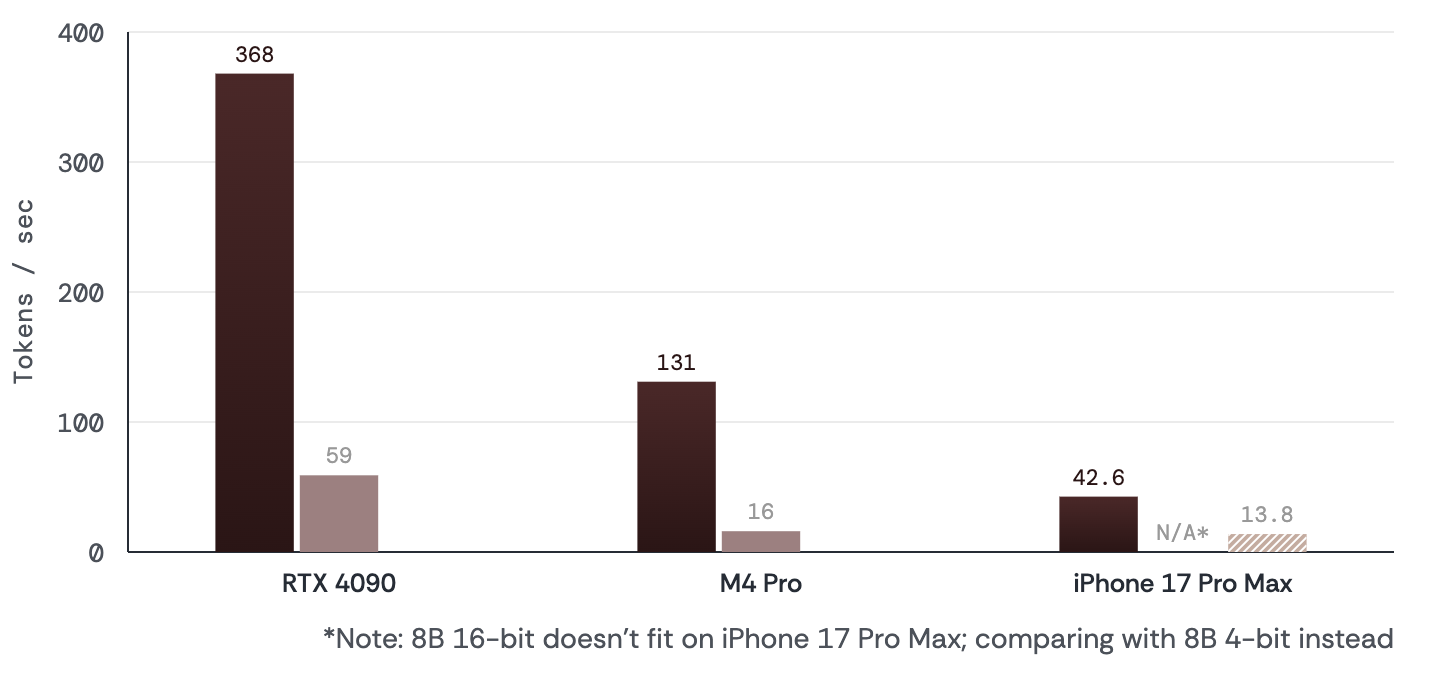
## Throughput (MLX / Apple Silicon)
| Platform | Backend | TG128 (tok/s) | FP16 TG (tok/s) | TG vs FP16 | PP512 (tok/s) | FP16 PP512 (tok/s) |
| :----------- | :-------------- | ------------: | --------------: | ---------: | ------------: | -----------------: |
| M4 Pro 48 GB | MLX (Python) | 131 | 16 | **8.4x** | 472 | 434 |
| M4 Pro 48 GB | llama.cpp Metal | 85 | 16 | **5.4x** | 498 | 490 |
### iPhone 17 Pro Max (MLX Swift)
FP16 does not fit on-device; baseline is 4-bit.
| | 1-bit (tok/s) | 4-bit (tok/s) | 1-bit vs 4-bit |
| :---------------- | ------------: | ------------: | -------------: |
| Token generation | 44 | 14 | **3.1x** |
| Prompt processing | 377 | 348 | 1.08x |
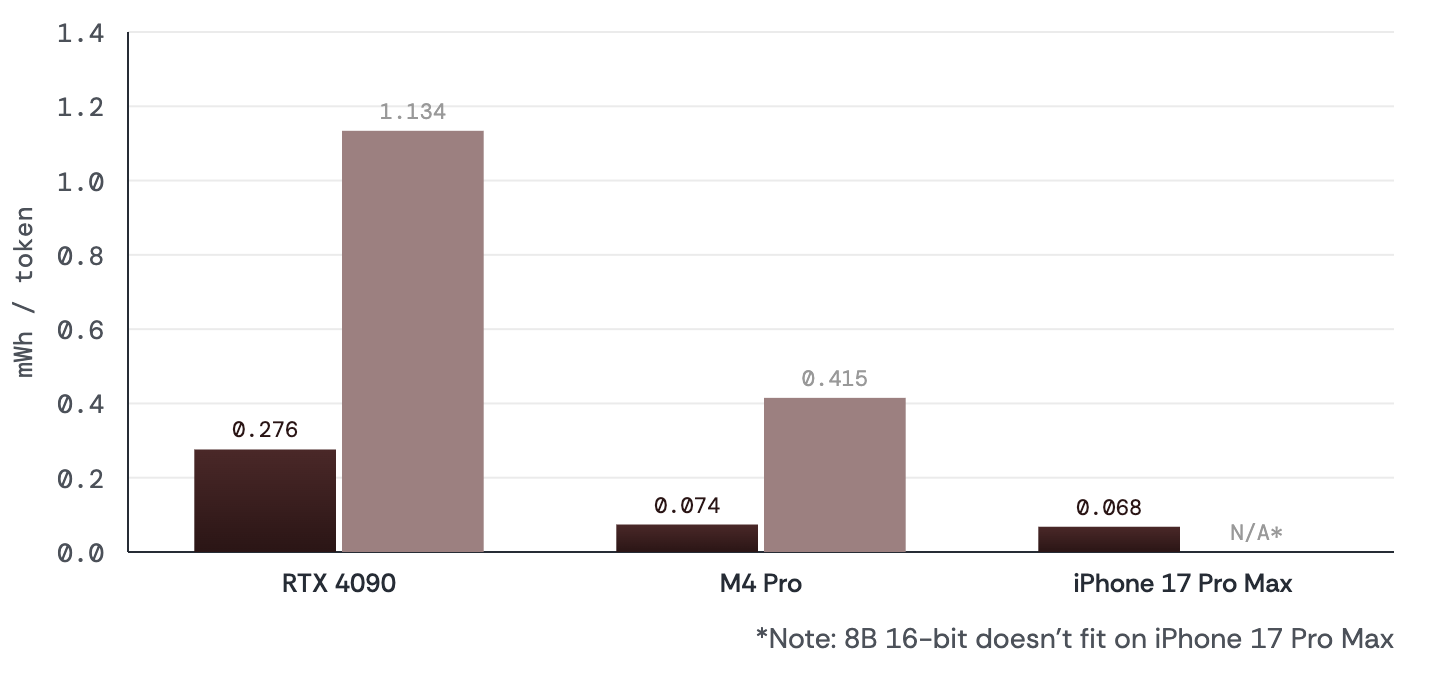
## Energy Efficiency
| Platform | Bonsai E_tg (mWh/tok) | Baseline E_tg | Advantage |
| :----------------- | --------------------: | -------------: | ----------------: |
| Mac M4 Pro (MLX) | 0.074 | 0.415 (FP16) | **5.6x** |
| Mac M4 Pro (Metal) | 0.091 | 0.471 (FP16) | **5.1x** |
| iPhone 17 Pro Max | ~0.068 | ~0.143 (4-bit) | **2.1x** vs 4-bit |
Higher instantaneous power does not preclude lower energy — token generation is so much faster that energy per output token drops 4–6x.
## Benchmarks
Evaluated with EvalScope v1.4.2 + vLLM 0.15.1 on NVIDIA H100 under identical infrastructure, generation parameters, and scoring. All models are in the 6B–9B parameter range.
| Model | Company | Size | Avg | MMLU-R | MuSR | GSM8K | HE+ | IFEval | BFCL |
| :------------------ | :------------ | ----------: | -------: | -----: | ---: | ----: | ---: | -----: | ---: |
| Qwen 3 8B | Alibaba | 16 GB | **79.3** | 83 | 55 | 93 | 82.3 | 84.2 | 81 |
| RNJ 8B | EssentialAI | 16 GB | **73.1** | 75.5 | 50.4 | 93.7 | 84.2 | 73.8 | 61.1 |
| Mistral3 8B | Mistral | 16 GB | **71.0** | 73.9 | 53.8 | 87.2 | 67.4 | 75.4 | 45.4 |
| Olmo 3 7B | Allen Inst | 14 GB | **70.9** | 72 | 56.1 | 92.5 | 79.3 | 37.1 | 38.4 |
| **1-bit Bonsai 8B** | **PrismML** | **1.15 GB** | **70.5** | 65.7 | 50 | 88 | 73.8 | 79.8 | 65.7 |
| LFM2 8B | LiquidAI | 16 GB | **69.6** | 72.7 | 49.5 | 90.1 | 81 | 82.2 | 62.0 |
| Llama 3.1 8B | Meta | 16 GB | **67.1** | 72.9 | 51.3 | 87.9 | 75 | 51.5 | — |
| GLM v6 9B | ZhipuAI | 16 GB | **65.7** | 61.9 | 43.2 | 93.4 | 78.7 | 69.3 | 21.9 |
| Hermes 8B | Nous Research | 16 GB | **65.4** | 67.4 | 52.2 | 82.9 | 51.2 | 65 | 73.5 |
| Trinity Nano 6B | Arcee | 12 GB | **61.2** | 68.8 | 52.6 | 81.1 | 54 | 50 | 62.5 |
| Marin 8B | Stanford CRFM | 16 GB | **56.6** | 64.8 | 42.6 | 86.4 | 51 | 50 | — |
| R1-D 7B | DeepSeek | 14 GB | **55.1** | 62.5 | 29.1 | 92.7 | 81.7 | 48.8 | 15.4 |
Despite being **1/14th the size**, 1-bit Bonsai 8B is competitive with leading full-precision 8B instruct models.
## Intelligence Density
Intelligence density captures the ratio of a model's capability to its deployed size:
```
alpha = -ln(1 - score/100) / size_GB
```
| Model | Size | Intelligence Density (1/GB) |
| :------------------ | ----------: | --------------------------: |
| **1-bit Bonsai 8B** | **1.15 GB** | **1.062** |
| Qwen 3 8B | 16 GB | 0.098 |
| Llama 3.1 8B | 16 GB | 0.074 |
| Mistral3 8B | 16 GB | 0.077 |
Bonsai 8B achieves **10.8x higher intelligence density** than full-precision Qwen 3 8B.

## Use Cases
- **On-device assistants**: interactive AI on Mac, iPhone, and iPad with low latency and strong privacy
- **Mobile deployment**: runs on a wide variety of phones due to low memory footprint
- **Edge robotics and autonomy**: compact deployment on devices with thermal, memory, or connectivity constraints
- **Cost-sensitive GPU serving**: higher throughput and lower energy per token on commodity GPU deployments
- **Enterprise and private inference**: local or controlled-environment inference for data residency requirements
## Limitations
- No native 1-bit hardware exists yet — current gains are software-kernel optimizations on general-purpose hardware
- Mobile power measurement is estimated (Xcode Power Profiler) rather than hardware-metered
- The full-precision benchmark frontier continues to advance; the 1-bit methodology is architecture-agnostic and will be applied to newer bases
## Citation
If you use 1-bit Bonsai 8B, please cite:
```bibtex
@techreport{bonsai8b,
title = {1-bit Bonsai 8B: End-to-End 1-bit Language Model Deployment
Across Apple, GPU, and Mobile Runtimes},
author = {Prism ML},
year = {2026},
month = {March},
url = {https://prismml.com}
}
```
## Contact
For questions, feedback, or collaboration inquiries: **contact@prismml.com**