---
language:
- en
- uk
license: apache-2.0
library_name: transformers
tags:
- ocr
- icr
- handwriting-recognition
- ukrainian
- ctc
- pytorch
- onnx
pipeline_tag: image-to-text
base_model: DAIR-Group/HTR-ConvText
metrics:
- cer
- wer
---
# 🇺🇦 Ukrainian OCR / ICR (HTR-ConvText)
**Handwritten & printed text recognition for Ukrainian**
[](https://huggingface.co/spaces/Valerii02/ukr-htr-convtext-demo)
*Upload an image → Get recognized text*
[English](#quickstart) · [Українська](README.uk.md)
## 📋 Table of Contents
- [✨ Highlights](#highlights)
- [🚀 Quickstart](#quickstart)
- [📖 Model Description](#model-description)
- [🖼️ Recognition Examples](#recognition-examples)
- [🛠️ Tools & Scripts](#tools--scripts)
- [📊 Evaluation](#evaluation)
- [🙏 Attribution & Citation](#attribution--citation)
## ✨ Highlights
| Feature | Description |
|---------|-------------|
| **Language** | Ukrainian (handwritten + printed) |
| **Architecture** | HTR-ConvText (ResNet-18 + MobileViT), CTC decoding |
| **Input** | 64×3072 px, grayscale line images |
| **Training** | 1.7M samples, SAM, EMA, scan simulation |
| **Formats** | PyTorch, ONNX, Hugging Face `AutoModel` |
## 🚀 Quickstart
```python
from transformers import AutoModel, AutoProcessor
processor = AutoProcessor.from_pretrained("Valerii02/ukr-htr-convtext", trust_remote_code=True)
model = AutoModel.from_pretrained("Valerii02/ukr-htr-convtext", trust_remote_code=True)
```
```python
inputs = processor(images="sample.png", return_tensors="pt")
logits = model(**inputs).logits
text = processor.batch_decode(logits)[0]
print(text)
```
> 💡 **Try it now:** [Open the Gradio demo](https://huggingface.co/spaces/Valerii02/ukr-htr-convtext-demo) — no code required!
## 📖 Model Description
This repository packages a **Ukrainian OCR/ICR model** for handwritten and partially printed text with a Hugging Face–native API (`AutoModel` + `AutoProcessor`).
### Architecture
- **Backbone:** ResNet-18 + MobileViT (MVP), hierarchical ConvText encoder (U-Net-like down/upsampling)
- **Decoding:** CTC greedy
- **Vocabulary:** 151 characters (Ukrainian + symbols)
### Training Data
| Source | Samples |
|--------|---------|
| [ukrainian-handwriting-synth](https://github.com/ValeriiSielikhov/ukrainian-handwriting-synth) | Synthetic handwritten lines |
| [Ukrainian Handwritten Text](https://www.kaggle.com/datasets/annyhnatiuk/ukrainian-handwritten-text) | ~37k segmented lines |
| **Total** | **1,696,499** (Train 90% / Val 5% / Test 5%) |
### Training
- 500k iterations, batch 16 + grad accum 4
- SAM optimizer, EMA (decay 0.9999), TCM warmup 40k iters
- Scan simulation & detector-error augmentations
- Hardware: NVIDIA B200 (180GB VRAM)
## 🖼️ Recognition Examples
| Example | Image | GT | Prediction | CER | WER |
|---------|-------|----|------------|-----|-----|
| 1 |  | Департаменту патрульної поліції | Департаменту нагрульної поліції | 0.065 | 0.33 |
| 2 | 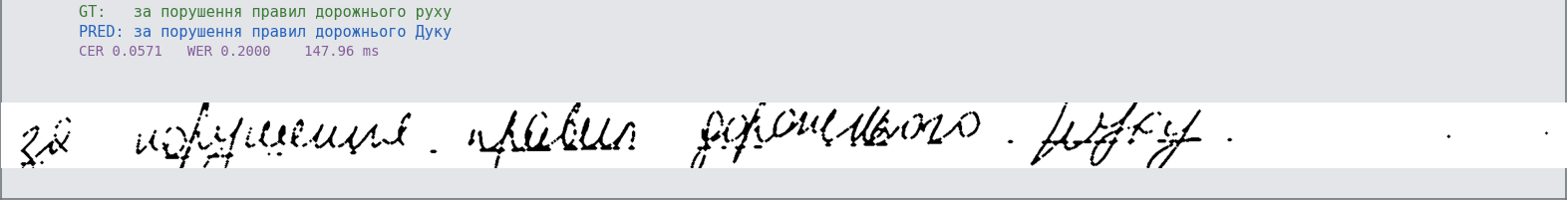 | за порушення правил дорожнього руху | за порушення правил дорожнього Дуку | 0.057 | 0.20 |
*Real-world inference on scanned Ukrainian documents. GT = ground truth.*
## 🛠️ Tools & Scripts
| File | Purpose |
|------|---------|
| `prepare_hf_artifacts.py` | Convert `.pth` checkpoint → HF artifacts |
| `export_onnx.py` | Export to ONNX |
| `validate_parity.py` | OpenCV vs PIL, PyTorch vs ONNX parity checks |
| `predict.py` | Single-image CLI inference |
### Conversion
```bash
python prepare_hf_artifacts.py \
--checkpoint-path /path/to/best_CER.pth \
--alphabet-path /path/to/alphabet.json \
--output-dir ./release
```
### ONNX Export
```bash
python export_onnx.py --hf-model-dir ./release --output-dir ./onnx
```
## 📊 Evaluation
| Split | CER | WER | Notes |
|---|---:|---:|---|
| real-world (124) | 0.176 | 0.440 | Scanned docs, handwritten + printed |
*Micro-averaging, `format_string_for_wer` normalization.*
### Comparison with other systems
On the same 124 real-world samples, the finetuned Ukrainian HTR-ConvText model (`ukr-htr-convtext`) was compared against several vision–language and HTR baselines.
| Model | Samples | CER (%) | WER (%) |
|-------------------------|:-------:|--------:|--------:|
| mamay | 124 | 40.15 | 75.28 |
| finetuned-cyrillic-trocr| 124 | 46.45 | 78.96 |
| cyrillic-trocr | 124 | 51.92 | 97.93 |
| gpt-4o-mini | 124 | 56.19 | 88.75 |
| hunyuan | 124 | 124.80 | 180.78 |
| **ukr-htr-convtext (Ours)** | **124** | **17.63** | **44.04** |
Across this evaluation set, the proposed `ukr-htr-convtext` model more than halves the character error rate relative to the next best system (mamay) and strongly outperforms generic and domain-adapted VLM/HTR baselines.
## ⚠️ Limitations
- Sensitive to severe blur, low contrast, non-standard page artifacts
- Performance may drop on long lines far from training distribution
- CTC decoding can fail on highly ambiguous character boundaries
## 🙏 Attribution & Citation
This implementation adapts ideas from [DAIR-Group/HTR-ConvText](https://huggingface.co/DAIR-Group/HTR-ConvText). See `NOTICE` and `CITATION.cff` for details.
**Upstream (HTR-ConvText):**
```bibtex
@misc{truc2025htrconvtext,
title={HTR-ConvText: Leveraging Convolution and Textual Information for Handwritten Text Recognition},
author={Pham Thach Thanh Truc and Dang Hoai Nam and Huynh Tong Dang Khoa and Vo Nguyen Le Duy},
year={2025},
eprint={2512.05021},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.05021},
}
```
**This model:** See `CITATION.cff` for full attribution.
## 📄 License
Apache-2.0. See `LICENSE`.