# 🇺🇦 Українська OCR / ICR модель (HTR-ConvText)
**Розпізнавання рукописного та друкованого тексту українською**
[](https://huggingface.co/spaces/Valerii02/ukr-htr-convtext-demo)
*Завантажте зображення → Отримайте розпізнаний текст*
[English](README.md) · Українська
## 📋 Зміст
- [✨ Можливості](#можливості)
- [🚀 Швидкий старт](#швидкий-старт)
- [📖 Опис моделі](#опис-моделі)
- [🖼️ Приклади розпізнавання](#приклади-розпізнавання)
- [🛠️ Інструменти](#інструменти)
- [📊 Оцінка](#оцінка)
- [🙏 Атрибуція](#атрибуція)
## ✨ Можливості
| Параметр | Опис |
|----------|------|
| **Мова** | Українська (рукопис + друк) |
| **Архітектура** | HTR-ConvText (ResNet-18 + MobileViT), CTC декодування |
| **Вхід** | 64×3072 px, grayscale зображення рядків |
| **Тренування** | 1.7M зразків, SAM, EMA, scan simulation |
| **Формати** | PyTorch, ONNX, Hugging Face `AutoModel` |
## 🚀 Швидкий старт
```python
from transformers import AutoModel, AutoProcessor
processor = AutoProcessor.from_pretrained("Valerii02/ukr-htr-convtext", trust_remote_code=True)
model = AutoModel.from_pretrained("Valerii02/ukr-htr-convtext", trust_remote_code=True)
```
```python
inputs = processor(images="sample.png", return_tensors="pt")
logits = model(**inputs).logits
text = processor.batch_decode(logits)[0]
print(text)
```
> 💡 **Спробуйте зараз:** [Відкрити Gradio демо](https://huggingface.co/spaces/Valerii02/ukr-htr-convtext-demo) — код не потрібен!
## 📖 Опис моделі
Цей репозиторій пакує **українську OCR/ICR модель** для рукописного та частково друкованого тексту у форматі Hugging Face (`AutoModel` + `AutoProcessor`).
### Архітектура
- **Backbone:** ResNet-18 + MobileViT (MVP), ієрархічний ConvText encoder
- **Декодування:** CTC greedy
- **Словник:** 151 символ (українська + символи)
### Дані для тренування
| Джерело | Зразки |
|---------|--------|
| [ukrainian-handwriting-synth](https://github.com/ValeriiSielikhov/ukrainian-handwriting-synth) | Скрипт на GitHub для генерації датасету синтетичного рукопису |
| [Ukrainian Handwritten Text](https://www.kaggle.com/datasets/annyhnatiuk/ukrainian-handwritten-text) | Датасет на Kaggle, ~37k рядків |
| **Всього** | **1,696,499** (Train 90% / Val 5% / Test 5%) |
### Тренування
- 500k ітерацій, batch 16 + grad accum 4
- SAM optimizer, EMA (decay 0.9999), TCM warmup 40k iters
- Scan simulation та detector-error аугментації
- Hardware: NVIDIA B200 (180GB VRAM)
## 🖼️ Приклади розпізнавання
| Приклад | Зображення | GT | Prediction | CER | WER |
|---------|------------|----|------------|-----|-----|
| 1 |  | Департаменту патрульної поліції | Департаменту нагрульної поліції | 0.065 | 0.33 |
| 2 | 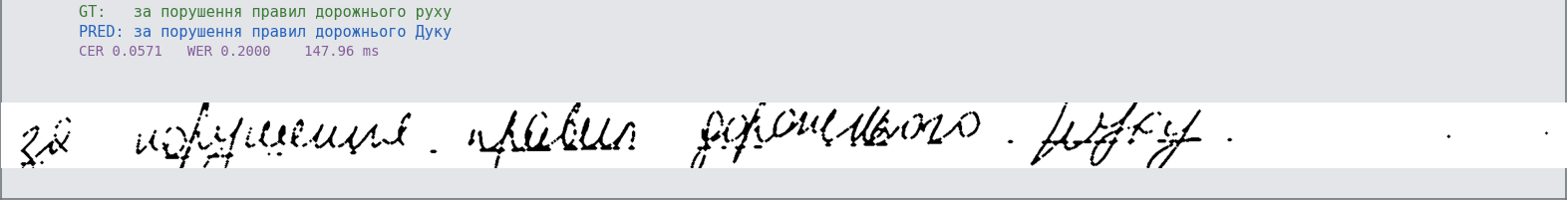 | за порушення правил дорожнього руху | за порушення правил дорожнього Дуку | 0.057 | 0.20 |
*Інференс на реальних сканах українських документів. GT = еталонний текст.*
## 🛠️ Інструменти
| Файл | Призначення |
|------|-------------|
| `prepare_hf_artifacts.py` | Конвертація `.pth` → HF артефакти |
| `export_onnx.py` | Експорт в ONNX |
| `validate_parity.py` | Перевірка паритету OpenCV vs PIL, PyTorch vs ONNX |
| `predict.py` | CLI інференс для одного зображення |
### Конвертація
```bash
python prepare_hf_artifacts.py \
--checkpoint-path /path/to/best_CER.pth \
--alphabet-path /path/to/alphabet.json \
--output-dir ./release
```
### Експорт ONNX
```bash
python export_onnx.py --hf-model-dir ./release --output-dir ./onnx
```
## 📊 Оцінка
| Split | CER | WER | Примітки |
|---|---:|---:|---|
| real-world (124) | 0.176 | 0.440 | Скани документів (рукопис + друк) |
### Порівняння з іншими системами
На тих самих 124 реальних зразках finetuned українська версія HTR-ConvText (`ukr-htr-convtext`) була порівняна з кількома VLM та HTR-бейслайнами.
| Модель | Зразки | CER (%) | WER (%) |
|---------------------------|:------:|--------:|--------:|
| mamay | 124 | 40.15 | 75.28 |
| finetuned-cyrillic-trocr | 124 | 46.45 | 78.96 |
| cyrillic-trocr | 124 | 51.92 | 97.93 |
| gpt-4o-mini | 124 | 56.19 | 88.75 |
| hunyuan | 124 | 124.80 | 180.78 |
| **ukr-htr-convtext (Ours)** | **124** | **17.63** | **44.04** |
На цьому наборі `ukr-htr-convtext` суттєво випереджає всі порівнювані моделі, більш ніж удвічі зменшуючи CER відносно найближчого конкурента (mamay) та демонструючи кращу якість за спеціалізовані й доменно-адаптовані VLM/HTR системи.
## ⚠️ Обмеження
- Складні артефакти скану, сильний blur, дуже низький контраст знижують якість
- Можливе падіння якості на рядках, що сильно відрізняються від train-розподілу
- CTC декодування має обмеження на неоднозначних межах символів
## 🙏 Атрибуція
Реалізація адаптує ідеї з [DAIR-Group/HTR-ConvText](https://huggingface.co/DAIR-Group/HTR-ConvText). Деталі дивись у `NOTICE` та `CITATION.cff`.
## 📄 Ліцензія
Apache-2.0. Див. `LICENSE`.