---
base_model:
- OpenGVLab/InternVL2_5-8B
datasets:
- lmms-lab/RefCOCO
- lmms-lab/RefCOCOplus
- lmms-lab/RefCOCOg
- qixiangbupt/grefcoco
language:
- en
license: mit
metrics:
- accuracy
pipeline_tag: image-segmentation
tags:
- Visual Grounding
- Referring Expression Segmentation
- Generalized Referring Expression Segmentation
- Referring Expression Comprehension
new_version: jcwang0602/MLLMSeg_InternVL2_5_8B_RES
library_name: transformers
---
# MLLMSeg: Unlocking the Potential of MLLMs in Referring Expression Segmentation via a Light-weight Mask Decoder
This repository contains the `MLLMSeg_InternVL2_5_8B_RES` model presented in the paper [Unlocking the Potential of MLLMs in Referring Expression Segmentation via a Light-weight Mask Decoder](https://huggingface.co/papers/2508.04107).
**Abstract:**
Reference Expression Segmentation (RES) aims to segment image regions specified by referring expressions and has become popular with the rise of multimodal large models (MLLMs). While MLLMs excel in semantic understanding, their token-generation paradigm struggles with pixel-level dense prediction. Existing RES methods either couple MLLMs with the parameter-heavy Segment Anything Model (SAM) with 632M network parameters or adopt SAM-free lightweight pipelines that sacrifice accuracy. To address the trade-off between performance and cost, we specifically propose MLLMSeg, a novel framework that fully exploits the inherent visual detail features encoded in the MLLM vision encoder without introducing an extra visual encoder. Besides, we propose a detail-enhanced and semantic-consistent feature fusion module (DSFF) that fully integrates the detail-related visual feature with the semantic-related feature output by the large language model (LLM) of MLLM. Finally, we establish a light-weight mask decoder with only 34M network parameters that optimally leverages detailed spatial features from the visual encoder and semantic features from the LLM to achieve precise mask prediction. Extensive experiments demonstrate that our method generally surpasses both SAM-based and SAM-free competitors, striking a better balance between performance and cost.
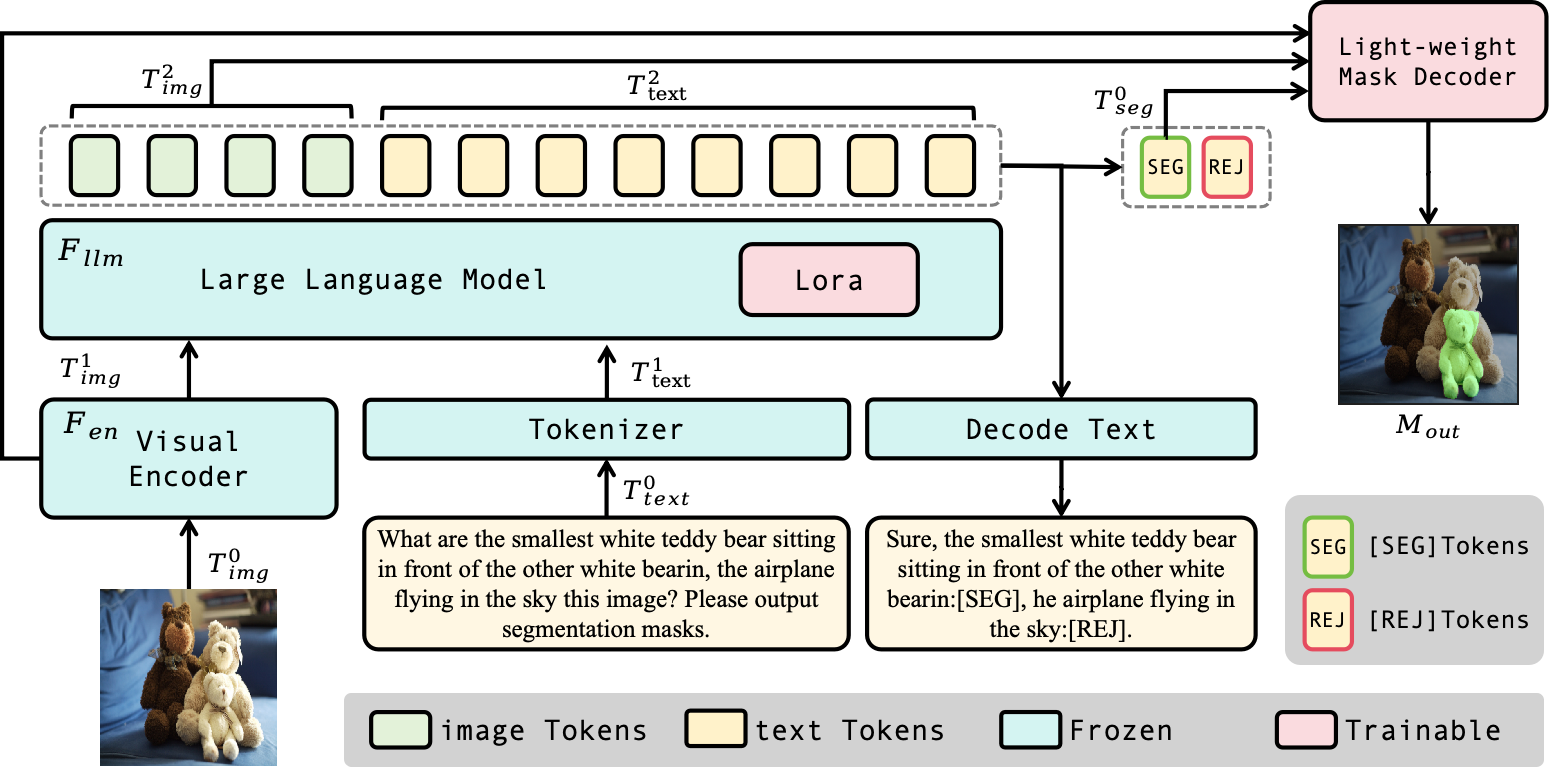 **Code:** Find the official implementation and full details on GitHub: [https://github.com/jcwang0602/MLLMSeg](https://github.com/jcwang0602/MLLMSeg)
**ArXiv:** [http://arxiv.org/abs/2508.04107](http://arxiv.org/abs/2508.04107)
---
## Quick Start
This section provides instructions on how to inference our pre-trained models.
**Notes:** Our models accept images of any size as input. The model outputs are normalized to relative coordinates within a 0-1000 range (either a center point or a bounding box defined by top-left and bottom-right coordinates). For visualization, please remember to convert these relative coordinates back to the original image dimensions.
### Installation
First, install the `transformers` library and other necessary dependencies as specified by the original repository:
```bash
conda create -n mllmseg python==3.10.18 -y
conda activate mllmseg
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu118
# If you encounter any problems during the installation of datasets, please install this first.
# conda install -c conda-forge pyarrow
pip install -r requirements.txt
pip install flash-attn==2.3.6 --no-build-isolation # Note: need gpu to install
```
## Performance Metrics
### Referring Expression Segmentation
**Code:** Find the official implementation and full details on GitHub: [https://github.com/jcwang0602/MLLMSeg](https://github.com/jcwang0602/MLLMSeg)
**ArXiv:** [http://arxiv.org/abs/2508.04107](http://arxiv.org/abs/2508.04107)
---
## Quick Start
This section provides instructions on how to inference our pre-trained models.
**Notes:** Our models accept images of any size as input. The model outputs are normalized to relative coordinates within a 0-1000 range (either a center point or a bounding box defined by top-left and bottom-right coordinates). For visualization, please remember to convert these relative coordinates back to the original image dimensions.
### Installation
First, install the `transformers` library and other necessary dependencies as specified by the original repository:
```bash
conda create -n mllmseg python==3.10.18 -y
conda activate mllmseg
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu118
# If you encounter any problems during the installation of datasets, please install this first.
# conda install -c conda-forge pyarrow
pip install -r requirements.txt
pip install flash-attn==2.3.6 --no-build-isolation # Note: need gpu to install
```
## Performance Metrics
### Referring Expression Segmentation
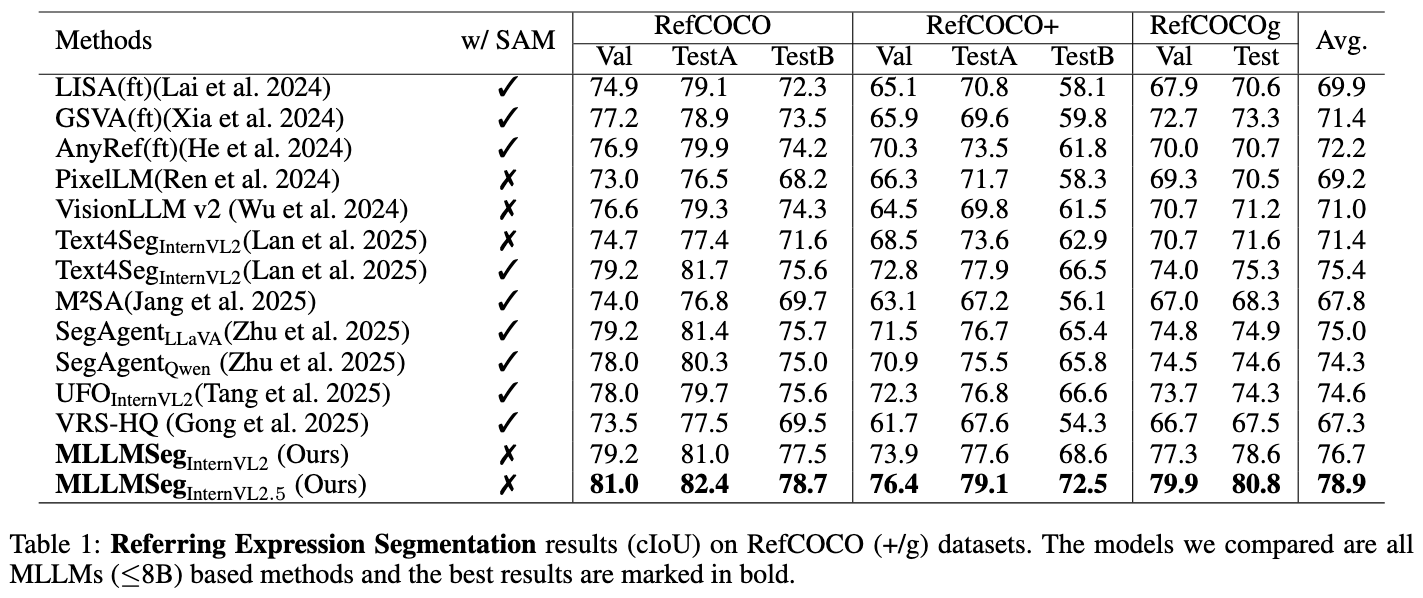 ### Referring Expression Comprehension
### Referring Expression Comprehension
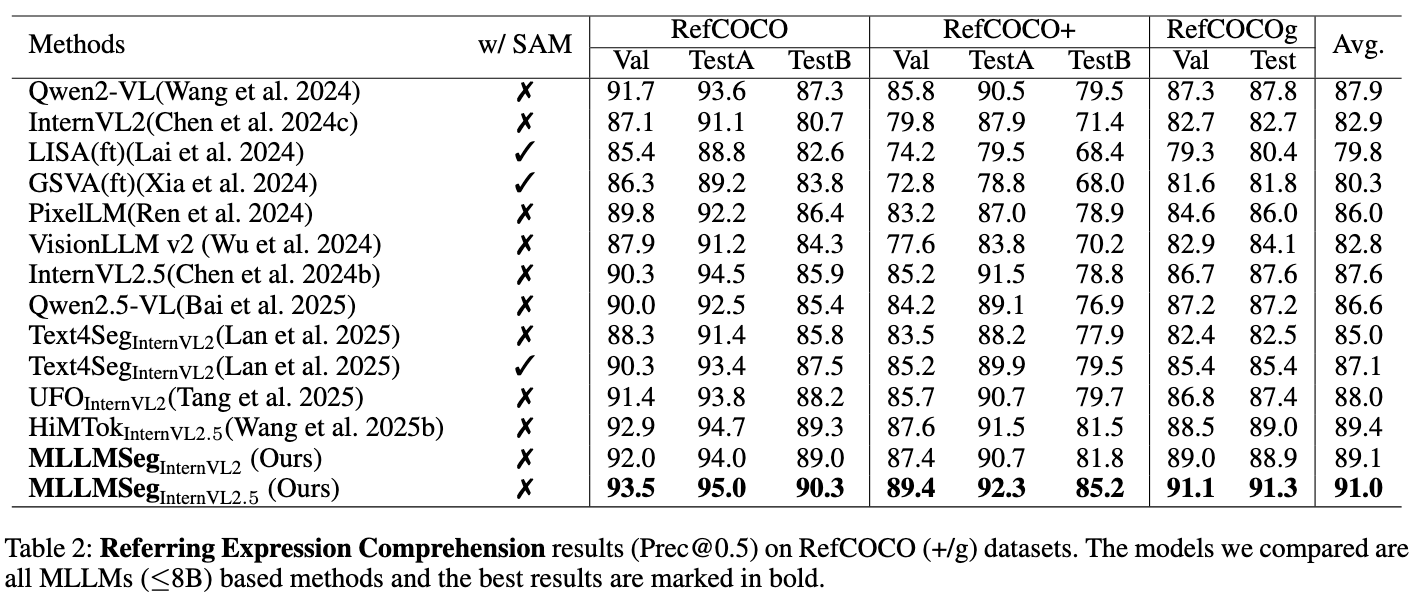 ### Generalized Referring Expression Segmentation
### Generalized Referring Expression Segmentation
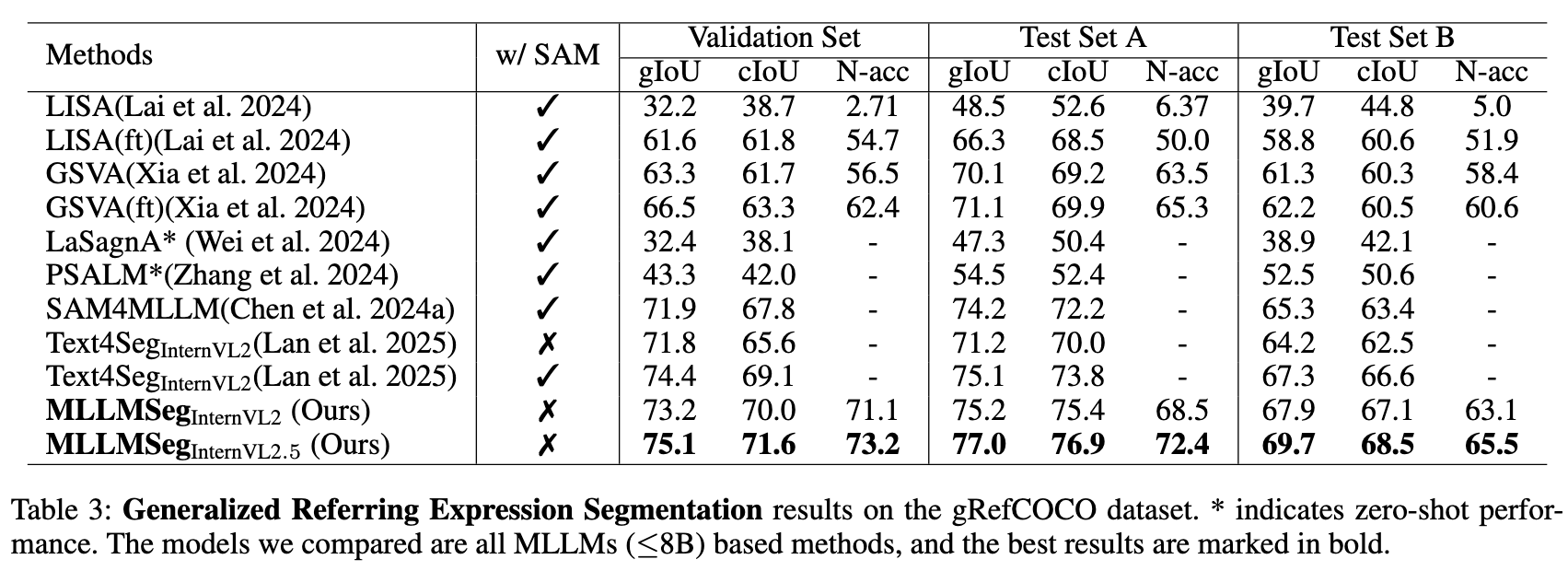 ---
## Visualization
### Referring Expression Segmentation
---
## Visualization
### Referring Expression Segmentation
 ### Referring Expression Comprehension
### Referring Expression Comprehension
 ### Generalized Referring Expression Segmentation
### Generalized Referring Expression Segmentation
 ---
## Citation
If our work is useful for your research, please consider citing:
```bibtex
@misc{wang2025unlockingpotentialmllmsreferring,
title={Unlocking the Potential of MLLMs in Referring Expression Segmentation via a Light-weight Mask Decoder},
author={Jingchao Wang and Zhijian Wu and Dingjiang Huang and Yefeng Zheng and Hong Wang},
year={2025},
eprint={2508.04107},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.04107},
}
```
---
## Citation
If our work is useful for your research, please consider citing:
```bibtex
@misc{wang2025unlockingpotentialmllmsreferring,
title={Unlocking the Potential of MLLMs in Referring Expression Segmentation via a Light-weight Mask Decoder},
author={Jingchao Wang and Zhijian Wu and Dingjiang Huang and Yefeng Zheng and Hong Wang},
year={2025},
eprint={2508.04107},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.04107},
}
```