🤗 HF Models |
📕 Blog Post |
📜 Technical Report
## 🔥 News
- ✨`2025/05/23`: Published a [blog post](https://tech.kakao.com/posts/707) about `Kanana 1.5` models and released 🤗[HF model weights](https://kko.kakao.com/kananallm).
- 📜`2025/02/27`: Released [Technical Report](https://arxiv.org/abs/2502.18934) and 🤗[HF model weights](https://huggingface.co/collections/kakaocorp/kanana-nano-21b-67a326cda1c449c8d4172259).
- 📕`2025/01/10`: Published a [blog post](https://tech.kakao.com/posts/682) about the development of `Kanana Nano` model.
- 📕`2024/11/14`: Published blog posts ([pre-training](https://tech.kakao.com/posts/661), [post-training](https://tech.kakao.com/posts/662)) about the development of `Kanana` models.
- ▶️`2024/11/06`: Published a [presentation video](https://youtu.be/HTBl142x9GI?si=o_we6t9suYK8DfX3) about the development of the `Kanana` models.
## Table of Contents
- [Kanana 1.5](#kanana-15)
- [Performance](#performance)
- [Kanana 1.5 Base Models](#kanana-15-base-models)
- [Kanana 1.5 Instruct Models](#kanana-15-instruct-models)
- [Long Context](#long-context)
- [Processing 32K+ Length](#processing-32k-length)
- [Kanana 1.0](#kanana-10)
- [License](#license)
- [Citation](#citation)
- [Contributors](#contributors)
- [Contact](#contact)
## Kanana 1.5
`Kanana 1.5`, a newly introduced version of the Kanana model family, presents substantial enhancements in **coding, mathematics, and function calling capabilities** over the previous version, enabling broader application to more complex real-world problems. This new version now can handle __up to 32K tokens length natively and up to 128K tokens using YaRN__, allowing the model to maintain coherence when handling extensive documents or engaging in extended conversations. Furthermore, Kanana 1.5 delivers more natural and accurate conversations through a __refined post-training process__.
> [!Note]
> Neither the pre-training nor the post-training data includes Kakao user data.
### Performance
#### Kanana 1.5 Base Models
Models
MMLU
KMMLU
HAERAE
HumanEval
MBPP
GSM8K
Kanana-Flag-1.5-32.5B
76.76
61.90
89.18
73.17
65.60
81.50
Kanana-Flag-32.5B
77.68
62.10
90.47
51.22
63.40
70.05
Kanana-Essence-1.5-9.8B
68.27
52.78
86.34
64.63
61.60
71.57
Kanana-Essence-9.8B
67.61
50.57
84.97
40.24
53.60
63.61
Kanana-1.5-8B
64.24
48.94
82.77
61.59
57.80
63.53
Kanana-8B
64.22
48.30
83.41
40.24
51.40
57.09
Kanana-Nano-1.5-3B
59.23
47.30
78.00
46.34
46.80
61.79
Kanana-1.5-2.1B
56.30
45.10
77.46
52.44
47.00
55.95
Kanana-Nano-2.1B
54.83
44.80
77.09
31.10
46.20
46.32
#### Kanana 1.5 Instruct Models
Models
MT-Bench
KoMT-Bench
IFEval
HumanEval+
MBPP+
GSM8K (0-shot)
MATH
MMLU (0-shot, CoT)
KMMLU (0-shot, CoT)
FunctionChatBench
Kanana-Flag-1.5-32.5B
8.13
8.12
82.70
79.88
71.96
93.03
75.96
82.76
64.10
67.17
Kanana-Flag-32.5B
8.33
8.03
84.59
78.66
69.84
91.66
58.08
81.08
64.19
65.67
Kanana-Essence-1.5-9.8B
7.88
7.35
76.34
72.56
66.93
90.07
62.02
72.85
52.00
51.43
Kanana-Essence-9.8B
7.81
7.65
80.20
72.56
68.52
84.91
42.24
70.64
50.76
26.77
Kanana-1.5-8B*
7.76
7.63
80.11
76.83
67.99
87.64
67.54
68.82
48.28
58.00
Kanana-8B
7.13
6.92
76.91
62.20
43.92
79.23
37.68
66.50
47.43
17.37
Kanana-Nano-1.5-3B
7.01
6.52
70.08
70.73
64.29
80.36
56.70
59.69
37.60
55.37
Kanana-1.5-2.1B*
7.01
6.54
68.61
68.90
65.08
81.43
60.62
53.87
32.93
53.70
Kanana-Nano-2.1B
6.40
5.90
71.97
63.41
62.43
72.32
29.26
52.48
38.51
26.10
> \* Models released under the Apache 2.0 license have been trained on more recent data compared to other models.
#### Long Context
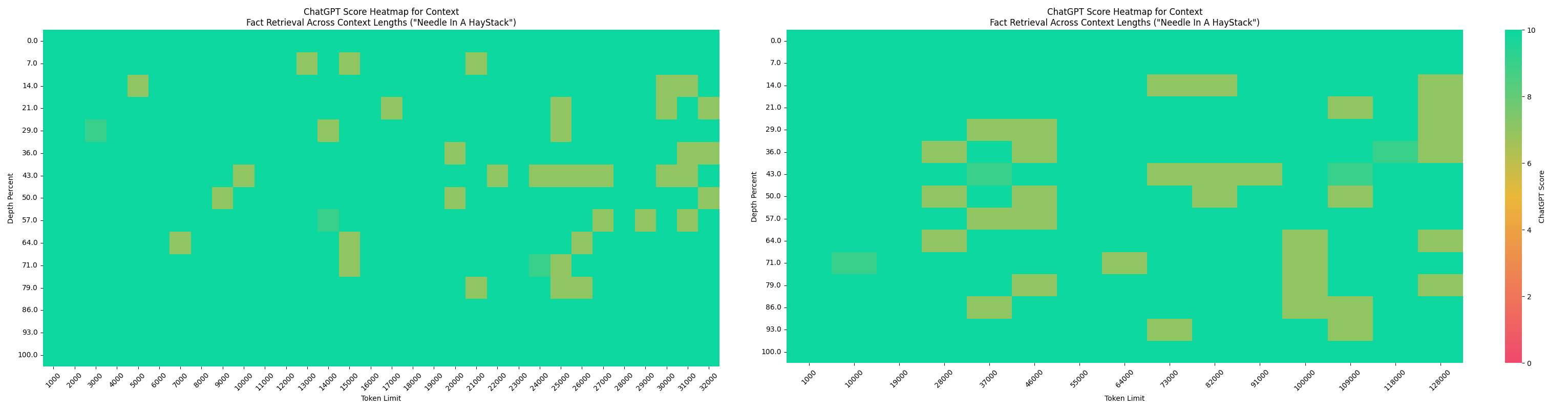
##### Kanana-1.5-32.5B-Base
Below is a Needle-in-a-Haystack performance of `Kanana-1.5-32.5B-Base` model which was trained on a target context length of 32K.
- (left): evaluated with native 32K context length
- (right): extended to 128K context length using YaRN
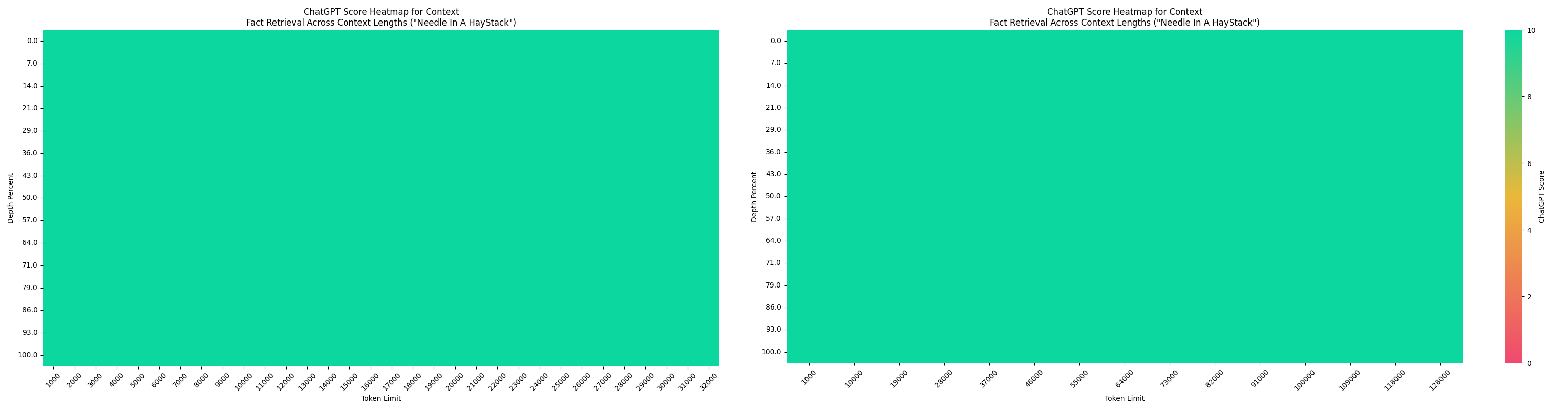
##### Kanana-1.5-32.5B-Instruct
Below is a Needle-in-a-Haystack performance of `Kanana-1.5-32.5B-Instruct` model which was trained on a target context length of 32K.
- (left): evaluated with native 32K context length
- (right): extended to 128K context length using YaRN
#### Processing 32K+ Length
Currently, the `config.json` uploaded to HuggingFace is configured for token lengths of 32,768 or less. To process tokens beyond this length, YaRN must be applied. By updating the `config.json` with the following parameters, you can apply YaRN to handle token sequences up to 128K in length:
```json
"rope_scaling": {
"factor": 4.4,
"original_max_position_embeddings": 32768,
"type": "yarn",
"beta_fast": 64,
"beta_slow": 2
},
```
## Kanana 1.0
### Kanana 1.0 Introduction
View the details about Kanana 1.0
We introduce Kanana, a series of bilingual language models (developed by [Kakao](https://github.com/kakao)) that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high-quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, function calling, and Retrieval Augmented Generation (RAG). The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding, function call, and RAG) publicly released to promote research on Korean language models.
> Neither the pre-training nor the post-training data includes Kakao user data.
### Kanana 1.0 Models Performance
View detailed performance of Kanana 1.0 models
Below are partial report on the performance of the `Kanana` model series. Please refer to the [Technical Report](https://arxiv.org/abs/2502.18934) for the full results.
#### Pre-trained Model Performance
Models
MMLU
KMMLU
HAERAE
HumanEval
MBPP
GSM8K
27b+ scale
Kanana-Flag-32.5b
77.68
62.10
90.47
51.22
63.40
70.05
Qwen2.5-32b
83.10
63.15
75.16
50.00
73.40
82.41
Gemma-2-27b
75.45
51.16
69.11
51.22
64.60
74.37
EXAONE-3.5-32b
72.68
46.36
82.22
-
-
-
Aya-Expanse-32b
74.52
49.57
80.66
-
-
-
7b+ scale
Kanana-Essence-9.8b
67.61
50.57
84.98
40.24
53.60
63.61
Llama-3.1-8b
65.18
41.02
61.78
35.37
48.60
50.87
Qwen2.5-7b
74.19
51.68
67.46
56.71
63.20
83.85
Gemma-2-9b
70.34
48.18
66.18
37.20
53.60
68.16
EXAONE-3.5-7.8b
65.36
45.30
77.54
-
-
-
Aya-Expanse-8b
62.52
40.11
71.95
-
-
-
2b+ scale
Kanana-Nano-2.1b
54.83
44.80
77.09
31.10
46.20
46.32
Llama-3.2-3b
56.40
35.57
47.66
25.61
39.00
27.37
Qwen2.5-3b
65.57
45.28
61.32
37.80
55.60
69.07
Gemma-2-2b
52.89
30.67
45.55
20.12
28.20
24.72
EXAONE-3.5-2.4b
59.27
43.58
69.65
-
-
-
70b+ scale
Llama-3.1-70b
78.93
53.00
76.35
57.32
66.60
81.73
Qwen2.5-72b
86.12
68.57
80.84
55.49
76.40
92.04
#### Post-trained Model Performance
##### Instruction-following Benchmarks
Models
MT-Bench
LogicKor
KoMT-Bench
WildBench
IFEval
27b+ scale
Kanana-Flag-32.5b
8.356
9.524
8.058
54.14
0.856
Qwen2.5-32b
8.331
8.988
7.847
51.13
0.822
Gemma-2-27b
8.088
8.869
7.373
46.46
0.817
EXAONE-3.5-32b
8.375
9.202
7.907
54.30
0.845
Aya-Expanse-32b
7.788
8.941
7.626
48.36
0.735
7b+ scale
Kanana-Essence-9.8b
7.769
8.964
7.706
47.27
0.799
Llama-3.1-8b
7.500
6.512
5.336
33.20
0.772
Qwen2.5-7b
7.625
7.952
6.808
41.31
0.760
Gemma-2-9b
7.633
8.643
7.029
40.92
0.750
EXAONE-3.5-7.8b
8.213
9.357
8.013
50.98
0.826
Aya-Expanse-8b
7.131
8.357
7.006
38.50
0.645
2b+ scale
Kanana-Nano-2.1b
6.400
7.964
5.857
25.41
0.720
Llama-3.2-3b
7.050
4.452
3.967
21.91
0.767
Qwen2.5-3b
6.969
6.488
5.274
25.76
0.355
Gemma-2-2b
7.225
5.917
4.835
28.71
0.428
EXAONE-3.5-2.4b
7.919
8.941
7.223
41.68
0.790
70b+ scale
Llama-3.1-70b
8.275
8.250
6.970
46.50
0.875
Qwen2.5-72b
8.619
9.214
8.281
55.25
0.861
##### General Benchmarks
Models
MMLU
KMMLU
HAE-RAE
HumanEval+
MBPP+
GSM8K
MATH
27b+ scale
Kanana-Flag-32.5b
81.08
64.19
68.18
77.44
69.84
90.83
57.82
Qwen2.5-32b
84.40
59.37
48.30
82.32
71.96
95.30
81.90
Gemma-2-27b
78.01
49.98
46.02
70.12
70.90
91.05
53.80
EXAONE-3.5-32b
78.30
55.44
52.27
78.66
70.90
93.56
76.80
Aya-Expanse-32b
74.49
42.35
51.14
64.63
65.61
75.06
42.82
7b+ scale
Kanana-Essence-9.8b
70.64
50.76
47.16
72.56
69.05
84.91
42.24
Llama-3.1-8b
71.18
39.24
40.91
60.98
57.67
82.71
49.86
Qwen2.5-7b
77.23
46.87
37.50
73.78
70.63
91.58
75.22
Gemma-2-9b
73.47
44.47
39.77
59.76
64.55
87.72
48.10
EXAONE-3.5-7.8b
72.62
52.09
46.02
79.27
66.67
89.99
73.50
Aya-Expanse-8b
61.23
35.78
39.20
42.68
56.88
78.85
30.80
2b+ scale
Kanana-Nano-2.1b
52.48
38.51
33.52
63.41
62.43
72.32
29.26
Llama-3.2-3b
56.09
3.07
17.05
56.71
50.26
66.57
38.18
Qwen2.5-3b
69.18
38.33
32.39
67.68
64.02
84.00
65.72
Gemma-2-2b
57.69
6.99
7.95
35.37
45.24
49.81
21.68
EXAONE-3.5-2.4b
63.19
14.27
14.20
70.73
59.79
83.78
64.04
70b+ scale
Llama-3.1-70b
83.48
39.08
53.41
75.61
66.40
91.66
63.98
Qwen2.5-72b
87.14
65.78
60.80
81.10
75.66
95.45
82.60
#### Embedding Model Performance
Backbone
Kanana-Nano-2.1b
Llama-3.2-3b
Qwen2.5-3b
Llama-3.2-1b
Qwen-2.5-1.5b
English
51.56
53.28
54.00
48.77
50.60
Korean
65.00
59.43
62.10
54.68
54.60
Avg.
58.28
56.35
58.05
51.73
52.60
## License
The `Kanana 1.5` models are licensed under [apache-2.0](./LICENSE).
## Citation
```
@misc{kananallmteam2025kananacomputeefficientbilinguallanguage,
title={Kanana: Compute-efficient Bilingual Language Models},
author={Kanana LLM Team and Yunju Bak and Hojin Lee and Minho Ryu and Jiyeon Ham and Seungjae Jung and Daniel Wontae Nam and Taegyeong Eo and Donghun Lee and Doohae Jung and Boseop Kim and Nayeon Kim and Jaesun Park and Hyunho Kim and Hyunwoong Ko and Changmin Lee and Kyoung-Woon On and Seulye Baeg and Junrae Cho and Sunghee Jung and Jieun Kang and EungGyun Kim and Eunhwa Kim and Byeongil Ko and Daniel Lee and Minchul Lee and Miok Lee and Shinbok Lee and Gaeun Seo},
year={2025},
eprint={2502.18934},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.18934},
}
```
## Contributors
- Language Model Training: Yunju Bak, Doohae Jung, Boseop Kim, Nayeon Kim, Hojin Lee, Jaesun Park, Minho Ryu
- Language Model Alignment: Jiyeon Ham, Seungjae Jung, Hyunho Kim, Hyunwoong Ko, Changmin Lee, Daniel Wontae Nam
- AI Engineering: Youmin Kim, Hyeongju Kim
Contributors for Kanana 1.0
- Pre-training: Yunju Bak, Doohae Jung, Boseop Kim, Nayeon Kim, Hojin Lee, Jaesun Park, Minho Ryu
- Post-training: Jiyeon Ham, Seungjae Jung, Hyunho Kim, Hyunwoong Ko, Changmin Lee, Daniel Wontae Nam, Kyoung-Woon On
- Adaptation: Seulye Baeg, Junrae Cho, Taegyeong Eo, Sunghee Jung, Jieun Kang, EungGyun Kim, Eunhwa Kim, Byeongil Ko, Daniel Lee, Donghun Lee, Minchul Lee, Miok Lee, Shinbok Lee, Minho Ryu, Gaeun Seo
## Contact
- Kanana LLM Team Technical Support: kanana-llm@kakaocorp.com
- Business & Partnership Contact: alpha.k@kakaocorp.com