
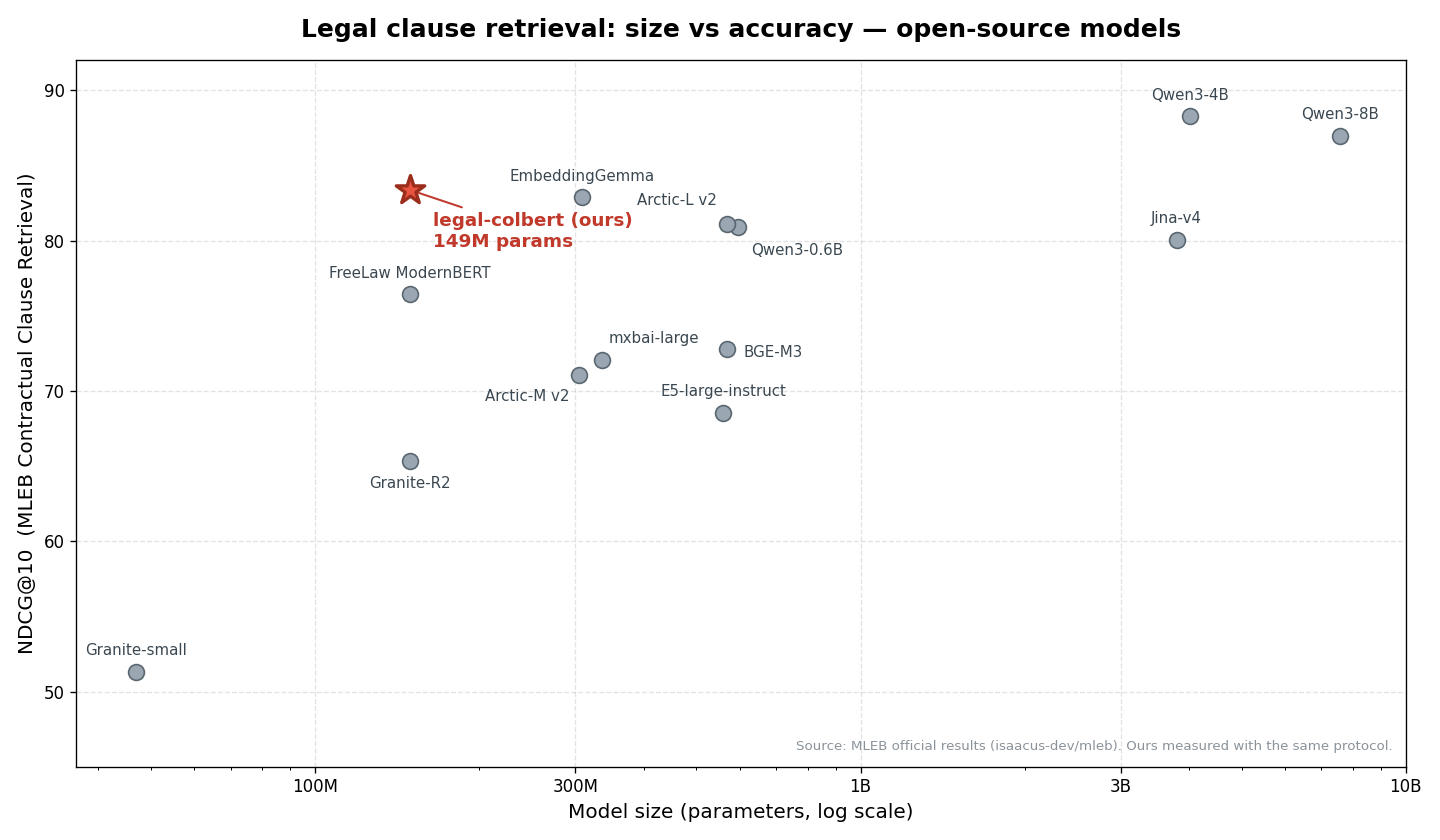
Add legal-colbert clause retriever (P6b): MLEB Contractual Clause Retrieval 0.8338 NDCG@10
Browse files- 1_Dense/config.json +7 -0
- 1_Dense/model.safetensors +3 -0
- README.md +122 -0
- clause_size_vs_ndcg.png +0 -0
- config.json +78 -0
- config_sentence_transformers.json +53 -0
- model.safetensors +3 -0
- modules.json +14 -0
- sentence_bert_config.json +4 -0
- tokenizer.json +0 -0
- tokenizer_config.json +23 -0
1_Dense/config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"in_features": 768,
|
| 3 |
+
"out_features": 128,
|
| 4 |
+
"bias": false,
|
| 5 |
+
"activation_function": "torch.nn.modules.linear.Identity",
|
| 6 |
+
"use_residual": false
|
| 7 |
+
}
|
1_Dense/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ee7db427970339c14df30f7eace1dbf1f5ba9a4224ad55e963a227b8f8410f82
|
| 3 |
+
size 393304
|
README.md
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-4.0
|
| 3 |
+
pipeline_tag: sentence-similarity
|
| 4 |
+
library_name: PyLate
|
| 5 |
+
base_model: lightonai/GTE-ModernColBERT-v1
|
| 6 |
+
datasets:
|
| 7 |
+
- theatticusproject/cuad-qa
|
| 8 |
+
- theatticusproject/acord
|
| 9 |
+
- coastalcph/lex_glue
|
| 10 |
+
language:
|
| 11 |
+
- en
|
| 12 |
+
tags:
|
| 13 |
+
- ColBERT
|
| 14 |
+
- PyLate
|
| 15 |
+
- late-interaction
|
| 16 |
+
- sentence-transformers
|
| 17 |
+
- feature-extraction
|
| 18 |
+
- legal
|
| 19 |
+
- contracts
|
| 20 |
+
- clause-retrieval
|
| 21 |
+
- retrieval
|
| 22 |
+
---
|
| 23 |
+
|
| 24 |
+
# legal-colbert-clause-retriever
|
| 25 |
+
|
| 26 |
+
A small, open **late-interaction (ColBERT)** retriever fine-tuned for **finding clauses in legal contracts** — termination, assignment, limitation of liability, IP ownership, non-compete, governing law, and ~35 other common provision types. It maps queries and contract passages to sequences of 128-d token vectors and scores them with the MaxSim operator.
|
| 27 |
+
|
| 28 |
+
It is a continuation fine-tune of [`lightonai/GTE-ModernColBERT-v1`](https://huggingface.co/lightonai/GTE-ModernColBERT-v1) (149M params, ModernBERT-base backbone).
|
| 29 |
+
|
| 30 |
+
## Results
|
| 31 |
+
|
| 32 |
+
Evaluated on the **[MLEB](https://isaacus.com/mleb) Contractual Clause Retrieval** task (NDCG@10), the published benchmark for legal contract clause retrieval. Our evaluation reproduces the official leaderboard protocol exactly (BGE-M3 scores 0.7281 through our harness, matching the leaderboard to 4 decimals).
|
| 33 |
+
|
| 34 |
+
| Metric | Score |
|
| 35 |
+
|---|---|
|
| 36 |
+
| **NDCG@10** | **0.8338** |
|
| 37 |
+
| MAP | 0.7713 |
|
| 38 |
+
| Recall@10 | 0.9556 |
|
| 39 |
+
|
| 40 |
+
**At 149M parameters this is the best accuracy-per-parameter open model on the task** — 3rd of 17 open-source models, ahead of Google's EmbeddingGemma (308M, 0.829) and the same-size legal peer Free Law ModernBERT (0.764), and behind only Qwen3-Embedding-4B/8B (which are 27–53× larger).
|
| 41 |
+
|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
## Usage
|
| 45 |
+
|
| 46 |
+
```bash
|
| 47 |
+
pip install pylate
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
from pylate import models, rank
|
| 52 |
+
|
| 53 |
+
model = models.ColBERT("kmad00/legal-colbert-clause-retriever")
|
| 54 |
+
|
| 55 |
+
# Describe the clause you want to find
|
| 56 |
+
queries = model.encode(
|
| 57 |
+
["This is a contractual provision that limits the maximum liability a party can incur."],
|
| 58 |
+
is_query=True,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
# Candidate contract passages
|
| 62 |
+
documents = model.encode(
|
| 63 |
+
[
|
| 64 |
+
"In no event shall either party's aggregate liability exceed the fees paid in the prior twelve months...",
|
| 65 |
+
"This Agreement shall be governed by the laws of the State of Delaware...",
|
| 66 |
+
],
|
| 67 |
+
is_query=False,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
scores = rank.rerank(
|
| 71 |
+
documents_ids=[["0", "1"]],
|
| 72 |
+
queries_embeddings=queries,
|
| 73 |
+
documents_embeddings=[documents],
|
| 74 |
+
)
|
| 75 |
+
print(scores)
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
Queries can be plain clause names (`"governing law"`), natural-language definitions, or questions — the model is robust to phrasing. Document length 300 tokens, query length 48, output dim 128, similarity = MaxSim.
|
| 79 |
+
|
| 80 |
+
## Supported clause types
|
| 81 |
+
|
| 82 |
+
Trained and evaluated on 41 CUAD clause categories plus ACORD drafting queries and LEDGAR provision labels, including: Cap on Liability / Uncapped Liability, IP Ownership Assignment, Joint IP Ownership, License Grant, Non-Compete, Anti-Assignment, Change of Control, Governing Law, Termination for Convenience, Renewal Term, Audit Rights, Insurance, Most Favored Nation, Exclusivity, Liquidated Damages, Source Code Escrow, ROFR/ROFO/ROFN, and more. As a retriever (not a fixed classifier) it also generalizes to clause types outside this set.
|
| 83 |
+
|
| 84 |
+
## License
|
| 85 |
+
|
| 86 |
+
**CC BY 4.0.** This model is a derivative of CC BY 4.0 training data (CUAD, ACORD, LEDGAR) and an Apache 2.0 base model. You may use it commercially and non-commercially; attribution is required (see below). No share-alike obligation applies.
|
| 87 |
+
|
| 88 |
+
## Base model
|
| 89 |
+
|
| 90 |
+
- [lightonai/GTE-ModernColBERT-v1](https://huggingface.co/lightonai/GTE-ModernColBERT-v1) — Apache 2.0 (← [Alibaba-NLP/gte-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-modernbert-base) ← [answerdotai/ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base))
|
| 91 |
+
|
| 92 |
+
## Training data
|
| 93 |
+
|
| 94 |
+
Produced by a chain of light continuation fine-tunes. Across the full lineage it was trained on the following datasets (and no others):
|
| 95 |
+
|
| 96 |
+
- **[CUAD](https://huggingface.co/datasets/theatticusproject/cuad-qa)** — CC BY 4.0. Hendrycks et al., "CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review," NeurIPS 2021. The Atticus Project.
|
| 97 |
+
- **[ACORD](https://huggingface.co/datasets/theatticusproject/acord)** — CC BY 4.0. The Atticus Project, "ACORD: An Expert-Annotated Retrieval Dataset for Legal Contract Drafting," 2025.
|
| 98 |
+
- **[LEDGAR](https://huggingface.co/datasets/coastalcph/lex_glue)** (LexGLUE `ledgar` config) — CC BY 4.0. Tuggener et al., "LEDGAR," LREC 2020; derived from public-domain US SEC EDGAR filings. Chalkidis et al., "LexGLUE," ACL 2022.
|
| 99 |
+
|
| 100 |
+
Hard negatives were mined with BM25 from each dataset's own corpus. **No MLEB / `isaacus/contractual-clause-retrieval` data and no web-scraped data were used in training** — MLEB is used only as an evaluation benchmark.
|
| 101 |
+
|
| 102 |
+
## Limitations
|
| 103 |
+
|
| 104 |
+
- English-language commercial contracts (US-style); other jurisdictions/languages are out of distribution.
|
| 105 |
+
- Late-interaction (multi-vector) storage is heavier per document than single-vector embedders.
|
| 106 |
+
- The MLEB clause task is small (90 docs); treat ±1–2 points as noise.
|
| 107 |
+
- Trained on a narrow set of clause types; confidence is lower on provision types far from the training taxonomy.
|
| 108 |
+
|
| 109 |
+
## Acknowledgments
|
| 110 |
+
|
| 111 |
+
- Training data: [The Atticus Project](https://www.atticusprojectai.org/) (CUAD, ACORD); Tuggener et al. & [coastalcph/LexGLUE](https://github.com/coastalcph/lex-glue) (LEDGAR).
|
| 112 |
+
- Base model: [LightOn](https://huggingface.co/lightonai) (GTE-ModernColBERT-v1), built with [PyLate](https://github.com/lightonai/pylate).
|
| 113 |
+
- Benchmark: [Isaacus](https://isaacus.com/mleb) (MLEB) — evaluation only, not training.
|
| 114 |
+
|
| 115 |
+
## Full model architecture
|
| 116 |
+
|
| 117 |
+
```
|
| 118 |
+
ColBERT(
|
| 119 |
+
(0): Transformer({'max_seq_length': 299, 'architecture': 'ModernBertModel'})
|
| 120 |
+
(1): Dense({'in_features': 768, 'out_features': 128, 'bias': False, 'activation_function': 'Identity'})
|
| 121 |
+
)
|
| 122 |
+
```
|
clause_size_vs_ndcg.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"ModernBertModel"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 50281,
|
| 8 |
+
"classifier_activation": "gelu",
|
| 9 |
+
"classifier_bias": false,
|
| 10 |
+
"classifier_dropout": 0.0,
|
| 11 |
+
"classifier_pooling": "mean",
|
| 12 |
+
"cls_token_id": 50281,
|
| 13 |
+
"decoder_bias": true,
|
| 14 |
+
"deterministic_flash_attn": false,
|
| 15 |
+
"dtype": "float32",
|
| 16 |
+
"embedding_dropout": 0.0,
|
| 17 |
+
"eos_token_id": 50282,
|
| 18 |
+
"global_attn_every_n_layers": 3,
|
| 19 |
+
"gradient_checkpointing": false,
|
| 20 |
+
"hidden_activation": "gelu",
|
| 21 |
+
"hidden_size": 768,
|
| 22 |
+
"initializer_cutoff_factor": 2.0,
|
| 23 |
+
"initializer_range": 0.02,
|
| 24 |
+
"intermediate_size": 1152,
|
| 25 |
+
"layer_norm_eps": 1e-05,
|
| 26 |
+
"layer_types": [
|
| 27 |
+
"full_attention",
|
| 28 |
+
"sliding_attention",
|
| 29 |
+
"sliding_attention",
|
| 30 |
+
"full_attention",
|
| 31 |
+
"sliding_attention",
|
| 32 |
+
"sliding_attention",
|
| 33 |
+
"full_attention",
|
| 34 |
+
"sliding_attention",
|
| 35 |
+
"sliding_attention",
|
| 36 |
+
"full_attention",
|
| 37 |
+
"sliding_attention",
|
| 38 |
+
"sliding_attention",
|
| 39 |
+
"full_attention",
|
| 40 |
+
"sliding_attention",
|
| 41 |
+
"sliding_attention",
|
| 42 |
+
"full_attention",
|
| 43 |
+
"sliding_attention",
|
| 44 |
+
"sliding_attention",
|
| 45 |
+
"full_attention",
|
| 46 |
+
"sliding_attention",
|
| 47 |
+
"sliding_attention",
|
| 48 |
+
"full_attention"
|
| 49 |
+
],
|
| 50 |
+
"local_attention": 128,
|
| 51 |
+
"max_position_embeddings": 8192,
|
| 52 |
+
"mlp_bias": false,
|
| 53 |
+
"mlp_dropout": 0.0,
|
| 54 |
+
"model_type": "modernbert",
|
| 55 |
+
"norm_bias": false,
|
| 56 |
+
"norm_eps": 1e-05,
|
| 57 |
+
"num_attention_heads": 12,
|
| 58 |
+
"num_hidden_layers": 22,
|
| 59 |
+
"pad_token_id": 50283,
|
| 60 |
+
"position_embedding_type": "absolute",
|
| 61 |
+
"repad_logits_with_grad": false,
|
| 62 |
+
"rope_parameters": {
|
| 63 |
+
"full_attention": {
|
| 64 |
+
"rope_theta": 160000.0,
|
| 65 |
+
"rope_type": "default"
|
| 66 |
+
},
|
| 67 |
+
"sliding_attention": {
|
| 68 |
+
"rope_theta": 10000.0,
|
| 69 |
+
"rope_type": "default"
|
| 70 |
+
}
|
| 71 |
+
},
|
| 72 |
+
"sep_token_id": 50282,
|
| 73 |
+
"sparse_pred_ignore_index": -100,
|
| 74 |
+
"sparse_prediction": false,
|
| 75 |
+
"tie_word_embeddings": true,
|
| 76 |
+
"transformers_version": "5.3.0",
|
| 77 |
+
"vocab_size": 50370
|
| 78 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "5.3.0",
|
| 4 |
+
"transformers": "5.3.0",
|
| 5 |
+
"pytorch": "2.9.0+cu128"
|
| 6 |
+
},
|
| 7 |
+
"prompts": {
|
| 8 |
+
"query": "",
|
| 9 |
+
"document": ""
|
| 10 |
+
},
|
| 11 |
+
"default_prompt_name": null,
|
| 12 |
+
"similarity_fn_name": "MaxSim",
|
| 13 |
+
"query_prefix": "[Q] ",
|
| 14 |
+
"document_prefix": "[D] ",
|
| 15 |
+
"query_length": 48,
|
| 16 |
+
"document_length": 300,
|
| 17 |
+
"attend_to_expansion_tokens": false,
|
| 18 |
+
"skiplist_words": [
|
| 19 |
+
"!",
|
| 20 |
+
"\"",
|
| 21 |
+
"#",
|
| 22 |
+
"$",
|
| 23 |
+
"%",
|
| 24 |
+
"&",
|
| 25 |
+
"'",
|
| 26 |
+
"(",
|
| 27 |
+
")",
|
| 28 |
+
"*",
|
| 29 |
+
"+",
|
| 30 |
+
",",
|
| 31 |
+
"-",
|
| 32 |
+
".",
|
| 33 |
+
"/",
|
| 34 |
+
":",
|
| 35 |
+
";",
|
| 36 |
+
"<",
|
| 37 |
+
"=",
|
| 38 |
+
">",
|
| 39 |
+
"?",
|
| 40 |
+
"@",
|
| 41 |
+
"[",
|
| 42 |
+
"\\",
|
| 43 |
+
"]",
|
| 44 |
+
"^",
|
| 45 |
+
"_",
|
| 46 |
+
"`",
|
| 47 |
+
"{",
|
| 48 |
+
"|",
|
| 49 |
+
"}",
|
| 50 |
+
"~"
|
| 51 |
+
],
|
| 52 |
+
"do_query_expansion": false
|
| 53 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3a7fc1eed36a0b343e0a80b5e262bf93b04cb49a20e9b6e79a11b2df3e9777db
|
| 3 |
+
size 596076280
|
modules.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Dense",
|
| 12 |
+
"type": "pylate.models.Dense.Dense"
|
| 13 |
+
}
|
| 14 |
+
]
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 299,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"backend": "tokenizers",
|
| 3 |
+
"clean_up_tokenization_spaces": true,
|
| 4 |
+
"cls_token": "[CLS]",
|
| 5 |
+
"is_local": true,
|
| 6 |
+
"mask_token": "[MASK]",
|
| 7 |
+
"max_length": 299,
|
| 8 |
+
"model_input_names": [
|
| 9 |
+
"input_ids",
|
| 10 |
+
"attention_mask"
|
| 11 |
+
],
|
| 12 |
+
"model_max_length": 299,
|
| 13 |
+
"pad_to_multiple_of": null,
|
| 14 |
+
"pad_token": "[MASK]",
|
| 15 |
+
"pad_token_type_id": 0,
|
| 16 |
+
"padding_side": "right",
|
| 17 |
+
"sep_token": "[SEP]",
|
| 18 |
+
"stride": 0,
|
| 19 |
+
"tokenizer_class": "TokenizersBackend",
|
| 20 |
+
"truncation_side": "right",
|
| 21 |
+
"truncation_strategy": "longest_first",
|
| 22 |
+
"unk_token": "[UNK]"
|
| 23 |
+
}
|