---
language:
- jpn
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:12451
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
base_model: sbintuitions/sarashina-embedding-v2-1b
widget:
- source_sentence: 草原で2頭のシマウマが草を食べています。
sentences:
- 芝の上に5体象のオブジェが置いてあります。
- テーブルトップが大理石になってる台所です。
- 草地にシマウマが二頭並んで草を食べています。
- source_sentence: 三匹のシマウマが草原の上で草を食べています。
sentences:
- どこかの山間の草原にて放し飼いにされた馬たちが餌を食べています。
- ノートパソコンのキーボードの上にネックレスが置いてあります。
- テーブルに様々な食品が置いてあります。
- source_sentence: 小さな子供がバッティングの練習をしています。
sentences:
- 小さな男の子がティーバッティングをしています。
- 整備されていない道路を自動車が走っている
- 水面に赤いくちばしの黒い鳥が一羽います。
- source_sentence: 水辺に熊のぬいぐるみが置かれています。
sentences:
- 男性と女性が、歯を磨いています。
- ぬいぐるみが水面を眺めるように置かれています。
- 机の上にキーボードとマウスがあります。
- source_sentence: 樹木に囲まれた芝生の上に三頭のキリンが立っています。
sentences:
- 木立のある飛行場にプロペラ機があります。
- 芝生の上に数頭のキリンが歩いています。
- 茶色のテーブルの上にピザと飲み物が置かれています。
datasets:
- mteb/JSTS
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- pearson_cosine
- spearman_cosine
model-index:
- name: SentenceTransformer based on sbintuitions/sarashina-embedding-v2-1b
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts dev 1792
type: sts-dev-1792
metrics:
- type: pearson_cosine
value: 0.8087868579610134
name: Pearson Cosine
- type: spearman_cosine
value: 0.7434852310420895
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts dev 1280
type: sts-dev-1280
metrics:
- type: pearson_cosine
value: 0.8078298935695407
name: Pearson Cosine
- type: spearman_cosine
value: 0.7442183123552939
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts dev 768
type: sts-dev-768
metrics:
- type: pearson_cosine
value: 0.8049498106276536
name: Pearson Cosine
- type: spearman_cosine
value: 0.7423127841298944
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts dev 256
type: sts-dev-256
metrics:
- type: pearson_cosine
value: 0.8022036966421968
name: Pearson Cosine
- type: spearman_cosine
value: 0.7410650407423576
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts dev 64
type: sts-dev-64
metrics:
- type: pearson_cosine
value: 0.7972172928220316
name: Pearson Cosine
- type: spearman_cosine
value: 0.7388786050712278
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test 1792
type: sts-test-1792
metrics:
- type: pearson_cosine
value: 0.8087781664749797
name: Pearson Cosine
- type: spearman_cosine
value: 0.7435051743546024
name: Spearman Cosine
- type: pearson_cosine
value: 0.8087781664749797
name: Pearson Cosine
- type: spearman_cosine
value: 0.7435051743546024
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test 1280
type: sts-test-1280
metrics:
- type: pearson_cosine
value: 0.8078219018746986
name: Pearson Cosine
- type: spearman_cosine
value: 0.7442250390777712
name: Spearman Cosine
- type: pearson_cosine
value: 0.8078219018746986
name: Pearson Cosine
- type: spearman_cosine
value: 0.7442250390777712
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test 768
type: sts-test-768
metrics:
- type: pearson_cosine
value: 0.8049404729865752
name: Pearson Cosine
- type: spearman_cosine
value: 0.7423149875969083
name: Spearman Cosine
- type: pearson_cosine
value: 0.8049404729865752
name: Pearson Cosine
- type: spearman_cosine
value: 0.7423149875969083
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test 256
type: sts-test-256
metrics:
- type: pearson_cosine
value: 0.8022025594051618
name: Pearson Cosine
- type: spearman_cosine
value: 0.7410686789846747
name: Spearman Cosine
- type: pearson_cosine
value: 0.8022025594051618
name: Pearson Cosine
- type: spearman_cosine
value: 0.7410686789846747
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test 64
type: sts-test-64
metrics:
- type: pearson_cosine
value: 0.7972183575514205
name: Pearson Cosine
- type: spearman_cosine
value: 0.7388646166416691
name: Spearman Cosine
- type: pearson_cosine
value: 0.7972183575514205
name: Pearson Cosine
- type: spearman_cosine
value: 0.7388646166416691
name: Spearman Cosine
---
# SentenceTransformer based on sbintuitions/sarashina-embedding-v2-1b
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sbintuitions/sarashina-embedding-v2-1b](https://huggingface.co/sbintuitions/sarashina-embedding-v2-1b) on the [jsts](https://huggingface.co/datasets/mteb/JSTS) dataset. It maps sentences & paragraphs to a 1792-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sbintuitions/sarashina-embedding-v2-1b](https://huggingface.co/sbintuitions/sarashina-embedding-v2-1b)
- **Maximum Sequence Length:** 8192 tokens
- **Output Dimensionality:** 1792 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [jsts](https://huggingface.co/datasets/mteb/JSTS)
- **Language:** jpn
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/huggingface/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False, 'architecture': 'LlamaModel'})
(1): Pooling({'word_embedding_dimension': 1792, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': True, 'include_prompt': False})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("kushalc1/sarashina-embedding-v2-1b-jsts-matryoshka")
# Run inference
sentences = [
'樹木に囲まれた芝生の上に三頭のキリンが立っています。',
'芝生の上に数頭のキリンが歩いています。',
'茶色のテーブルの上にピザと飲み物が置かれています。',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1792]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.9453, 0.4754],
# [0.9453, 1.0000, 0.5004],
# [0.4754, 0.5004, 1.0000]])
```
## Evaluation
### Metrics
#### Semantic Similarity
* Datasets: `sts-dev-1792`, `sts-test-1792` and `sts-test-1792`
* Evaluated with [EmbeddingSimilarityEvaluator](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator) with these parameters:
```json
{
"truncate_dim": 1792
}
```
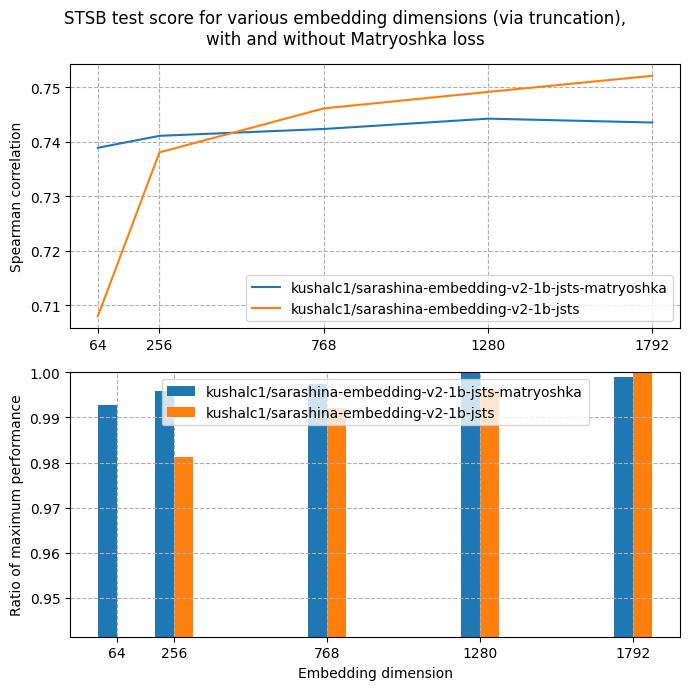
| Metric | sts-dev-1792 | sts-test-1792 |
|:--------------------|:-------------|:--------------|
| pearson_cosine | 0.8088 | 0.8088 |
| **spearman_cosine** | **0.7435** | **0.7435** |
#### Semantic Similarity
* Datasets: `sts-dev-1280`, `sts-test-1280` and `sts-test-1280`
* Evaluated with [EmbeddingSimilarityEvaluator](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator) with these parameters:
```json
{
"truncate_dim": 1280
}
```
| Metric | sts-dev-1280 | sts-test-1280 |
|:--------------------|:-------------|:--------------|
| pearson_cosine | 0.8078 | 0.8078 |
| **spearman_cosine** | **0.7442** | **0.7442** |
#### Semantic Similarity
* Datasets: `sts-dev-768`, `sts-test-768` and `sts-test-768`
* Evaluated with [EmbeddingSimilarityEvaluator](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator) with these parameters:
```json
{
"truncate_dim": 768
}
```
| Metric | sts-dev-768 | sts-test-768 |
|:--------------------|:------------|:-------------|
| pearson_cosine | 0.8049 | 0.8049 |
| **spearman_cosine** | **0.7423** | **0.7423** |
#### Semantic Similarity
* Datasets: `sts-dev-256`, `sts-test-256` and `sts-test-256`
* Evaluated with [EmbeddingSimilarityEvaluator](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator) with these parameters:
```json
{
"truncate_dim": 256
}
```
| Metric | sts-dev-256 | sts-test-256 |
|:--------------------|:------------|:-------------|
| pearson_cosine | 0.8022 | 0.8022 |
| **spearman_cosine** | **0.7411** | **0.7411** |
#### Semantic Similarity
* Datasets: `sts-dev-64`, `sts-test-64` and `sts-test-64`
* Evaluated with [EmbeddingSimilarityEvaluator](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator) with these parameters:
```json
{
"truncate_dim": 64
}
```
| Metric | sts-dev-64 | sts-test-64 |
|:--------------------|:-----------|:------------|
| pearson_cosine | 0.7972 | 0.7972 |
| **spearman_cosine** | **0.7389** | **0.7389** |
## Training Details
### Training Dataset
#### jsts
* Dataset: [jsts](https://huggingface.co/datasets/mteb/JSTS) at [b3d3097](https://huggingface.co/datasets/mteb/JSTS/tree/b3d3097f7faa8c66151fa22c1320aec10671804f)
* Size: 12,451 training samples
* Columns: sentence1, sentence2, and score
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | - min: 5 tokens
- mean: 10.64 tokens
- max: 35 tokens
| - min: 3 tokens
- mean: 10.53 tokens
- max: 30 tokens
| - min: 0.0
- mean: 2.32
- max: 5.0
|
* Samples:
| sentence1 | sentence2 | score |
|:------------------------------------|:-----------------------------------|:-------------------------------|
| 川べりでサーフボードを持った人たちがいます。 | トイレの壁に黒いタオルがかけられています。 | 0.0 |
| 二人の男性がジャンボジェット機を見ています。 | 2人の男性が、白い飛行機を眺めています。 | 3.799999952316284 |
| 男性が子供を抱き上げて立っています。 | 坊主頭の男性が子供を抱いて立っています。 | 4.0 |
* Loss: [MatryoshkaLoss](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
1792,
1280,
768,
256,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Evaluation Dataset
#### jsts
* Dataset: [jsts](https://huggingface.co/datasets/mteb/JSTS) at [b3d3097](https://huggingface.co/datasets/mteb/JSTS/tree/b3d3097f7faa8c66151fa22c1320aec10671804f)
* Size: 1,457 evaluation samples
* Columns: sentence1, sentence2, and score
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | - min: 5 tokens
- mean: 10.78 tokens
- max: 34 tokens
| - min: 3 tokens
- mean: 10.63 tokens
- max: 37 tokens
| - min: 0.0
- mean: 2.22
- max: 5.0
|
* Samples:
| sentence1 | sentence2 | score |
|:-----------------------------------------|:------------------------------------|:--------------------------------|
| レンガの建物の前を、乳母車を押した女性が歩いています。 | 厩舎で馬と女性とが寄り添っています。 | 0.0 |
| 山の上に顔の白い牛が2頭います。 | 曇り空の山肌で、牛が2匹草を食んでいます。 | 2.4000000953674316 |
| バナナを持った人が道路を通行しています。 | 道の上をバナナを背負った男性が歩いています。 | 3.5999999046325684 |
* Loss: [MatryoshkaLoss](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
1792,
1280,
768,
256,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 4
- `warmup_ratio`: 0.1
- `fp16`: True
#### All Hyperparameters
Click to expand
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `parallelism_config`: None
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}