

Initial model upload - clean repository
Browse files- .gitattributes +5 -0
- 1_7b_qwen_armo.png +3 -0
- README.md +257 -0
- added_tokens.json +28 -0
- chat_template.jinja +85 -0
- comparison_rewards_by_token_length-filtered.png +3 -0
- config.json +60 -0
- generation_config.json +6 -0
- merges.txt +0 -0
- model.safetensors +3 -0
- qwen3-1.7_dataset.png +3 -0
- qwen3-1.7b_loss.png +0 -0
- special_tokens_map.json +38 -0
- tokenizer.json +3 -0
- tokenizer_config.json +240 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
1_7b_qwen_armo.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
comparison_rewards_by_token_length-filtered.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
qwen3-1.7_dataset.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
qwen3-1.7b_loss.png filter=lfs diff=lfs merge=lfs -text
|
1_7b_qwen_armo.png
ADDED

|
Git LFS Details
|
README.md
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- tr
|
| 4 |
+
- en
|
| 5 |
+
license: apache-2.0
|
| 6 |
+
tags:
|
| 7 |
+
- text-generation
|
| 8 |
+
- turkish
|
| 9 |
+
- legal
|
| 10 |
+
- turkish-legal
|
| 11 |
+
- mecellem
|
| 12 |
+
- qwen
|
| 13 |
+
- decoder-only
|
| 14 |
+
- continual-pretraining
|
| 15 |
+
- TRUBA
|
| 16 |
+
- MN5
|
| 17 |
+
base_model: Qwen/Qwen3-1.7B
|
| 18 |
+
pipeline_tag: text-generation
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
# Mecellem-Qwen3-1.7B-TR
|
| 22 |
+
|
| 23 |
+
[](https://opensource.org/licenses/Apache-2.0)
|
| 24 |
+
|
| 25 |
+
## Model Description
|
| 26 |
+
|
| 27 |
+
Mecellem-Qwen3-1.7B-TR is a Turkish legal language model adapted through Continual Pre-training (CPT) on Turkish legal and official texts. The model is based on Qwen3-1.7B decoder architecture (1.7B parameters) and trained using a four-phase curriculum learning strategy specifically designed to account for Turkish linguistic complexity. The CPT process progressively transitions from general-purpose texts to domain-specific legal content, achieving 36.2% perplexity reduction on Turkish legal text compared to the base Qwen3-1.7B model.
|
| 28 |
+
|
| 29 |
+
**Key Features:**
|
| 30 |
+
- Continual pre-training on approximately 225 billion tokens across four phases
|
| 31 |
+
- Four-phase curriculum learning:
|
| 32 |
+
- Phase 1: ~3.7B tokens
|
| 33 |
+
- Phase 2: ~57B tokens
|
| 34 |
+
- Phase 3: ~165B tokens
|
| 35 |
+
- Phase 4: ~24.9B tokens
|
| 36 |
+
- Dataset includes Turkish legal sources (Yargıtay, Danıştay, YÖKTEZ) and general Turkish web data (FineWeb2, CulturaX)
|
| 37 |
+
- Preserves general language capabilities while injecting domain-specific legal knowledge
|
| 38 |
+
|
| 39 |
+
**Model Type:** Decoder-only Language Model
|
| 40 |
+
**Parameters:** 1.7B
|
| 41 |
+
**Base Model:** Qwen/Qwen3-1.7B
|
| 42 |
+
**Architecture:** Qwen3 decoder with grouped query attention (GQA)
|
| 43 |
+
|
| 44 |
+
### Architecture Details
|
| 45 |
+
|
| 46 |
+
- **Max Position Embeddings:** 40,960 tokens
|
| 47 |
+
- **Number of Layers:** 28 transformer layers
|
| 48 |
+
- **Hidden Size:** 2,048
|
| 49 |
+
- **FFN Hidden Size:** 6,144
|
| 50 |
+
- **Number of Heads:** 16
|
| 51 |
+
- **Number of KV Heads (GQA):** 8
|
| 52 |
+
- **Activation Function:** SwiGLU
|
| 53 |
+
- **Position Encodings:** RoPE (Rotary Position Embeddings)
|
| 54 |
+
- **Layer Norm:** RMSNorm
|
| 55 |
+
|
| 56 |
+
### Training Details
|
| 57 |
+
|
| 58 |
+
**Continual Pre-training (CPT):**
|
| 59 |
+
- **Total Training Tokens:** ~225 billion tokens (250,739,476,454 tokens across four phases)
|
| 60 |
+
- **Training Method:** Four-phase curriculum learning
|
| 61 |
+
- **Framework:** NVIDIA NeMo with Megatron-Core
|
| 62 |
+
- **Hardware:** MareNostrum 5 supercomputer (BSC), H100 GPUs
|
| 63 |
+
- **Precision:** BF16
|
| 64 |
+
|
| 65 |
+
**Dataset Composition:**
|
| 66 |
+
- **Legal Sources:**
|
| 67 |
+
- Court of Cassation (Yargıtay): 10.3M sequences, ~3.43B tokens
|
| 68 |
+
- Council of State (Danıştay): 151K sequences, ~0.11B tokens
|
| 69 |
+
- Academic theses (YÖKTEZ): 21.1M sequences, ~9.61B tokens (after DocsOCR processing)
|
| 70 |
+
- **General Turkish Sources:**
|
| 71 |
+
- FineWeb2: General Turkish web data
|
| 72 |
+
- CulturaX: Multilingual corpus (Turkish subset)
|
| 73 |
+
- Total general Turkish: 212M sequences, ~96.17B tokens
|
| 74 |
+
- **Additional Categories:** English, Mathematics, Python code, multilingual content (Spanish, Arabic, Russian, Chinese)
|
| 75 |
+
|
| 76 |
+
**Phase 1 (~3.7B tokens):**
|
| 77 |
+
- Focus: Short, general-purpose Turkish texts
|
| 78 |
+
- Purpose: Adapt model to Turkish language patterns while maintaining stability
|
| 79 |
+
- Learning Rate: Higher with extended warmup
|
| 80 |
+
- Dataset: Academic-focused data with semantic deduplication and FineWeb quality filtering
|
| 81 |
+
|
| 82 |
+
**Phase 2 (~57B tokens):**
|
| 83 |
+
- Focus: Legal content with domain-specific terminology
|
| 84 |
+
- Includes: Court decisions, legal articles, regulatory documents
|
| 85 |
+
- Data Replay: YÖKTEZ academic legal data from Phase 1
|
| 86 |
+
- Dataset: Lighter pipeline with FineWeb quality filtering, preserving topical diversity
|
| 87 |
+
|
| 88 |
+
**Phase 3 (~165B tokens):**
|
| 89 |
+
- Focus: Long, structurally complex normative texts
|
| 90 |
+
- Includes: Full court decisions, legislative documents, academic legal theses
|
| 91 |
+
- Purpose: Refine model's understanding of legal reasoning patterns
|
| 92 |
+
- Dataset: Long-form documents with merged consecutive pages
|
| 93 |
+
|
| 94 |
+
**Phase 4 (~24.9B tokens):**
|
| 95 |
+
- Focus: Extended domain-specific refinement
|
| 96 |
+
- Includes: Mixed complexity documents
|
| 97 |
+
- Purpose: Consolidate knowledge and improve generalization
|
| 98 |
+
|
| 99 |
+
**Training Hyperparameters:**
|
| 100 |
+
- Sequence Length: 4,096 tokens
|
| 101 |
+
- Optimizer: Adam with cosine learning rate schedule
|
| 102 |
+
- Max Learning Rate: 5×10⁻⁵
|
| 103 |
+
- Min Learning Rate: 5×10⁻⁶
|
| 104 |
+
- Weight Decay: 0.01
|
| 105 |
+
- Warmup Steps: Phase-dependent (200-2,340 steps)
|
| 106 |
+
- Precision: BF16 mixed precision
|
| 107 |
+
- Framework: NVIDIA NeMo with Megatron-Core
|
| 108 |
+
|
| 109 |
+
**Hardware Infrastructure:**
|
| 110 |
+
- **System:** MareNostrum 5 ACC partition at Barcelona Supercomputing Center (BSC)
|
| 111 |
+
- **Node Configuration:** Each node equipped with 4× NVIDIA Hopper H100 64GB GPUs (SXM), 80 CPU cores, 512GB DDR5 memory
|
| 112 |
+
- **Interconnect:** 800 Gb/s InfiniBand for distributed training
|
| 113 |
+
- **GPU Interconnect:** NVLink for intra-node GPU communication (4 GPUs per node connected via NVLink)
|
| 114 |
+
- **Distributed Training:** Data-parallel multi-node and multi-GPU distributed architecture with 4 GPUs per node
|
| 115 |
+
- **InfiniBand Network:** Enabled efficient processing of large-scale token flow and ensured high scalability and training stability in long-term CPT training
|
| 116 |
+
- **Phase-Specific Hardware:**
|
| 117 |
+
- **Phase 1:** 50 nodes, 200 GPUs, ~3.7B tokens, 3.77M tokens/sec throughput, 20.7% median MFU
|
| 118 |
+
- **Phase 2:** 50 nodes, 200 GPUs, ~57B tokens, 3.59M tokens/sec throughput, 20.7% median MFU
|
| 119 |
+
- **Phase 3:** 100 nodes, 400 GPUs, ~165B tokens, 7.35M tokens/sec throughput, 20.3% median MFU
|
| 120 |
+
- **Phase 4:** 50 nodes, 200 GPUs, ~24.9B tokens, 3.25M tokens/sec throughput, 20.6% median MFU
|
| 121 |
+
|
| 122 |
+
**Catastrophic Forgetting Mitigation:**
|
| 123 |
+
- Curriculum learning: Progressive transition from general to specialized knowledge
|
| 124 |
+
- Replay buffer: YÖKTEZ data from Phase 1 included in Phase 2
|
| 125 |
+
- Conservative learning rates and extended warmup periods
|
| 126 |
+
|
| 127 |
+
**Performance:** Achieved 36.2% perplexity reduction on Turkish legal text compared to base Qwen3-1.7B model.
|
| 128 |
+
|
| 129 |
+
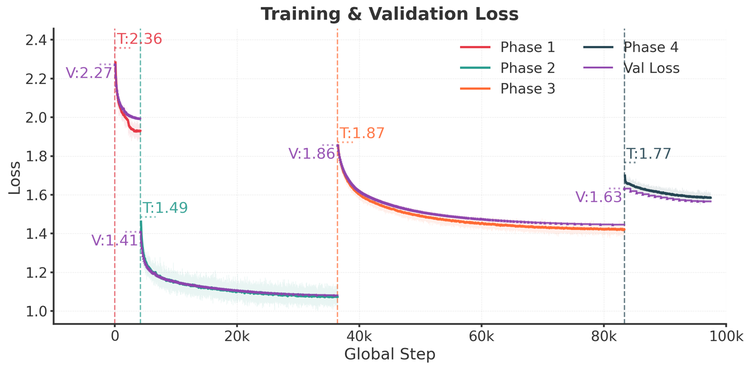
### Training Visualization
|
| 130 |
+
|
| 131 |
+
The following visualizations show the model's training progress and dataset distribution:
|
| 132 |
+
|
| 133 |
+

|
| 134 |
+
|
| 135 |
+
*Qwen3-1.7B CPT Dataset Distribution across Four Phases. The curriculum learning strategy progressively introduces more complex legal content.*
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
*Qwen3-1.7B CPT Training and Validation Loss Across Four Phases. The model shows consistent improvement throughout all training phases.*
|
| 140 |
+
|
| 141 |
+
### Benchmark Performance
|
| 142 |
+
|
| 143 |
+
The model was evaluated using the Muhakim reward model on Turkish legal tasks:
|
| 144 |
+
|
| 145 |
+

|
| 146 |
+
|
| 147 |
+
*Benchmark Performance of 1.7B Decoder-Only Models Across Context Lengths Using the Muhakim Reward Model. Mecellem-Qwen3-1.7B-TR consistently outperforms the base Qwen3-1.7B model across all five legal quality objectives, with particularly pronounced gains for depth of coverage, statute reference usage, and legal accuracy.*
|
| 148 |
+
|
| 149 |
+
### Rewards Comparison Analysis
|
| 150 |
+
|
| 151 |
+
The following visualization compares rewards across different token lengths for base vs CPT models:
|
| 152 |
+
|
| 153 |
+

|
| 154 |
+
|
| 155 |
+
*Rewards Comparison: Base vs CPT Models Across Token Lengths. Mecellem-Qwen3-1.7B-TR shows consistent improvements over the base model across all context length settings, demonstrating the effectiveness of Turkish legal domain adaptation.*
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
## Usage
|
| 159 |
+
|
| 160 |
+
### Installation
|
| 161 |
+
|
| 162 |
+
```bash
|
| 163 |
+
pip install transformers torch
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
### Text Generation
|
| 167 |
+
|
| 168 |
+
```python
|
| 169 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 170 |
+
import torch
|
| 171 |
+
|
| 172 |
+
# Load model and tokenizer
|
| 173 |
+
tokenizer = AutoTokenizer.from_pretrained("newmindai/Mecellem-Qwen3-1.7B-TR")
|
| 174 |
+
model = AutoModelForCausalLM.from_pretrained("newmindai/Mecellem-Qwen3-1.7B-TR")
|
| 175 |
+
|
| 176 |
+
# Example prompt
|
| 177 |
+
prompt = "Türk hukuk sisteminde sözleşme feshi"
|
| 178 |
+
inputs = tokenizer(prompt, return_tensors="pt")
|
| 179 |
+
|
| 180 |
+
# Generate
|
| 181 |
+
with torch.no_grad():
|
| 182 |
+
outputs = model.generate(
|
| 183 |
+
**inputs,
|
| 184 |
+
max_new_tokens=256,
|
| 185 |
+
temperature=0.7,
|
| 186 |
+
do_sample=True,
|
| 187 |
+
top_p=0.9
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 191 |
+
print(generated_text)
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
### Chat Format
|
| 195 |
+
|
| 196 |
+
```python
|
| 197 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 198 |
+
|
| 199 |
+
tokenizer = AutoTokenizer.from_pretrained("newmindai/Mecellem-Qwen3-1.7B-TR")
|
| 200 |
+
model = AutoModelForCausalLM.from_pretrained("newmindai/Mecellem-Qwen3-1.7B-TR")
|
| 201 |
+
|
| 202 |
+
messages = [
|
| 203 |
+
{"role": "user", "content": "Türk hukuk sisteminde sözleşme feshi nasıl yapılır?"}
|
| 204 |
+
]
|
| 205 |
+
|
| 206 |
+
# Apply chat template
|
| 207 |
+
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 208 |
+
inputs = tokenizer(text, return_tensors="pt")
|
| 209 |
+
|
| 210 |
+
# Generate response
|
| 211 |
+
with torch.no_grad():
|
| 212 |
+
outputs = model.generate(**inputs, max_new_tokens=256)
|
| 213 |
+
|
| 214 |
+
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 215 |
+
print(response)
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
## Use Cases
|
| 219 |
+
|
| 220 |
+
- Turkish legal text generation
|
| 221 |
+
- Legal document summarization
|
| 222 |
+
- Legal question answering
|
| 223 |
+
- Legal text completion
|
| 224 |
+
- Domain-specific language modeling for Turkish legal domain
|
| 225 |
+
- Retrieval-Augmented Generation (RAG) applications
|
| 226 |
+
|
| 227 |
+
## Acknowledgments
|
| 228 |
+
|
| 229 |
+
This work was supported by the EuroHPC Joint Undertaking through project etur46 with access to the MareNostrum 5 supercomputer, hosted by Barcelona Supercomputing Center (BSC), Spain. MareNostrum 5 is owned by EuroHPC JU and operated by BSC. We are grateful to the BSC support team for their assistance with job scheduling, environment configuration, and technical guidance throughout the project.
|
| 230 |
+
|
| 231 |
+
The numerical calculations reported in this work were fully/partially performed at TÜBİTAK ULAKBİM, High Performance and Grid Computing Center (TRUBA resources). The authors gratefully acknowledge the know-how provided by the MINERVA Support for expert guidance and collaboration opportunities in HPC-AI integration.
|
| 232 |
+
|
| 233 |
+
## References
|
| 234 |
+
|
| 235 |
+
If you use this model, please cite our paper:
|
| 236 |
+
|
| 237 |
+
```bibtex
|
| 238 |
+
@article{mecellem2026,
|
| 239 |
+
title={Mecellem Models: Turkish Models Trained from Scratch and Continually Pre-trained for the Legal Domain},
|
| 240 |
+
author={Uğur, Özgür and Göksu, Mahmut and Şavirdi, Esra and Çimen, Mahmut and Yılmaz, Musa and Demir, Alp Talha and Güllüce, Rumeysa and Çetin, İclal and Sağbaş, Ömer Can},
|
| 241 |
+
journal={Procedia Computer Science},
|
| 242 |
+
year={2026},
|
| 243 |
+
publisher={Elsevier}
|
| 244 |
+
}
|
| 245 |
+
```
|
| 246 |
+
### Base Model References
|
| 247 |
+
|
| 248 |
+
```bibtex
|
| 249 |
+
@article{qwen2024,
|
| 250 |
+
title={Qwen3: A Large Language Model Series},
|
| 251 |
+
author={Qwen Team},
|
| 252 |
+
journal={arXiv preprint arXiv:2409.00000},
|
| 253 |
+
year={2024}
|
| 254 |
+
}
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
<!-- Updated: 2026-01-15 09:38:29 -->
|
added_tokens.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</think>": 151668,
|
| 3 |
+
"</tool_call>": 151658,
|
| 4 |
+
"</tool_response>": 151666,
|
| 5 |
+
"<think>": 151667,
|
| 6 |
+
"<tool_call>": 151657,
|
| 7 |
+
"<tool_response>": 151665,
|
| 8 |
+
"<|box_end|>": 151649,
|
| 9 |
+
"<|box_start|>": 151648,
|
| 10 |
+
"<|endoftext|>": 151643,
|
| 11 |
+
"<|file_sep|>": 151664,
|
| 12 |
+
"<|fim_middle|>": 151660,
|
| 13 |
+
"<|fim_pad|>": 151662,
|
| 14 |
+
"<|fim_prefix|>": 151659,
|
| 15 |
+
"<|fim_suffix|>": 151661,
|
| 16 |
+
"<|im_end|>": 151645,
|
| 17 |
+
"<|im_start|>": 151644,
|
| 18 |
+
"<|image_pad|>": 151655,
|
| 19 |
+
"<|object_ref_end|>": 151647,
|
| 20 |
+
"<|object_ref_start|>": 151646,
|
| 21 |
+
"<|quad_end|>": 151651,
|
| 22 |
+
"<|quad_start|>": 151650,
|
| 23 |
+
"<|repo_name|>": 151663,
|
| 24 |
+
"<|video_pad|>": 151656,
|
| 25 |
+
"<|vision_end|>": 151653,
|
| 26 |
+
"<|vision_pad|>": 151654,
|
| 27 |
+
"<|vision_start|>": 151652
|
| 28 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- if tools %}
|
| 2 |
+
{{- '<|im_start|>system\n' }}
|
| 3 |
+
{%- if messages[0].role == 'system' %}
|
| 4 |
+
{{- messages[0].content + '\n\n' }}
|
| 5 |
+
{%- endif %}
|
| 6 |
+
{{- "# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
|
| 7 |
+
{%- for tool in tools %}
|
| 8 |
+
{{- "\n" }}
|
| 9 |
+
{{- tool | tojson }}
|
| 10 |
+
{%- endfor %}
|
| 11 |
+
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
|
| 12 |
+
{%- else %}
|
| 13 |
+
{%- if messages[0].role == 'system' %}
|
| 14 |
+
{{- '<|im_start|>system\n' + messages[0].content + '<|im_end|>\n' }}
|
| 15 |
+
{%- endif %}
|
| 16 |
+
{%- endif %}
|
| 17 |
+
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
|
| 18 |
+
{%- for message in messages[::-1] %}
|
| 19 |
+
{%- set index = (messages|length - 1) - loop.index0 %}
|
| 20 |
+
{%- if ns.multi_step_tool and message.role == "user" and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}
|
| 21 |
+
{%- set ns.multi_step_tool = false %}
|
| 22 |
+
{%- set ns.last_query_index = index %}
|
| 23 |
+
{%- endif %}
|
| 24 |
+
{%- endfor %}
|
| 25 |
+
{%- for message in messages %}
|
| 26 |
+
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
|
| 27 |
+
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
|
| 28 |
+
{%- elif message.role == "assistant" %}
|
| 29 |
+
{%- set content = message.content %}
|
| 30 |
+
{%- set reasoning_content = '' %}
|
| 31 |
+
{%- if message.reasoning_content is defined and message.reasoning_content is not none %}
|
| 32 |
+
{%- set reasoning_content = message.reasoning_content %}
|
| 33 |
+
{%- else %}
|
| 34 |
+
{%- if '</think>' in message.content %}
|
| 35 |
+
{%- set content = message.content.split('</think>')[-1].lstrip('\n') %}
|
| 36 |
+
{%- set reasoning_content = message.content.split('</think>')[0].rstrip('\n').split('<think>')[-1].lstrip('\n') %}
|
| 37 |
+
{%- endif %}
|
| 38 |
+
{%- endif %}
|
| 39 |
+
{%- if loop.index0 > ns.last_query_index %}
|
| 40 |
+
{%- if loop.last or (not loop.last and reasoning_content) %}
|
| 41 |
+
{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content.strip('\n') + '\n</think>\n\n' + content.lstrip('\n') }}
|
| 42 |
+
{%- else %}
|
| 43 |
+
{{- '<|im_start|>' + message.role + '\n' + content }}
|
| 44 |
+
{%- endif %}
|
| 45 |
+
{%- else %}
|
| 46 |
+
{{- '<|im_start|>' + message.role + '\n' + content }}
|
| 47 |
+
{%- endif %}
|
| 48 |
+
{%- if message.tool_calls %}
|
| 49 |
+
{%- for tool_call in message.tool_calls %}
|
| 50 |
+
{%- if (loop.first and content) or (not loop.first) %}
|
| 51 |
+
{{- '\n' }}
|
| 52 |
+
{%- endif %}
|
| 53 |
+
{%- if tool_call.function %}
|
| 54 |
+
{%- set tool_call = tool_call.function %}
|
| 55 |
+
{%- endif %}
|
| 56 |
+
{{- '<tool_call>\n{"name": "' }}
|
| 57 |
+
{{- tool_call.name }}
|
| 58 |
+
{{- '", "arguments": ' }}
|
| 59 |
+
{%- if tool_call.arguments is string %}
|
| 60 |
+
{{- tool_call.arguments }}
|
| 61 |
+
{%- else %}
|
| 62 |
+
{{- tool_call.arguments | tojson }}
|
| 63 |
+
{%- endif %}
|
| 64 |
+
{{- '}\n</tool_call>' }}
|
| 65 |
+
{%- endfor %}
|
| 66 |
+
{%- endif %}
|
| 67 |
+
{{- '<|im_end|>\n' }}
|
| 68 |
+
{%- elif message.role == "tool" %}
|
| 69 |
+
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
|
| 70 |
+
{{- '<|im_start|>user' }}
|
| 71 |
+
{%- endif %}
|
| 72 |
+
{{- '\n<tool_response>\n' }}
|
| 73 |
+
{{- message.content }}
|
| 74 |
+
{{- '\n</tool_response>' }}
|
| 75 |
+
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
|
| 76 |
+
{{- '<|im_end|>\n' }}
|
| 77 |
+
{%- endif %}
|
| 78 |
+
{%- endif %}
|
| 79 |
+
{%- endfor %}
|
| 80 |
+
{%- if add_generation_prompt %}
|
| 81 |
+
{{- '<|im_start|>assistant\n' }}
|
| 82 |
+
{%- if enable_thinking is defined and enable_thinking is false %}
|
| 83 |
+
{{- '<think>\n\n</think>\n\n' }}
|
| 84 |
+
{%- endif %}
|
| 85 |
+
{%- endif %}
|
comparison_rewards_by_token_length-filtered.png
ADDED

|
Git LFS Details
|
config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen3ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151645,
|
| 9 |
+
"head_dim": 128,
|
| 10 |
+
"hidden_act": "silu",
|
| 11 |
+
"hidden_size": 2048,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 6144,
|
| 14 |
+
"layer_types": [
|
| 15 |
+
"full_attention",
|
| 16 |
+
"full_attention",
|
| 17 |
+
"full_attention",
|
| 18 |
+
"full_attention",
|
| 19 |
+
"full_attention",
|
| 20 |
+
"full_attention",
|
| 21 |
+
"full_attention",
|
| 22 |
+
"full_attention",
|
| 23 |
+
"full_attention",
|
| 24 |
+
"full_attention",
|
| 25 |
+
"full_attention",
|
| 26 |
+
"full_attention",
|
| 27 |
+
"full_attention",
|
| 28 |
+
"full_attention",
|
| 29 |
+
"full_attention",
|
| 30 |
+
"full_attention",
|
| 31 |
+
"full_attention",
|
| 32 |
+
"full_attention",
|
| 33 |
+
"full_attention",
|
| 34 |
+
"full_attention",
|
| 35 |
+
"full_attention",
|
| 36 |
+
"full_attention",
|
| 37 |
+
"full_attention",
|
| 38 |
+
"full_attention",
|
| 39 |
+
"full_attention",
|
| 40 |
+
"full_attention",
|
| 41 |
+
"full_attention",
|
| 42 |
+
"full_attention"
|
| 43 |
+
],
|
| 44 |
+
"max_position_embeddings": 40960,
|
| 45 |
+
"max_window_layers": 28,
|
| 46 |
+
"model_type": "qwen3",
|
| 47 |
+
"num_attention_heads": 16,
|
| 48 |
+
"num_hidden_layers": 28,
|
| 49 |
+
"num_key_value_heads": 8,
|
| 50 |
+
"rms_norm_eps": 1e-06,
|
| 51 |
+
"rope_scaling": null,
|
| 52 |
+
"rope_theta": 1000000.0,
|
| 53 |
+
"sliding_window": null,
|
| 54 |
+
"tie_word_embeddings": true,
|
| 55 |
+
"torch_dtype": "bfloat16",
|
| 56 |
+
"transformers_version": "4.53.0",
|
| 57 |
+
"use_cache": true,
|
| 58 |
+
"use_sliding_window": false,
|
| 59 |
+
"vocab_size": 151936
|
| 60 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 151643,
|
| 4 |
+
"eos_token_id": 151645,
|
| 5 |
+
"transformers_version": "4.53.0"
|
| 6 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6b2b2cfc1af4638fd11b9a727315771cc0265679e2043bbffcf1abd049068928
|
| 3 |
+
size 4063515640
|
qwen3-1.7_dataset.png
ADDED

|
Git LFS Details
|
qwen3-1.7b_loss.png
ADDED
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
},
|
| 31 |
+
"sep_token": {
|
| 32 |
+
"content": "<|endoftext|>",
|
| 33 |
+
"lstrip": false,
|
| 34 |
+
"normalized": false,
|
| 35 |
+
"rstrip": false,
|
| 36 |
+
"single_word": false
|
| 37 |
+
}
|
| 38 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aeb13307a71acd8fe81861d94ad54ab689df773318809eed3cbe794b4492dae4
|
| 3 |
+
size 11422654
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
},
|
| 181 |
+
"151665": {
|
| 182 |
+
"content": "<tool_response>",
|
| 183 |
+
"lstrip": false,
|
| 184 |
+
"normalized": false,
|
| 185 |
+
"rstrip": false,
|
| 186 |
+
"single_word": false,
|
| 187 |
+
"special": false
|
| 188 |
+
},
|
| 189 |
+
"151666": {
|
| 190 |
+
"content": "</tool_response>",
|
| 191 |
+
"lstrip": false,
|
| 192 |
+
"normalized": false,
|
| 193 |
+
"rstrip": false,
|
| 194 |
+
"single_word": false,
|
| 195 |
+
"special": false
|
| 196 |
+
},
|
| 197 |
+
"151667": {
|
| 198 |
+
"content": "<think>",
|
| 199 |
+
"lstrip": false,
|
| 200 |
+
"normalized": false,
|
| 201 |
+
"rstrip": false,
|
| 202 |
+
"single_word": false,
|
| 203 |
+
"special": false
|
| 204 |
+
},
|
| 205 |
+
"151668": {
|
| 206 |
+
"content": "</think>",
|
| 207 |
+
"lstrip": false,
|
| 208 |
+
"normalized": false,
|
| 209 |
+
"rstrip": false,
|
| 210 |
+
"single_word": false,
|
| 211 |
+
"special": false
|
| 212 |
+
}
|
| 213 |
+
},
|
| 214 |
+
"additional_special_tokens": [
|
| 215 |
+
"<|im_start|>",
|
| 216 |
+
"<|im_end|>",
|
| 217 |
+
"<|object_ref_start|>",
|
| 218 |
+
"<|object_ref_end|>",
|
| 219 |
+
"<|box_start|>",
|
| 220 |
+
"<|box_end|>",
|
| 221 |
+
"<|quad_start|>",
|
| 222 |
+
"<|quad_end|>",
|
| 223 |
+
"<|vision_start|>",
|
| 224 |
+
"<|vision_end|>",
|
| 225 |
+
"<|vision_pad|>",
|
| 226 |
+
"<|image_pad|>",
|
| 227 |
+
"<|video_pad|>"
|
| 228 |
+
],
|
| 229 |
+
"bos_token": null,
|
| 230 |
+
"clean_up_tokenization_spaces": false,
|
| 231 |
+
"eos_token": "<|endoftext|>",
|
| 232 |
+
"errors": "replace",
|
| 233 |
+
"extra_special_tokens": {},
|
| 234 |
+
"model_max_length": 131072,
|
| 235 |
+
"pad_token": "<|endoftext|>",
|
| 236 |
+
"sep_token": "<|endoftext|>",
|
| 237 |
+
"split_special_tokens": false,
|
| 238 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 239 |
+
"unk_token": null
|
| 240 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|