 +
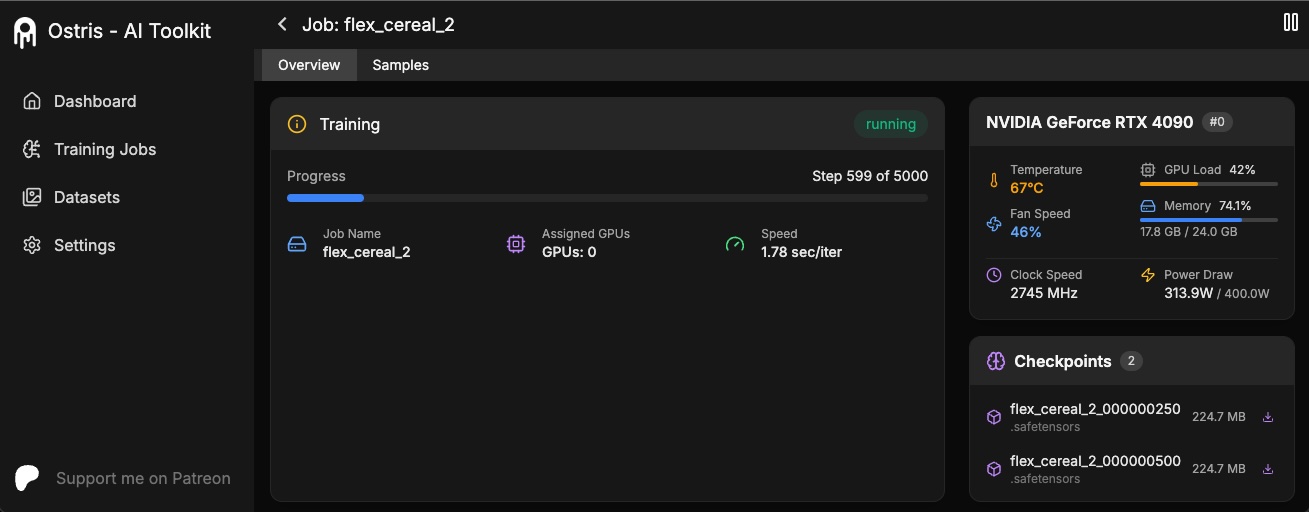
+The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It also allows you to set a token for the UI to prevent unauthorized access so it is mostly safe to run on an exposed server.
+
+## Running the UI
+
+Requirements:
+- Node.js > 20
+
+The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs. The commands below
+will install / update the UI and it's dependencies and start the UI.
+
+```bash
+cd ui
+npm run build_and_start
+```
+
+You can now access the UI at `http://localhost:8675` or `http://
+
+The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It also allows you to set a token for the UI to prevent unauthorized access so it is mostly safe to run on an exposed server.
+
+## Running the UI
+
+Requirements:
+- Node.js > 20
+
+The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs. The commands below
+will install / update the UI and it's dependencies and start the UI.
+
+```bash
+cd ui
+npm run build_and_start
+```
+
+You can now access the UI at `http://localhost:8675` or `http:// +
+### Current Sponsors
+
+All of these people / organizations are the ones who selflessly make this project possible. Thank you!!
+
+
+
+### Current Sponsors
+
+All of these people / organizations are the ones who selflessly make this project possible. Thank you!!
+
+ diff --git a/ai-toolkit/build_and_push_docker b/ai-toolkit/build_and_push_docker
new file mode 100644
index 0000000000000000000000000000000000000000..e891e22c8db0930c446b6d353fe87773fdfbaedc
--- /dev/null
+++ b/ai-toolkit/build_and_push_docker
@@ -0,0 +1,29 @@
+#!/usr/bin/env bash
+
+# Extract version from version.py
+if [ -f "version.py" ]; then
+ VERSION=$(python3 -c "from version import VERSION; print(VERSION)")
+ echo "Building version: $VERSION"
+else
+ echo "Error: version.py not found. Please create a version.py file with VERSION defined."
+ exit 1
+fi
+
+echo "Docker builds from the repo, not this dir. Make sure changes are pushed to the repo."
+echo "Building version: $VERSION and latest"
+# wait 2 seconds
+sleep 2
+
+# Build the image with cache busting
+docker build --build-arg CACHEBUST=$(date +%s) -t aitoolkit:$VERSION -f docker/Dockerfile .
+
+# Tag with version and latest
+docker tag aitoolkit:$VERSION ostris/aitoolkit:$VERSION
+docker tag aitoolkit:$VERSION ostris/aitoolkit:latest
+
+# Push both tags
+echo "Pushing images to Docker Hub..."
+docker push ostris/aitoolkit:$VERSION
+docker push ostris/aitoolkit:latest
+
+echo "Successfully built and pushed ostris/aitoolkit:$VERSION and ostris/aitoolkit:latest"
\ No newline at end of file
diff --git a/ai-toolkit/build_and_push_docker_dev b/ai-toolkit/build_and_push_docker_dev
new file mode 100644
index 0000000000000000000000000000000000000000..9098d8cdf6f77e369ad922e863a37990c1548e38
--- /dev/null
+++ b/ai-toolkit/build_and_push_docker_dev
@@ -0,0 +1,21 @@
+#!/usr/bin/env bash
+
+VERSION=dev
+GIT_COMMIT=dev
+
+echo "Docker builds from the repo, not this dir. Make sure changes are pushed to the repo."
+echo "Building version: $VERSION"
+# wait 2 seconds
+sleep 2
+
+# Build the image with cache busting
+docker build --build-arg CACHEBUST=$(date +%s) -t aitoolkit:$VERSION -f docker/Dockerfile .
+
+# Tag with version and latest
+docker tag aitoolkit:$VERSION ostris/aitoolkit:$VERSION
+
+# Push both tags
+echo "Pushing images to Docker Hub..."
+docker push ostris/aitoolkit:$VERSION
+
+echo "Successfully built and pushed ostris/aitoolkit:$VERSION"
\ No newline at end of file
diff --git a/ai-toolkit/config/examples/extract.example.yml b/ai-toolkit/config/examples/extract.example.yml
new file mode 100644
index 0000000000000000000000000000000000000000..52505bb9058d81d4be3881bb20ecf6da214f571f
--- /dev/null
+++ b/ai-toolkit/config/examples/extract.example.yml
@@ -0,0 +1,75 @@
+---
+# this is in yaml format. You can use json if you prefer
+# I like both but yaml is easier to read and write
+# plus it has comments which is nice for documentation
+job: extract # tells the runner what to do
+config:
+ # the name will be used to create a folder in the output folder
+ # it will also replace any [name] token in the rest of this config
+ name: name_of_your_model
+ # can be hugging face model, a .ckpt, or a .safetensors
+ base_model: "/path/to/base/model.safetensors"
+ # can be hugging face model, a .ckpt, or a .safetensors
+ extract_model: "/path/to/model/to/extract/trained.safetensors"
+ # we will create folder here with name above so. This will create /path/to/output/folder/name_of_your_model
+ output_folder: "/path/to/output/folder"
+ is_v2: false
+ dtype: fp16 # saved dtype
+ device: cpu # cpu, cuda:0, etc
+
+ # processes can be chained like this to run multiple in a row
+ # they must all use same models above, but great for testing different
+ # sizes and typed of extractions. It is much faster as we already have the models loaded
+ process:
+ # process 1
+ - type: locon # locon or lora (locon is lycoris)
+ filename: "[name]_64_32.safetensors" # will be put in output folder
+ dtype: fp16
+ mode: fixed
+ linear: 64
+ conv: 32
+
+ # process 2
+ - type: locon
+ output_path: "/absolute/path/for/this/output.safetensors" # can be absolute
+ mode: ratio
+ linear: 0.2
+ conv: 0.2
+
+ # process 3
+ - type: locon
+ filename: "[name]_ratio_02.safetensors"
+ mode: quantile
+ linear: 0.5
+ conv: 0.5
+
+ # process 4
+ - type: lora # traditional lora extraction (lierla) with linear layers only
+ filename: "[name]_4.safetensors"
+ mode: fixed # fixed, ratio, quantile supported for lora as well
+ linear: 4 # lora dim or rank
+ # no conv for lora
+
+ # process 5
+ - type: lora
+ filename: "[name]_q05.safetensors"
+ mode: quantile
+ linear: 0.5
+
+# you can put any information you want here, and it will be saved in the model
+# the below is an example. I recommend doing trigger words at a minimum
+# in the metadata. The software will include this plus some other information
+meta:
+ name: "[name]" # [name] gets replaced with the name above
+ description: A short description of your model
+ trigger_words:
+ - put
+ - trigger
+ - words
+ - here
+ version: '0.1'
+ creator:
+ name: Your Name
+ email: your@email.com
+ website: https://yourwebsite.com
+ any: All meta data above is arbitrary, it can be whatever you want.
diff --git a/ai-toolkit/config/examples/generate.example.yaml b/ai-toolkit/config/examples/generate.example.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1a3e19efdfee6f6215f37bb741a7b12e7c5ad484
--- /dev/null
+++ b/ai-toolkit/config/examples/generate.example.yaml
@@ -0,0 +1,60 @@
+---
+
+job: generate # tells the runner what to do
+config:
+ name: "generate" # this is not really used anywhere currently but required by runner
+ process:
+ # process 1
+ - type: to_folder # process images to a folder
+ output_folder: "output/gen"
+ device: cuda:0 # cpu, cuda:0, etc
+ generate:
+ # these are your defaults you can override most of them with flags
+ sampler: "ddpm" # ignored for now, will add later though ddpm is used regardless for now
+ width: 1024
+ height: 1024
+ neg: "cartoon, fake, drawing, illustration, cgi, animated, anime"
+ seed: -1 # -1 is random
+ guidance_scale: 7
+ sample_steps: 20
+ ext: ".png" # .png, .jpg, .jpeg, .webp
+
+ # here ate the flags you can use for prompts. Always start with
+ # your prompt first then add these flags after. You can use as many
+ # like
+ # photo of a baseball --n painting, ugly --w 1024 --h 1024 --seed 42 --cfg 7 --steps 20
+ # we will try to support all sd-scripts flags where we can
+
+ # FROM SD-SCRIPTS
+ # --n Treat everything until the next option as a negative prompt.
+ # --w Specify the width of the generated image.
+ # --h Specify the height of the generated image.
+ # --d Specify the seed for the generated image.
+ # --l Specify the CFG scale for the generated image.
+ # --s Specify the number of steps during generation.
+
+ # OURS and some QOL additions
+ # --p2 Prompt for the second text encoder (SDXL only)
+ # --n2 Negative prompt for the second text encoder (SDXL only)
+ # --gr Specify the guidance rescale for the generated image (SDXL only)
+ # --seed Specify the seed for the generated image same as --d
+ # --cfg Specify the CFG scale for the generated image same as --l
+ # --steps Specify the number of steps during generation same as --s
+
+ prompt_file: false # if true a txt file will be created next to images with prompt strings used
+ # prompts can also be a path to a text file with one prompt per line
+ # prompts: "/path/to/prompts.txt"
+ prompts:
+ - "photo of batman"
+ - "photo of superman"
+ - "photo of spiderman"
+ - "photo of a superhero --n batman superman spiderman"
+
+ model:
+ # huggingface name, relative prom project path, or absolute path to .safetensors or .ckpt
+ # name_or_path: "runwayml/stable-diffusion-v1-5"
+ name_or_path: "/mnt/Models/stable-diffusion/models/stable-diffusion/Ostris/Ostris_Real_v1.safetensors"
+ is_v2: false # for v2 models
+ is_v_pred: false # for v-prediction models (most v2 models)
+ is_xl: false # for SDXL models
+ dtype: bf16
diff --git a/ai-toolkit/config/examples/mod_lora_scale.yaml b/ai-toolkit/config/examples/mod_lora_scale.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5f59ecc838b1e4a4465600a67ddb690331ba3255
--- /dev/null
+++ b/ai-toolkit/config/examples/mod_lora_scale.yaml
@@ -0,0 +1,48 @@
+---
+job: mod
+config:
+ name: name_of_your_model_v1
+ process:
+ - type: rescale_lora
+ # path to your current lora model
+ input_path: "/path/to/lora/lora.safetensors"
+ # output path for your new lora model, can be the same as input_path to replace
+ output_path: "/path/to/lora/output_lora_v1.safetensors"
+ # replaces meta with the meta below (plus minimum meta fields)
+ # if false, we will leave the meta alone except for updating hashes (sd-script hashes)
+ replace_meta: true
+ # how to adjust, we can scale the up_down weights or the alpha
+ # up_down is the default and probably the best, they will both net the same outputs
+ # would only affect rare NaN cases and maybe merging with old merge tools
+ scale_target: 'up_down'
+ # precision to save, fp16 is the default and standard
+ save_dtype: fp16
+ # current_weight is the ideal weight you use as a multiplier when using the lora
+ # IE in automatic1111
diff --git a/ai-toolkit/build_and_push_docker b/ai-toolkit/build_and_push_docker
new file mode 100644
index 0000000000000000000000000000000000000000..e891e22c8db0930c446b6d353fe87773fdfbaedc
--- /dev/null
+++ b/ai-toolkit/build_and_push_docker
@@ -0,0 +1,29 @@
+#!/usr/bin/env bash
+
+# Extract version from version.py
+if [ -f "version.py" ]; then
+ VERSION=$(python3 -c "from version import VERSION; print(VERSION)")
+ echo "Building version: $VERSION"
+else
+ echo "Error: version.py not found. Please create a version.py file with VERSION defined."
+ exit 1
+fi
+
+echo "Docker builds from the repo, not this dir. Make sure changes are pushed to the repo."
+echo "Building version: $VERSION and latest"
+# wait 2 seconds
+sleep 2
+
+# Build the image with cache busting
+docker build --build-arg CACHEBUST=$(date +%s) -t aitoolkit:$VERSION -f docker/Dockerfile .
+
+# Tag with version and latest
+docker tag aitoolkit:$VERSION ostris/aitoolkit:$VERSION
+docker tag aitoolkit:$VERSION ostris/aitoolkit:latest
+
+# Push both tags
+echo "Pushing images to Docker Hub..."
+docker push ostris/aitoolkit:$VERSION
+docker push ostris/aitoolkit:latest
+
+echo "Successfully built and pushed ostris/aitoolkit:$VERSION and ostris/aitoolkit:latest"
\ No newline at end of file
diff --git a/ai-toolkit/build_and_push_docker_dev b/ai-toolkit/build_and_push_docker_dev
new file mode 100644
index 0000000000000000000000000000000000000000..9098d8cdf6f77e369ad922e863a37990c1548e38
--- /dev/null
+++ b/ai-toolkit/build_and_push_docker_dev
@@ -0,0 +1,21 @@
+#!/usr/bin/env bash
+
+VERSION=dev
+GIT_COMMIT=dev
+
+echo "Docker builds from the repo, not this dir. Make sure changes are pushed to the repo."
+echo "Building version: $VERSION"
+# wait 2 seconds
+sleep 2
+
+# Build the image with cache busting
+docker build --build-arg CACHEBUST=$(date +%s) -t aitoolkit:$VERSION -f docker/Dockerfile .
+
+# Tag with version and latest
+docker tag aitoolkit:$VERSION ostris/aitoolkit:$VERSION
+
+# Push both tags
+echo "Pushing images to Docker Hub..."
+docker push ostris/aitoolkit:$VERSION
+
+echo "Successfully built and pushed ostris/aitoolkit:$VERSION"
\ No newline at end of file
diff --git a/ai-toolkit/config/examples/extract.example.yml b/ai-toolkit/config/examples/extract.example.yml
new file mode 100644
index 0000000000000000000000000000000000000000..52505bb9058d81d4be3881bb20ecf6da214f571f
--- /dev/null
+++ b/ai-toolkit/config/examples/extract.example.yml
@@ -0,0 +1,75 @@
+---
+# this is in yaml format. You can use json if you prefer
+# I like both but yaml is easier to read and write
+# plus it has comments which is nice for documentation
+job: extract # tells the runner what to do
+config:
+ # the name will be used to create a folder in the output folder
+ # it will also replace any [name] token in the rest of this config
+ name: name_of_your_model
+ # can be hugging face model, a .ckpt, or a .safetensors
+ base_model: "/path/to/base/model.safetensors"
+ # can be hugging face model, a .ckpt, or a .safetensors
+ extract_model: "/path/to/model/to/extract/trained.safetensors"
+ # we will create folder here with name above so. This will create /path/to/output/folder/name_of_your_model
+ output_folder: "/path/to/output/folder"
+ is_v2: false
+ dtype: fp16 # saved dtype
+ device: cpu # cpu, cuda:0, etc
+
+ # processes can be chained like this to run multiple in a row
+ # they must all use same models above, but great for testing different
+ # sizes and typed of extractions. It is much faster as we already have the models loaded
+ process:
+ # process 1
+ - type: locon # locon or lora (locon is lycoris)
+ filename: "[name]_64_32.safetensors" # will be put in output folder
+ dtype: fp16
+ mode: fixed
+ linear: 64
+ conv: 32
+
+ # process 2
+ - type: locon
+ output_path: "/absolute/path/for/this/output.safetensors" # can be absolute
+ mode: ratio
+ linear: 0.2
+ conv: 0.2
+
+ # process 3
+ - type: locon
+ filename: "[name]_ratio_02.safetensors"
+ mode: quantile
+ linear: 0.5
+ conv: 0.5
+
+ # process 4
+ - type: lora # traditional lora extraction (lierla) with linear layers only
+ filename: "[name]_4.safetensors"
+ mode: fixed # fixed, ratio, quantile supported for lora as well
+ linear: 4 # lora dim or rank
+ # no conv for lora
+
+ # process 5
+ - type: lora
+ filename: "[name]_q05.safetensors"
+ mode: quantile
+ linear: 0.5
+
+# you can put any information you want here, and it will be saved in the model
+# the below is an example. I recommend doing trigger words at a minimum
+# in the metadata. The software will include this plus some other information
+meta:
+ name: "[name]" # [name] gets replaced with the name above
+ description: A short description of your model
+ trigger_words:
+ - put
+ - trigger
+ - words
+ - here
+ version: '0.1'
+ creator:
+ name: Your Name
+ email: your@email.com
+ website: https://yourwebsite.com
+ any: All meta data above is arbitrary, it can be whatever you want.
diff --git a/ai-toolkit/config/examples/generate.example.yaml b/ai-toolkit/config/examples/generate.example.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1a3e19efdfee6f6215f37bb741a7b12e7c5ad484
--- /dev/null
+++ b/ai-toolkit/config/examples/generate.example.yaml
@@ -0,0 +1,60 @@
+---
+
+job: generate # tells the runner what to do
+config:
+ name: "generate" # this is not really used anywhere currently but required by runner
+ process:
+ # process 1
+ - type: to_folder # process images to a folder
+ output_folder: "output/gen"
+ device: cuda:0 # cpu, cuda:0, etc
+ generate:
+ # these are your defaults you can override most of them with flags
+ sampler: "ddpm" # ignored for now, will add later though ddpm is used regardless for now
+ width: 1024
+ height: 1024
+ neg: "cartoon, fake, drawing, illustration, cgi, animated, anime"
+ seed: -1 # -1 is random
+ guidance_scale: 7
+ sample_steps: 20
+ ext: ".png" # .png, .jpg, .jpeg, .webp
+
+ # here ate the flags you can use for prompts. Always start with
+ # your prompt first then add these flags after. You can use as many
+ # like
+ # photo of a baseball --n painting, ugly --w 1024 --h 1024 --seed 42 --cfg 7 --steps 20
+ # we will try to support all sd-scripts flags where we can
+
+ # FROM SD-SCRIPTS
+ # --n Treat everything until the next option as a negative prompt.
+ # --w Specify the width of the generated image.
+ # --h Specify the height of the generated image.
+ # --d Specify the seed for the generated image.
+ # --l Specify the CFG scale for the generated image.
+ # --s Specify the number of steps during generation.
+
+ # OURS and some QOL additions
+ # --p2 Prompt for the second text encoder (SDXL only)
+ # --n2 Negative prompt for the second text encoder (SDXL only)
+ # --gr Specify the guidance rescale for the generated image (SDXL only)
+ # --seed Specify the seed for the generated image same as --d
+ # --cfg Specify the CFG scale for the generated image same as --l
+ # --steps Specify the number of steps during generation same as --s
+
+ prompt_file: false # if true a txt file will be created next to images with prompt strings used
+ # prompts can also be a path to a text file with one prompt per line
+ # prompts: "/path/to/prompts.txt"
+ prompts:
+ - "photo of batman"
+ - "photo of superman"
+ - "photo of spiderman"
+ - "photo of a superhero --n batman superman spiderman"
+
+ model:
+ # huggingface name, relative prom project path, or absolute path to .safetensors or .ckpt
+ # name_or_path: "runwayml/stable-diffusion-v1-5"
+ name_or_path: "/mnt/Models/stable-diffusion/models/stable-diffusion/Ostris/Ostris_Real_v1.safetensors"
+ is_v2: false # for v2 models
+ is_v_pred: false # for v-prediction models (most v2 models)
+ is_xl: false # for SDXL models
+ dtype: bf16
diff --git a/ai-toolkit/config/examples/mod_lora_scale.yaml b/ai-toolkit/config/examples/mod_lora_scale.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5f59ecc838b1e4a4465600a67ddb690331ba3255
--- /dev/null
+++ b/ai-toolkit/config/examples/mod_lora_scale.yaml
@@ -0,0 +1,48 @@
+---
+job: mod
+config:
+ name: name_of_your_model_v1
+ process:
+ - type: rescale_lora
+ # path to your current lora model
+ input_path: "/path/to/lora/lora.safetensors"
+ # output path for your new lora model, can be the same as input_path to replace
+ output_path: "/path/to/lora/output_lora_v1.safetensors"
+ # replaces meta with the meta below (plus minimum meta fields)
+ # if false, we will leave the meta alone except for updating hashes (sd-script hashes)
+ replace_meta: true
+ # how to adjust, we can scale the up_down weights or the alpha
+ # up_down is the default and probably the best, they will both net the same outputs
+ # would only affect rare NaN cases and maybe merging with old merge tools
+ scale_target: 'up_down'
+ # precision to save, fp16 is the default and standard
+ save_dtype: fp16
+ # current_weight is the ideal weight you use as a multiplier when using the lora
+ # IE in automatic1111
+
+Troubleshooting issues
+If you’re not getting any output when starting a training job from the UI, it’s probably crashing before the process started, the best way to debug these issues is to run the python training script directly (which is normally started by the UI). To do this, set up a training job in the UI, go to the advanced config screen, copy and paste the configuration into a file like train.yaml, then run the training script like this with the conda virtual environment active: + +``` +python run.py path/to/train.yaml +``` +\ No newline at end of file diff --git a/ai-toolkit/dgx_requirements.txt b/ai-toolkit/dgx_requirements.txt new file mode 100644 index 0000000000000000000000000000000000000000..e8e507e664b955cf66b2618b599c2250987d6861 --- /dev/null +++ b/ai-toolkit/dgx_requirements.txt @@ -0,0 +1,13 @@ +# You need to use Python 3.11, the easiest way to get this on DGX OS without impacting the system version of Python is to create an environment with miniconda. + +# specific dependency versions needed on DGX OS devices: +scipy==1.16.0 +tifffile==2025.6.11 +imageio==2.37.0 +scikit_image==0.25.2 +clean_fid==0.1.35 +pywavelets==1.9.0 +contourpy==1.3.3 +opencv_python_headless==4.11.0.86 + +-r requirements_base.txt diff --git a/ai-toolkit/docker-compose.yml b/ai-toolkit/docker-compose.yml new file mode 100644 index 0000000000000000000000000000000000000000..bdf86aedeb608eff11324e4761e0a8a4584b07bf --- /dev/null +++ b/ai-toolkit/docker-compose.yml @@ -0,0 +1,25 @@ +version: "3.8" + +services: + ai-toolkit: + image: ostris/aitoolkit:latest + restart: unless-stopped + ports: + - "8675:8675" + volumes: + - ~/.cache/huggingface/hub:/root/.cache/huggingface/hub + - ./aitk_db.db:/app/ai-toolkit/aitk_db.db + - ./datasets:/app/ai-toolkit/datasets + - ./output:/app/ai-toolkit/output + - ./config:/app/ai-toolkit/config + environment: + - AI_TOOLKIT_AUTH=${AI_TOOLKIT_AUTH:-password} + - NODE_ENV=production + - TZ=UTC + deploy: + resources: + reservations: + devices: + - driver: nvidia + count: all + capabilities: [gpu] diff --git a/ai-toolkit/docker/Dockerfile b/ai-toolkit/docker/Dockerfile new file mode 100644 index 0000000000000000000000000000000000000000..e7208f2e97f0ed0dc9b1384c825d36cc2d9c5063 --- /dev/null +++ b/ai-toolkit/docker/Dockerfile @@ -0,0 +1,108 @@ +FROM nvidia/cuda:12.8.1-devel-ubuntu24.04 + +LABEL authors="jaret" + +# Set noninteractive to avoid timezone prompts +ENV DEBIAN_FRONTEND=noninteractive + +# ref https://en.wikipedia.org/wiki/CUDA +ENV TORCH_CUDA_ARCH_LIST="8.0 8.6 8.9 9.0 10.0 12.0" + +# Install dependencies +RUN apt-get update && apt-get install --no-install-recommends -y \ + git \ + curl \ + build-essential \ + cmake \ + wget \ + python3.12 \ + python3-pip \ + python3-dev \ + python3-setuptools \ + python3-wheel \ + python3-venv \ + ffmpeg \ + tmux \ + htop \ + nvtop \ + python3-opencv \ + openssh-client \ + openssh-server \ + openssl \ + rsync \ + unzip \ + && apt-get clean \ + && rm -rf /var/lib/apt/lists/* + +# Install nodejs +WORKDIR /tmp +RUN curl -sL https://deb.nodesource.com/setup_23.x -o nodesource_setup.sh && \ + bash nodesource_setup.sh && \ + apt-get update && \ + apt-get install -y nodejs && \ + apt-get clean && \ + rm -rf /var/lib/apt/lists/* + +WORKDIR /app + +# Set aliases for python and pip +RUN ln -s /usr/bin/python3 /usr/bin/python + +# install pytorch before cache bust to avoid redownloading pytorch +RUN pip install --no-cache-dir torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://download.pytorch.org/whl/cu128 --break-system-packages + +WORKDIR /app/ai-toolkit + +# ---------------------------------------------------------------------------- # +# Dependency layers come BEFORE the source clone so they are only rebuilt (and +# only need to be re-pulled by servers) when the dependency manifests change, +# not on every code change. +# ---------------------------------------------------------------------------- # + +# Install Python dependencies (only re-runs when the requirements files change) +COPY requirements.txt requirements_base.txt /app/ai-toolkit/ +RUN pip install --no-cache-dir --break-system-packages -r requirements.txt && \ + pip install setuptools==69.5.1 --no-cache-dir --break-system-packages + +# Install Node dependencies (only re-runs when package.json / package-lock.json change) +COPY ui/package.json ui/package-lock.json /app/ai-toolkit/ui/ +RUN cd /app/ai-toolkit/ui && npm ci + +# ---------------------------------------------------------------------------- # +# Source code comes LAST. Only this layer (plus the UI build below) is rebuilt +# on a code change, so servers only re-pull the (small) source, not the deps. +# Clone to a temp dir and rsync the source in, preserving the dependency dirs +# already populated above (ui/node_modules) and the manifests already used. +# ---------------------------------------------------------------------------- # +ARG CACHEBUST=1234 +ARG GIT_COMMIT=main +RUN echo "Cache bust: ${CACHEBUST}" && \ + git clone https://github.com/ostris/ai-toolkit.git /tmp/ai-toolkit-src && \ + cd /tmp/ai-toolkit-src && \ + git checkout ${GIT_COMMIT} && \ + rsync -a --delete \ + --exclude 'ui/node_modules' \ + --exclude 'requirements.txt' \ + --exclude 'ui/package.json' \ + --exclude 'ui/package-lock.json' \ + /tmp/ai-toolkit-src/ /app/ai-toolkit/ && \ + rm -rf /tmp/ai-toolkit-src + +# Build UI (re-runs on code change, but reuses the cached node_modules above). +# update_db runs first because it does `prisma generate`, which creates the +# @prisma/client types the TS build needs. In the old layout generate happened +# as a side effect of npm install seeing the schema; now the source arrives +# after npm ci, so run it explicitly before the build. +RUN cd /app/ai-toolkit/ui && \ + npm run update_db && \ + npm run build + +# Expose port (assuming the application runs on port 3000) +EXPOSE 8675 + +WORKDIR / + +COPY docker/start.sh /start.sh +RUN chmod +x /start.sh + +CMD ["/start.sh"] \ No newline at end of file diff --git a/ai-toolkit/docker/start.sh b/ai-toolkit/docker/start.sh new file mode 100644 index 0000000000000000000000000000000000000000..abcbca0500d7d728d954d755cad29bfc3ce56f79 --- /dev/null +++ b/ai-toolkit/docker/start.sh @@ -0,0 +1,70 @@ +#!/bin/bash +set -e # Exit the script if any statement returns a non-true return value + +# ref https://github.com/runpod/containers/blob/main/container-template/start.sh + +# ---------------------------------------------------------------------------- # +# Function Definitions # +# ---------------------------------------------------------------------------- # + + +# Setup ssh +setup_ssh() { + if [[ $PUBLIC_KEY ]]; then + echo "Setting up SSH..." + mkdir -p ~/.ssh + echo "$PUBLIC_KEY" >> ~/.ssh/authorized_keys + chmod 700 -R ~/.ssh + + if [ ! -f /etc/ssh/ssh_host_rsa_key ]; then + ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key -q -N '' + echo "RSA key fingerprint:" + ssh-keygen -lf /etc/ssh/ssh_host_rsa_key.pub + fi + + if [ ! -f /etc/ssh/ssh_host_dsa_key ]; then + ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key -q -N '' + echo "DSA key fingerprint:" + ssh-keygen -lf /etc/ssh/ssh_host_dsa_key.pub + fi + + if [ ! -f /etc/ssh/ssh_host_ecdsa_key ]; then + ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -q -N '' + echo "ECDSA key fingerprint:" + ssh-keygen -lf /etc/ssh/ssh_host_ecdsa_key.pub + fi + + if [ ! -f /etc/ssh/ssh_host_ed25519_key ]; then + ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key -q -N '' + echo "ED25519 key fingerprint:" + ssh-keygen -lf /etc/ssh/ssh_host_ed25519_key.pub + fi + + service ssh start + + echo "SSH host keys:" + for key in /etc/ssh/*.pub; do + echo "Key: $key" + ssh-keygen -lf $key + done + fi +} + +# Export env vars +export_env_vars() { + echo "Exporting environment variables..." + printenv | grep -E '^RUNPOD_|^PATH=|^_=' | awk -F = '{ print "export " $1 "=\"" $2 "\"" }' >> /etc/rp_environment + echo 'source /etc/rp_environment' >> ~/.bashrc +} + +# ---------------------------------------------------------------------------- # +# Main Program # +# ---------------------------------------------------------------------------- # + + +echo "Pod Started" + +setup_ssh +export_env_vars +echo "Starting AI Toolkit UI..." +cd /app/ai-toolkit/ui && npm run start \ No newline at end of file diff --git a/ai-toolkit/extensions/example/ExampleMergeModels.py b/ai-toolkit/extensions/example/ExampleMergeModels.py new file mode 100644 index 0000000000000000000000000000000000000000..162d514c38799b1c5cdc4717e1fa9867a4b35572 --- /dev/null +++ b/ai-toolkit/extensions/example/ExampleMergeModels.py @@ -0,0 +1,129 @@ +import torch +import gc +from collections import OrderedDict +from typing import TYPE_CHECKING +from jobs.process import BaseExtensionProcess +from toolkit.config_modules import ModelConfig +from toolkit.stable_diffusion_model import StableDiffusion +from toolkit.train_tools import get_torch_dtype +from tqdm import tqdm + +# Type check imports. Prevents circular imports +if TYPE_CHECKING: + from jobs import ExtensionJob + + +# extend standard config classes to add weight +class ModelInputConfig(ModelConfig): + def __init__(self, **kwargs): + super().__init__(**kwargs) + self.weight = kwargs.get('weight', 1.0) + # overwrite default dtype unless user specifies otherwise + # float 32 will give up better precision on the merging functions + self.dtype: str = kwargs.get('dtype', 'float32') + + +def flush(): + torch.cuda.empty_cache() + gc.collect() + + +# this is our main class process +class ExampleMergeModels(BaseExtensionProcess): + def __init__( + self, + process_id: int, + job: 'ExtensionJob', + config: OrderedDict + ): + super().__init__(process_id, job, config) + # this is the setup process, do not do process intensive stuff here, just variable setup and + # checking requirements. This is called before the run() function + # no loading models or anything like that, it is just for setting up the process + # all of your process intensive stuff should be done in the run() function + # config will have everything from the process item in the config file + + # convince methods exist on BaseProcess to get config values + # if required is set to true and the value is not found it will throw an error + # you can pass a default value to get_conf() as well if it was not in the config file + # as well as a type to cast the value to + self.save_path = self.get_conf('save_path', required=True) + self.save_dtype = self.get_conf('save_dtype', default='float16', as_type=get_torch_dtype) + self.device = self.get_conf('device', default='cpu', as_type=torch.device) + + # build models to merge list + models_to_merge = self.get_conf('models_to_merge', required=True, as_type=list) + # build list of ModelInputConfig objects. I find it is a good idea to make a class for each config + # this way you can add methods to it and it is easier to read and code. There are a lot of + # inbuilt config classes located in toolkit.config_modules as well + self.models_to_merge = [ModelInputConfig(**model) for model in models_to_merge] + # setup is complete. Don't load anything else here, just setup variables and stuff + + # this is the entire run process be sure to call super().run() first + def run(self): + # always call first + super().run() + print(f"Running process: {self.__class__.__name__}") + + # let's adjust our weights first to normalize them so the total is 1.0 + total_weight = sum([model.weight for model in self.models_to_merge]) + weight_adjust = 1.0 / total_weight + for model in self.models_to_merge: + model.weight *= weight_adjust + + output_model: StableDiffusion = None + # let's do the merge, it is a good idea to use tqdm to show progress + for model_config in tqdm(self.models_to_merge, desc="Merging models"): + # setup model class with our helper class + sd_model = StableDiffusion( + device=self.device, + model_config=model_config, + dtype="float32" + ) + # load the model + sd_model.load_model() + + # adjust the weight of the text encoder + if isinstance(sd_model.text_encoder, list): + # sdxl model + for text_encoder in sd_model.text_encoder: + for key, value in text_encoder.state_dict().items(): + value *= model_config.weight + else: + # normal model + for key, value in sd_model.text_encoder.state_dict().items(): + value *= model_config.weight + # adjust the weights of the unet + for key, value in sd_model.unet.state_dict().items(): + value *= model_config.weight + + if output_model is None: + # use this one as the base + output_model = sd_model + else: + # merge the models + # text encoder + if isinstance(output_model.text_encoder, list): + # sdxl model + for i, text_encoder in enumerate(output_model.text_encoder): + for key, value in text_encoder.state_dict().items(): + value += sd_model.text_encoder[i].state_dict()[key] + else: + # normal model + for key, value in output_model.text_encoder.state_dict().items(): + value += sd_model.text_encoder.state_dict()[key] + # unet + for key, value in output_model.unet.state_dict().items(): + value += sd_model.unet.state_dict()[key] + + # remove the model to free memory + del sd_model + flush() + + # merge loop is done, let's save the model + print(f"Saving merged model to {self.save_path}") + output_model.save(self.save_path, meta=self.meta, save_dtype=self.save_dtype) + print(f"Saved merged model to {self.save_path}") + # do cleanup here + del output_model + flush() diff --git a/ai-toolkit/extensions/example/__init__.py b/ai-toolkit/extensions/example/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..34f348f1a1c278d7b71d48a60d5ddf909141b7db --- /dev/null +++ b/ai-toolkit/extensions/example/__init__.py @@ -0,0 +1,25 @@ +# This is an example extension for custom training. It is great for experimenting with new ideas. +from toolkit.extension import Extension + + +# We make a subclass of Extension +class ExampleMergeExtension(Extension): + # uid must be unique, it is how the extension is identified + uid = "example_merge_extension" + + # name is the name of the extension for printing + name = "Example Merge Extension" + + # This is where your process class is loaded + # keep your imports in here so they don't slow down the rest of the program + @classmethod + def get_process(cls): + # import your process class here so it is only loaded when needed and return it + from .ExampleMergeModels import ExampleMergeModels + return ExampleMergeModels + + +AI_TOOLKIT_EXTENSIONS = [ + # you can put a list of extensions here + ExampleMergeExtension +] diff --git a/ai-toolkit/extensions/example/config/config.example.yaml b/ai-toolkit/extensions/example/config/config.example.yaml new file mode 100644 index 0000000000000000000000000000000000000000..abed03fd9e9197e072a73203c67ad7ee976912cd --- /dev/null +++ b/ai-toolkit/extensions/example/config/config.example.yaml @@ -0,0 +1,48 @@ +--- +# Always include at least one example config file to show how to use your extension. +# use plenty of comments so users know how to use it and what everything does + +# all extensions will use this job name +job: extension +config: + name: 'my_awesome_merge' + process: + # Put your example processes here. This will be passed + # to your extension process in the config argument. + # the type MUST match your extension uid + - type: "example_merge_extension" + # save path for the merged model + save_path: "output/merge/[name].safetensors" + # save type + dtype: fp16 + # device to run it on + device: cuda:0 + # input models can only be SD1.x and SD2.x models for this example (currently) + models_to_merge: + # weights are relative, total weights will be normalized + # for example. If you have 2 models with weight 1.0, they will + # both be weighted 0.5. If you have 1 model with weight 1.0 and + # another with weight 2.0, the first will be weighted 1/3 and the + # second will be weighted 2/3 + - name_or_path: "input/model1.safetensors" + weight: 1.0 + - name_or_path: "input/model2.safetensors" + weight: 1.0 + - name_or_path: "input/model3.safetensors" + weight: 0.3 + - name_or_path: "input/model4.safetensors" + weight: 1.0 + + +# you can put any information you want here, and it will be saved in the model +# the below is an example. I recommend doing trigger words at a minimum +# in the metadata. The software will include this plus some other information +meta: + name: "[name]" # [name] gets replaced with the name above + description: A short description of your model + version: '0.1' + creator: + name: Your Name + email: your@email.com + website: https://yourwebsite.com + any: All meta data above is arbitrary, it can be whatever you want. \ No newline at end of file diff --git a/ai-toolkit/extensions_built_in/advanced_generator/Img2ImgGenerator.py b/ai-toolkit/extensions_built_in/advanced_generator/Img2ImgGenerator.py new file mode 100644 index 0000000000000000000000000000000000000000..58713bd0c570e1240811cefd8e8b1f390346c069 --- /dev/null +++ b/ai-toolkit/extensions_built_in/advanced_generator/Img2ImgGenerator.py @@ -0,0 +1,256 @@ +import math +import os +import random +from collections import OrderedDict +from typing import List + +import numpy as np +from PIL import Image +from diffusers import T2IAdapter +from diffusers.utils.torch_utils import randn_tensor +from torch.utils.data import DataLoader +from diffusers import StableDiffusionXLImg2ImgPipeline, PixArtSigmaPipeline +from tqdm import tqdm + +from toolkit.config_modules import ModelConfig, GenerateImageConfig, preprocess_dataset_raw_config, DatasetConfig +from toolkit.data_transfer_object.data_loader import FileItemDTO, DataLoaderBatchDTO +from toolkit.sampler import get_sampler +from toolkit.stable_diffusion_model import StableDiffusion +import gc +import torch +from jobs.process import BaseExtensionProcess +from toolkit.data_loader import get_dataloader_from_datasets +from toolkit.train_tools import get_torch_dtype +from controlnet_aux.midas import MidasDetector +from diffusers.utils import load_image +from torchvision.transforms import ToTensor + + +def flush(): + torch.cuda.empty_cache() + gc.collect() + + + + + +class GenerateConfig: + + def __init__(self, **kwargs): + self.prompts: List[str] + self.sampler = kwargs.get('sampler', 'ddpm') + self.neg = kwargs.get('neg', '') + self.seed = kwargs.get('seed', -1) + self.walk_seed = kwargs.get('walk_seed', False) + self.guidance_scale = kwargs.get('guidance_scale', 7) + self.sample_steps = kwargs.get('sample_steps', 20) + self.guidance_rescale = kwargs.get('guidance_rescale', 0.0) + self.ext = kwargs.get('ext', 'png') + self.denoise_strength = kwargs.get('denoise_strength', 0.5) + self.trigger_word = kwargs.get('trigger_word', None) + + +class Img2ImgGenerator(BaseExtensionProcess): + + def __init__(self, process_id: int, job, config: OrderedDict): + super().__init__(process_id, job, config) + self.output_folder = self.get_conf('output_folder', required=True) + self.copy_inputs_to = self.get_conf('copy_inputs_to', None) + self.device = self.get_conf('device', 'cuda') + self.model_config = ModelConfig(**self.get_conf('model', required=True)) + self.generate_config = GenerateConfig(**self.get_conf('generate', required=True)) + self.is_latents_cached = True + raw_datasets = self.get_conf('datasets', None) + if raw_datasets is not None and len(raw_datasets) > 0: + raw_datasets = preprocess_dataset_raw_config(raw_datasets) + self.datasets = None + self.datasets_reg = None + self.dtype = self.get_conf('dtype', 'float16') + self.torch_dtype = get_torch_dtype(self.dtype) + self.params = [] + if raw_datasets is not None and len(raw_datasets) > 0: + for raw_dataset in raw_datasets: + dataset = DatasetConfig(**raw_dataset) + is_caching = dataset.cache_latents or dataset.cache_latents_to_disk + if not is_caching: + self.is_latents_cached = False + if dataset.is_reg: + if self.datasets_reg is None: + self.datasets_reg = [] + self.datasets_reg.append(dataset) + else: + if self.datasets is None: + self.datasets = [] + self.datasets.append(dataset) + + self.progress_bar = None + self.sd = StableDiffusion( + device=self.device, + model_config=self.model_config, + dtype=self.dtype, + ) + print(f"Using device {self.device}") + self.data_loader: DataLoader = None + self.adapter: T2IAdapter = None + + def to_pil(self, img): + # image comes in -1 to 1. convert to a PIL RGB image + img = (img + 1) / 2 + img = img.clamp(0, 1) + img = img[0].permute(1, 2, 0).cpu().numpy() + img = (img * 255).astype(np.uint8) + image = Image.fromarray(img) + return image + + def run(self): + with torch.no_grad(): + super().run() + print("Loading model...") + self.sd.load_model() + device = torch.device(self.device) + + if self.model_config.is_xl: + pipe = StableDiffusionXLImg2ImgPipeline( + vae=self.sd.vae, + unet=self.sd.unet, + text_encoder=self.sd.text_encoder[0], + text_encoder_2=self.sd.text_encoder[1], + tokenizer=self.sd.tokenizer[0], + tokenizer_2=self.sd.tokenizer[1], + scheduler=get_sampler(self.generate_config.sampler), + ).to(device, dtype=self.torch_dtype) + elif self.model_config.is_pixart: + pipe = self.sd.pipeline.to(device, dtype=self.torch_dtype) + else: + raise NotImplementedError("Only XL models are supported") + pipe.set_progress_bar_config(disable=True) + + # pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True) + # midas_depth = torch.compile(midas_depth, mode="reduce-overhead", fullgraph=True) + + self.data_loader = get_dataloader_from_datasets(self.datasets, 1, self.sd) + + num_batches = len(self.data_loader) + pbar = tqdm(total=num_batches, desc="Generating images") + seed = self.generate_config.seed + # load images from datasets, use tqdm + for i, batch in enumerate(self.data_loader): + batch: DataLoaderBatchDTO = batch + + gen_seed = seed if seed > 0 else random.randint(0, 2 ** 32 - 1) + generator = torch.manual_seed(gen_seed) + + file_item: FileItemDTO = batch.file_items[0] + img_path = file_item.path + img_filename = os.path.basename(img_path) + img_filename_no_ext = os.path.splitext(img_filename)[0] + img_filename = img_filename_no_ext + '.' + self.generate_config.ext + output_path = os.path.join(self.output_folder, img_filename) + output_caption_path = os.path.join(self.output_folder, img_filename_no_ext + '.txt') + + if self.copy_inputs_to is not None: + output_inputs_path = os.path.join(self.copy_inputs_to, img_filename) + output_inputs_caption_path = os.path.join(self.copy_inputs_to, img_filename_no_ext + '.txt') + else: + output_inputs_path = None + output_inputs_caption_path = None + + caption = batch.get_caption_list()[0] + if self.generate_config.trigger_word is not None: + caption = caption.replace('[trigger]', self.generate_config.trigger_word) + + img: torch.Tensor = batch.tensor.clone() + image = self.to_pil(img) + + # image.save(output_depth_path) + if self.model_config.is_pixart: + pipe: PixArtSigmaPipeline = pipe + + # Encode the full image once + encoded_image = pipe.vae.encode( + pipe.image_processor.preprocess(image).to(device=pipe.device, dtype=pipe.dtype)) + if hasattr(encoded_image, "latent_dist"): + latents = encoded_image.latent_dist.sample(generator) + elif hasattr(encoded_image, "latents"): + latents = encoded_image.latents + else: + raise AttributeError("Could not access latents of provided encoder_output") + latents = pipe.vae.config.scaling_factor * latents + + # latents = self.sd.encode_images(img) + + # self.sd.noise_scheduler.set_timesteps(self.generate_config.sample_steps) + # start_step = math.floor(self.generate_config.sample_steps * self.generate_config.denoise_strength) + # timestep = self.sd.noise_scheduler.timesteps[start_step].unsqueeze(0) + # timestep = timestep.to(device, dtype=torch.int32) + # latent = latent.to(device, dtype=self.torch_dtype) + # noise = torch.randn_like(latent, device=device, dtype=self.torch_dtype) + # latent = self.sd.add_noise(latent, noise, timestep) + # timesteps_to_use = self.sd.noise_scheduler.timesteps[start_step + 1:] + batch_size = 1 + num_images_per_prompt = 1 + + shape = (batch_size, pipe.transformer.config.in_channels, image.height // pipe.vae_scale_factor, + image.width // pipe.vae_scale_factor) + noise = randn_tensor(shape, generator=generator, device=pipe.device, dtype=pipe.dtype) + + # noise = torch.randn_like(latents, device=device, dtype=self.torch_dtype) + num_inference_steps = self.generate_config.sample_steps + strength = self.generate_config.denoise_strength + # Get timesteps + init_timestep = min(int(num_inference_steps * strength), num_inference_steps) + t_start = max(num_inference_steps - init_timestep, 0) + pipe.scheduler.set_timesteps(num_inference_steps, device="cpu") + timesteps = pipe.scheduler.timesteps[t_start:] + timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt) + latents = pipe.scheduler.add_noise(latents, noise, timestep) + + gen_images = pipe.__call__( + prompt=caption, + negative_prompt=self.generate_config.neg, + latents=latents, + timesteps=timesteps, + width=image.width, + height=image.height, + num_inference_steps=num_inference_steps, + num_images_per_prompt=num_images_per_prompt, + guidance_scale=self.generate_config.guidance_scale, + # strength=self.generate_config.denoise_strength, + use_resolution_binning=False, + output_type="np" + ).images[0] + gen_images = (gen_images * 255).clip(0, 255).astype(np.uint8) + gen_images = Image.fromarray(gen_images) + else: + pipe: StableDiffusionXLImg2ImgPipeline = pipe + + gen_images = pipe.__call__( + prompt=caption, + negative_prompt=self.generate_config.neg, + image=image, + num_inference_steps=self.generate_config.sample_steps, + guidance_scale=self.generate_config.guidance_scale, + strength=self.generate_config.denoise_strength, + ).images[0] + os.makedirs(os.path.dirname(output_path), exist_ok=True) + gen_images.save(output_path) + + # save caption + with open(output_caption_path, 'w') as f: + f.write(caption) + + if output_inputs_path is not None: + os.makedirs(os.path.dirname(output_inputs_path), exist_ok=True) + image.save(output_inputs_path) + with open(output_inputs_caption_path, 'w') as f: + f.write(caption) + + pbar.update(1) + batch.cleanup() + + pbar.close() + print("Done generating images") + # cleanup + del self.sd + gc.collect() + torch.cuda.empty_cache() diff --git a/ai-toolkit/extensions_built_in/advanced_generator/PureLoraGenerator.py b/ai-toolkit/extensions_built_in/advanced_generator/PureLoraGenerator.py new file mode 100644 index 0000000000000000000000000000000000000000..ec19da317230f5a837ebc6561fd4dc7cac2fd946 --- /dev/null +++ b/ai-toolkit/extensions_built_in/advanced_generator/PureLoraGenerator.py @@ -0,0 +1,102 @@ +import os +from collections import OrderedDict + +from toolkit.config_modules import ModelConfig, GenerateImageConfig, SampleConfig, LoRMConfig +from toolkit.lorm import ExtractMode, convert_diffusers_unet_to_lorm +from toolkit.sd_device_states_presets import get_train_sd_device_state_preset +from toolkit.stable_diffusion_model import StableDiffusion +import gc +import torch +from jobs.process import BaseExtensionProcess +from toolkit.train_tools import get_torch_dtype + + +def flush(): + torch.cuda.empty_cache() + gc.collect() + + +class PureLoraGenerator(BaseExtensionProcess): + + def __init__(self, process_id: int, job, config: OrderedDict): + super().__init__(process_id, job, config) + self.output_folder = self.get_conf('output_folder', required=True) + self.device = self.get_conf('device', 'cuda') + self.device_torch = torch.device(self.device) + self.model_config = ModelConfig(**self.get_conf('model', required=True)) + self.generate_config = SampleConfig(**self.get_conf('sample', required=True)) + self.dtype = self.get_conf('dtype', 'float16') + self.torch_dtype = get_torch_dtype(self.dtype) + lorm_config = self.get_conf('lorm', None) + self.lorm_config = LoRMConfig(**lorm_config) if lorm_config is not None else None + + self.device_state_preset = get_train_sd_device_state_preset( + device=torch.device(self.device), + ) + + self.progress_bar = None + self.sd = StableDiffusion( + device=self.device, + model_config=self.model_config, + dtype=self.dtype, + ) + + def run(self): + super().run() + print("Loading model...") + with torch.no_grad(): + self.sd.load_model() + self.sd.unet.eval() + self.sd.unet.to(self.device_torch) + if isinstance(self.sd.text_encoder, list): + for te in self.sd.text_encoder: + te.eval() + te.to(self.device_torch) + else: + self.sd.text_encoder.eval() + self.sd.to(self.device_torch) + + print(f"Converting to LoRM UNet") + # replace the unet with LoRMUnet + convert_diffusers_unet_to_lorm( + self.sd.unet, + config=self.lorm_config, + ) + + sample_folder = os.path.join(self.output_folder) + gen_img_config_list = [] + + sample_config = self.generate_config + start_seed = sample_config.seed + current_seed = start_seed + for i in range(len(sample_config.prompts)): + if sample_config.walk_seed: + current_seed = start_seed + i + + filename = f"[time]_[count].{self.generate_config.ext}" + output_path = os.path.join(sample_folder, filename) + prompt = sample_config.prompts[i] + extra_args = {} + gen_img_config_list.append(GenerateImageConfig( + prompt=prompt, # it will autoparse the prompt + width=sample_config.width, + height=sample_config.height, + negative_prompt=sample_config.neg, + seed=current_seed, + guidance_scale=sample_config.guidance_scale, + guidance_rescale=sample_config.guidance_rescale, + num_inference_steps=sample_config.sample_steps, + network_multiplier=sample_config.network_multiplier, + output_path=output_path, + output_ext=sample_config.ext, + adapter_conditioning_scale=sample_config.adapter_conditioning_scale, + **extra_args + )) + + # send to be generated + self.sd.generate_images(gen_img_config_list, sampler=sample_config.sampler) + print("Done generating images") + # cleanup + del self.sd + gc.collect() + torch.cuda.empty_cache() diff --git a/ai-toolkit/extensions_built_in/advanced_generator/ReferenceGenerator.py b/ai-toolkit/extensions_built_in/advanced_generator/ReferenceGenerator.py new file mode 100644 index 0000000000000000000000000000000000000000..19e3b6e55786cde2ddcebfdc60230223dc443b62 --- /dev/null +++ b/ai-toolkit/extensions_built_in/advanced_generator/ReferenceGenerator.py @@ -0,0 +1,212 @@ +import os +import random +from collections import OrderedDict +from typing import List + +import numpy as np +from PIL import Image +from diffusers import T2IAdapter +from torch.utils.data import DataLoader +from diffusers import StableDiffusionXLAdapterPipeline, StableDiffusionAdapterPipeline +from tqdm import tqdm + +from toolkit.config_modules import ModelConfig, GenerateImageConfig, preprocess_dataset_raw_config, DatasetConfig +from toolkit.data_transfer_object.data_loader import FileItemDTO, DataLoaderBatchDTO +from toolkit.sampler import get_sampler +from toolkit.stable_diffusion_model import StableDiffusion +import gc +import torch +from jobs.process import BaseExtensionProcess +from toolkit.data_loader import get_dataloader_from_datasets +from toolkit.train_tools import get_torch_dtype +from controlnet_aux.midas import MidasDetector +from diffusers.utils import load_image + + +def flush(): + torch.cuda.empty_cache() + gc.collect() + + +class GenerateConfig: + + def __init__(self, **kwargs): + self.prompts: List[str] + self.sampler = kwargs.get('sampler', 'ddpm') + self.neg = kwargs.get('neg', '') + self.seed = kwargs.get('seed', -1) + self.walk_seed = kwargs.get('walk_seed', False) + self.t2i_adapter_path = kwargs.get('t2i_adapter_path', None) + self.guidance_scale = kwargs.get('guidance_scale', 7) + self.sample_steps = kwargs.get('sample_steps', 20) + self.prompt_2 = kwargs.get('prompt_2', None) + self.neg_2 = kwargs.get('neg_2', None) + self.prompts = kwargs.get('prompts', None) + self.guidance_rescale = kwargs.get('guidance_rescale', 0.0) + self.ext = kwargs.get('ext', 'png') + self.adapter_conditioning_scale = kwargs.get('adapter_conditioning_scale', 1.0) + if kwargs.get('shuffle', False): + # shuffle the prompts + random.shuffle(self.prompts) + + +class ReferenceGenerator(BaseExtensionProcess): + + def __init__(self, process_id: int, job, config: OrderedDict): + super().__init__(process_id, job, config) + self.output_folder = self.get_conf('output_folder', required=True) + self.device = self.get_conf('device', 'cuda') + self.model_config = ModelConfig(**self.get_conf('model', required=True)) + self.generate_config = GenerateConfig(**self.get_conf('generate', required=True)) + self.is_latents_cached = True + raw_datasets = self.get_conf('datasets', None) + if raw_datasets is not None and len(raw_datasets) > 0: + raw_datasets = preprocess_dataset_raw_config(raw_datasets) + self.datasets = None + self.datasets_reg = None + self.dtype = self.get_conf('dtype', 'float16') + self.torch_dtype = get_torch_dtype(self.dtype) + self.params = [] + if raw_datasets is not None and len(raw_datasets) > 0: + for raw_dataset in raw_datasets: + dataset = DatasetConfig(**raw_dataset) + is_caching = dataset.cache_latents or dataset.cache_latents_to_disk + if not is_caching: + self.is_latents_cached = False + if dataset.is_reg: + if self.datasets_reg is None: + self.datasets_reg = [] + self.datasets_reg.append(dataset) + else: + if self.datasets is None: + self.datasets = [] + self.datasets.append(dataset) + + self.progress_bar = None + self.sd = StableDiffusion( + device=self.device, + model_config=self.model_config, + dtype=self.dtype, + ) + print(f"Using device {self.device}") + self.data_loader: DataLoader = None + self.adapter: T2IAdapter = None + + def run(self): + super().run() + print("Loading model...") + self.sd.load_model() + device = torch.device(self.device) + + if self.generate_config.t2i_adapter_path is not None: + self.adapter = T2IAdapter.from_pretrained( + self.generate_config.t2i_adapter_path, + torch_dtype=self.torch_dtype, + varient="fp16" + ).to(device) + + midas_depth = MidasDetector.from_pretrained( + "valhalla/t2iadapter-aux-models", filename="dpt_large_384.pt", model_type="dpt_large" + ).to(device) + + if self.model_config.is_xl: + pipe = StableDiffusionXLAdapterPipeline( + vae=self.sd.vae, + unet=self.sd.unet, + text_encoder=self.sd.text_encoder[0], + text_encoder_2=self.sd.text_encoder[1], + tokenizer=self.sd.tokenizer[0], + tokenizer_2=self.sd.tokenizer[1], + scheduler=get_sampler(self.generate_config.sampler), + adapter=self.adapter, + ).to(device, dtype=self.torch_dtype) + else: + pipe = StableDiffusionAdapterPipeline( + vae=self.sd.vae, + unet=self.sd.unet, + text_encoder=self.sd.text_encoder, + tokenizer=self.sd.tokenizer, + scheduler=get_sampler(self.generate_config.sampler), + safety_checker=None, + feature_extractor=None, + requires_safety_checker=False, + adapter=self.adapter, + ).to(device, dtype=self.torch_dtype) + pipe.set_progress_bar_config(disable=True) + + pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True) + # midas_depth = torch.compile(midas_depth, mode="reduce-overhead", fullgraph=True) + + self.data_loader = get_dataloader_from_datasets(self.datasets, 1, self.sd) + + num_batches = len(self.data_loader) + pbar = tqdm(total=num_batches, desc="Generating images") + seed = self.generate_config.seed + # load images from datasets, use tqdm + for i, batch in enumerate(self.data_loader): + batch: DataLoaderBatchDTO = batch + + file_item: FileItemDTO = batch.file_items[0] + img_path = file_item.path + img_filename = os.path.basename(img_path) + img_filename_no_ext = os.path.splitext(img_filename)[0] + output_path = os.path.join(self.output_folder, img_filename) + output_caption_path = os.path.join(self.output_folder, img_filename_no_ext + '.txt') + output_depth_path = os.path.join(self.output_folder, img_filename_no_ext + '.depth.png') + + caption = batch.get_caption_list()[0] + + img: torch.Tensor = batch.tensor.clone() + # image comes in -1 to 1. convert to a PIL RGB image + img = (img + 1) / 2 + img = img.clamp(0, 1) + img = img[0].permute(1, 2, 0).cpu().numpy() + img = (img * 255).astype(np.uint8) + image = Image.fromarray(img) + + width, height = image.size + min_res = min(width, height) + + if self.generate_config.walk_seed: + seed = seed + 1 + + if self.generate_config.seed == -1: + # random + seed = random.randint(0, 1000000) + + torch.manual_seed(seed) + torch.cuda.manual_seed(seed) + + # generate depth map + image = midas_depth( + image, + detect_resolution=min_res, # do 512 ? + image_resolution=min_res + ) + + # image.save(output_depth_path) + + gen_images = pipe( + prompt=caption, + negative_prompt=self.generate_config.neg, + image=image, + num_inference_steps=self.generate_config.sample_steps, + adapter_conditioning_scale=self.generate_config.adapter_conditioning_scale, + guidance_scale=self.generate_config.guidance_scale, + ).images[0] + os.makedirs(os.path.dirname(output_path), exist_ok=True) + gen_images.save(output_path) + + # save caption + with open(output_caption_path, 'w') as f: + f.write(caption) + + pbar.update(1) + batch.cleanup() + + pbar.close() + print("Done generating images") + # cleanup + del self.sd + gc.collect() + torch.cuda.empty_cache() diff --git a/ai-toolkit/extensions_built_in/advanced_generator/__init__.py b/ai-toolkit/extensions_built_in/advanced_generator/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..65811655a991c84551d2915c7b04fa66c0d8fbaa --- /dev/null +++ b/ai-toolkit/extensions_built_in/advanced_generator/__init__.py @@ -0,0 +1,59 @@ +# This is an example extension for custom training. It is great for experimenting with new ideas. +from toolkit.extension import Extension + + +# This is for generic training (LoRA, Dreambooth, FineTuning) +class AdvancedReferenceGeneratorExtension(Extension): + # uid must be unique, it is how the extension is identified + uid = "reference_generator" + + # name is the name of the extension for printing + name = "Reference Generator" + + # This is where your process class is loaded + # keep your imports in here so they don't slow down the rest of the program + @classmethod + def get_process(cls): + # import your process class here so it is only loaded when needed and return it + from .ReferenceGenerator import ReferenceGenerator + return ReferenceGenerator + + +# This is for generic training (LoRA, Dreambooth, FineTuning) +class PureLoraGenerator(Extension): + # uid must be unique, it is how the extension is identified + uid = "pure_lora_generator" + + # name is the name of the extension for printing + name = "Pure LoRA Generator" + + # This is where your process class is loaded + # keep your imports in here so they don't slow down the rest of the program + @classmethod + def get_process(cls): + # import your process class here so it is only loaded when needed and return it + from .PureLoraGenerator import PureLoraGenerator + return PureLoraGenerator + + +# This is for generic training (LoRA, Dreambooth, FineTuning) +class Img2ImgGeneratorExtension(Extension): + # uid must be unique, it is how the extension is identified + uid = "batch_img2img" + + # name is the name of the extension for printing + name = "Img2ImgGeneratorExtension" + + # This is where your process class is loaded + # keep your imports in here so they don't slow down the rest of the program + @classmethod + def get_process(cls): + # import your process class here so it is only loaded when needed and return it + from .Img2ImgGenerator import Img2ImgGenerator + return Img2ImgGenerator + + +AI_TOOLKIT_EXTENSIONS = [ + # you can put a list of extensions here + AdvancedReferenceGeneratorExtension, PureLoraGenerator, Img2ImgGeneratorExtension +] diff --git a/ai-toolkit/extensions_built_in/advanced_generator/config/train.example.yaml b/ai-toolkit/extensions_built_in/advanced_generator/config/train.example.yaml new file mode 100644 index 0000000000000000000000000000000000000000..793d5d55b9a282d58b53f0e6fafba0b5aa66f7af --- /dev/null +++ b/ai-toolkit/extensions_built_in/advanced_generator/config/train.example.yaml @@ -0,0 +1,91 @@ +--- +job: extension +config: + name: test_v1 + process: + - type: 'textual_inversion_trainer' + training_folder: "out/TI" + device: cuda:0 + # for tensorboard logging + log_dir: "out/.tensorboard" + embedding: + trigger: "your_trigger_here" + tokens: 12 + init_words: "man with short brown hair" + save_format: "safetensors" # 'safetensors' or 'pt' + save: + dtype: float16 # precision to save + save_every: 100 # save every this many steps + max_step_saves_to_keep: 5 # only affects step counts + datasets: + - folder_path: "/path/to/dataset" + caption_ext: "txt" + default_caption: "[trigger]" + buckets: true + resolution: 512 + train: + noise_scheduler: "ddpm" # or "ddpm", "lms", "euler_a" + steps: 3000 + weight_jitter: 0.0 + lr: 5e-5 + train_unet: false + gradient_checkpointing: true + train_text_encoder: false + optimizer: "adamw" +# optimizer: "prodigy" + optimizer_params: + weight_decay: 1e-2 + lr_scheduler: "constant" + max_denoising_steps: 1000 + batch_size: 4 + dtype: bf16 + xformers: true + min_snr_gamma: 5.0 +# skip_first_sample: true + noise_offset: 0.0 # not needed for this + model: + # objective reality v2 + name_or_path: "https://civitai.com/models/128453?modelVersionId=142465" + is_v2: false # for v2 models + is_xl: false # for SDXL models + is_v_pred: false # for v-prediction models (most v2 models) + sample: + sampler: "ddpm" # must match train.noise_scheduler + sample_every: 100 # sample every this many steps + width: 512 + height: 512 + prompts: + - "photo of [trigger] laughing" + - "photo of [trigger] smiling" + - "[trigger] close up" + - "dark scene [trigger] frozen" + - "[trigger] nighttime" + - "a painting of [trigger]" + - "a drawing of [trigger]" + - "a cartoon of [trigger]" + - "[trigger] pixar style" + - "[trigger] costume" + neg: "" + seed: 42 + walk_seed: false + guidance_scale: 7 + sample_steps: 20 + network_multiplier: 1.0 + + logging: + log_every: 10 # log every this many steps + use_wandb: false # not supported yet + verbose: false + +# You can put any information you want here, and it will be saved in the model. +# The below is an example, but you can put your grocery list in it if you want. +# It is saved in the model so be aware of that. The software will include this +# plus some other information for you automatically +meta: + # [name] gets replaced with the name above + name: "[name]" +# version: '1.0' +# creator: +# name: Your Name +# email: your@gmail.com +# website: https://your.website diff --git a/ai-toolkit/extensions_built_in/audio_models/__init__.py b/ai-toolkit/extensions_built_in/audio_models/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..b01e2655877273b22e2d5164c0233dcbe3a46ccb --- /dev/null +++ b/ai-toolkit/extensions_built_in/audio_models/__init__.py @@ -0,0 +1,7 @@ +from .ace_step import AceStep15Model, AceStep15XLModel + +AI_TOOLKIT_MODELS = [ + # put a list of models here + AceStep15Model, + AceStep15XLModel, +] diff --git a/ai-toolkit/extensions_built_in/audio_models/ace_step/__init__.py b/ai-toolkit/extensions_built_in/audio_models/ace_step/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..5b24a377057ddcbd573f5d5c0dd245160bfc78c6 --- /dev/null +++ b/ai-toolkit/extensions_built_in/audio_models/ace_step/__init__.py @@ -0,0 +1 @@ +from .ace_step_15_model import AceStep15Model, AceStep15XLModel \ No newline at end of file diff --git a/ai-toolkit/extensions_built_in/audio_models/ace_step/ace_step_15_model.py b/ai-toolkit/extensions_built_in/audio_models/ace_step/ace_step_15_model.py new file mode 100644 index 0000000000000000000000000000000000000000..430f82ba700491d08f46920b41c088b94a11bf7b --- /dev/null +++ b/ai-toolkit/extensions_built_in/audio_models/ace_step/ace_step_15_model.py @@ -0,0 +1,335 @@ +import json +import os +from typing import List, Optional +import huggingface_hub +import torch +from safetensors.torch import load_file, save_file +from extensions_built_in.audio_models.base_audio_model import BaseAudioModel +from toolkit.basic import flush +from toolkit.config_modules import GenerateImageConfig +from toolkit.prompt_utils import PromptEmbeds, concat_prompt_embeds +from toolkit.samplers.custom_flowmatch_sampler import ( + CustomFlowMatchEulerDiscreteScheduler, +) +from toolkit.util.quantize import get_qtype, quantize, quantize_model + +from optimum.quanto import freeze +from .src.model import ( + AceStep15, + OobleckVAE, + TextEncoder, + get_silence_latent, + load_models, +) +from transformers import AutoTokenizer +from .src.pipeline import AceStep15Pipeline + +scheduler_config = { + "num_train_timesteps": 1000, + "shift": 3.0, + "use_dynamic_shifting": False, +} + +def to_number(str_or_number, default): + if isinstance(str_or_number, (int, float)): + return str_or_number + if str_or_number is None: + return default + if str_or_number == "": + return default + try: + return float(str_or_number) + except ValueError: + try: + return int(str_or_number) + except ValueError as e: + raise ValueError(f"Could not convert {str_or_number} to a number") from e + + +def parse_ace_step_caption(text): + """Parse a tagged caption file back into a dict.""" + import re + + def tag(name): + m = re.search(rf"<{name}>(.*?)", text, re.DOTALL) + return m.group(1).strip() if m else "" + + return { + "caption": tag("CAPTION"), + "lyrics": tag("LYRICS"), + "bpm": to_number(tag("BPM"), 120), + "keyscale": tag("KEYSCALE"), + "timesignature": tag("TIMESIGNATURE"), + "duration": to_number(tag("DURATION"), 1.0), + "language": tag("LANGUAGE"), + } + + +class AceStep15Model(BaseAudioModel): + arch = "ace_step_15" + sample_rate = 48000 + + def __init__( + self, + device, + model_config, + dtype="bf16", + custom_pipeline=None, + noise_scheduler=None, + **kwargs, + ): + super().__init__( + device, model_config, dtype, custom_pipeline, noise_scheduler, **kwargs + ) + self.is_flow_matching = True + self.is_transformer = True + # self.target_lora_modules = ['AceStep15'] + self.target_lora_modules = ["DiTModel"] + + # static method to get the noise scheduler + @staticmethod + def get_train_scheduler(): + return CustomFlowMatchEulerDiscreteScheduler(**scheduler_config) + + def load_model(self): + dtype = self.torch_dtype + device = self.device_torch + + model_path = self.model_config.name_or_path + + if not os.path.exists(model_path): + # assume it is a hf repo like org/repo/filename.safetensors + path_parts = model_path.split("/") + if len(path_parts) != 3: + raise ValueError( + f"Model path {model_path} does not exist and is not a valid Hugging Face repo path" + ) + model_path = huggingface_hub.hf_hub_download( + repo_id=f"{path_parts[0]}/{path_parts[1]}", + filename=path_parts[2], + ) + # load the models from the single safetensors file + load_device = device + if self.model_config.low_vram: + load_device = "cpu" + + models = load_models(model_path, device=load_device, dtype=dtype) + + self.model = models["model"] + + if self.model_config.quantize: + self.print_and_status_update("Quantizing Transformer") + # quantize_model(self, self.model.decoder) + quantize(self.model, weights=get_qtype(self.model_config.qtype)) + freeze(self.model) + flush() + + if self.model_config.low_vram: + self.print_and_status_update("Moving transformer to CPU") + self.model.to("cpu") + + + if ( + self.model_config.layer_offloading + and self.model_config.layer_offloading_transformer_percent > 0 + ): + raise NotImplementedError("Layer offloading not yet implemented for AceStep15Model") + + self.text_encoder = models["text_encoder"] + + if self.model_config.quantize_te: + self.print_and_status_update("Quantizing Text Encoder") + quantize(self.text_encoder, weights=get_qtype(self.model_config.qtype_te)) + freeze(self.text_encoder) + flush() + + self.vae = models["vae"] + + # move back to device + self.model.to(device) + self.text_encoder.to(device) + self.vae.to(device) + self.tokenizer = models["tokenizer"] + + self.pipeline = AceStep15Pipeline( + transformer=self.model, + vae=self.vae, + text_encoder=self.text_encoder, + tokenizer=self.tokenizer, + scheduler=self.get_train_scheduler(), + ) + if self.model_config.low_vram: + self.pipeline.do_tiled_decoding = True + + def get_prompt_embeds(self, prompt: str) -> PromptEmbeds: + if isinstance(prompt, str): + prompts = [prompt] + else: + prompts = prompt + + if self.text_encoder.device == torch.device("cpu"): + self.text_encoder.to(self.device_torch) + # we need the encoder from the model + if self.model.encoder.device == torch.device("cpu"): + self.model.encoder.to(self.device_torch) + + # the prompt should be json as a string. Try to parse it. + json_prompts = [] + for p in prompts: + try: + json_prompts.append(parse_ace_step_caption(p)) + except json.JSONDecodeError: + raise ValueError( + f"Prompt {p} is not a valid JSON string. Prompts must be JSON for this model" + ) + + if self.pipeline.text_encoder.device == torch.device("cpu"): + self.pipeline.text_encoder.to(self.device_torch) + + device = self.text_encoder.device + dtype = self.text_encoder.dtype + + batch_pe = None + # TODO not sure this will allow for proper batching + + for json_prompt in json_prompts: + prompt = json_prompt.get("caption", "") + lyrics = json_prompt.get("lyrics", "") + bpm = json_prompt.get("bpm", 120) + key = json_prompt.get("key", "C") + time_sig = json_prompt.get("time_sig", "4/4") + duration = json_prompt.get("duration", 10) + duration = int(duration) if isinstance(duration, (int, float)) else 10 + language = json_prompt.get("language", "en") + + text_embeddings, text_mask, lyric_embeddings, lyric_mask = ( + self.pipeline.get_text_embedings( + prompt, lyrics, bpm, key, time_sig, duration, language + ) + ) + latent_len = int(duration * self.pipeline.LATENT_RATE) + # Silence as source latent [1, 64, T] -> [1, T, 64] for DiT + sil = get_silence_latent(latent_len, device, dtype) # [1, 64, T] + src = sil.transpose(1, 2) # [1, T, 64] + chunk_masks = torch.ones_like(src) + + # Reference audio (silence) + ref = sil[:, :, :750].transpose(1, 2) # [1, 750, 64] + ref_order = torch.zeros(1, device=device, dtype=torch.long) + enc_h, enc_m, _ = self.pipeline.transformer.prepare_condition( + text_embeddings, + text_mask, + lyric_embeddings, + lyric_mask, + ref, + ref_order, + src, + chunk_masks, + ) + + pe = PromptEmbeds(enc_h, attention_mask=enc_m) + if batch_pe is None: + batch_pe = pe + else: + batch_pe = concat_prompt_embeds(batch_pe, pe) + return batch_pe + + def get_transformer_block_names(self) -> Optional[List[str]]: + return ["layers"] + + def get_generation_pipeline(self): + return self.pipeline + + def generate_single_audio( + self, + pipeline, + gen_config: GenerateImageConfig, + conditional_embeds: PromptEmbeds, + unconditional_embeds: PromptEmbeds, + generator: torch.Generator, + extra: dict, + ): + if self.model.device == torch.device("cpu"): + self.model.to(self.device_torch) + # make sure gen config is setup for audio + if gen_config.output_ext not in ['mp3', 'wav']: + gen_config.output_ext = 'mp3' + prompt = gen_config.prompt + json_prompt = parse_ace_step_caption(prompt) + prompt = json_prompt.get("caption", "") + lyrics = json_prompt.get("lyrics", "") + bpm = json_prompt.get("bpm", 120) + key = json_prompt.get("key", "C") + time_sig = json_prompt.get("time_sig", "4/4") + duration = json_prompt.get("duration", 0) + language = json_prompt.get("language", "en") + + output = self.pipeline( + prompt=None, # we are passing in the embeds directly, so no need for a prompt + encoder_embeddings=conditional_embeds.text_embeds.to(self.device_torch, dtype=self.torch_dtype), + encoder_mask=conditional_embeds.attention_mask.to(self.device_torch, dtype=torch.bool), + num_inference_steps=gen_config.num_inference_steps, + duration=duration, + generator=generator, + bpm=bpm, + key=key, + time_sig=time_sig, + language=language, + guidance_scale=gen_config.guidance_scale, + ) + return output + + def get_noise_prediction( + self, + latent_model_input: torch.Tensor, #(1, 300, 64) + timestep: torch.Tensor, # 0 to 1000 scale + text_embeddings: PromptEmbeds, + **kwargs, + ): + if self.model.decoder.device == torch.device("cpu"): + self.model.decoder.to(self.device_torch) + with torch.no_grad(): + model: AceStep15 = self.model + tt = timestep.to(self.device_torch, dtype=torch.long) / 1000 + latent_len = latent_model_input.shape[1] + device = self.device_torch + dtype = self.torch_dtype + attn = torch.ones(1, latent_len, device=device, dtype=dtype) + + # build context from silence latent matching the actual input length + sil = get_silence_latent(latent_len, device, dtype) # [1, 64, T] + src = sil.transpose(1, 2) # [1, T, 64] + chunk_masks = torch.ones_like(src) + context = torch.cat([src, chunk_masks], dim=-1) # [1, T, 128] + + pred = model.decoder( + x=latent_model_input.detach(), + timestep=tt.detach(), + timestep_r=tt.detach(), + attention_mask=attn.detach(), + enc_h=text_embeddings.text_embeds.to(self.device_torch, dtype=self.torch_dtype).detach(), + enc_m=text_embeddings.attention_mask.to(self.device_torch, dtype=torch.bool).detach(), + context=context.detach(), + ) + return pred + + def get_loss_target(self, *args, **kwargs): + noise = kwargs.get("noise") + batch = kwargs.get("batch") + return (noise - batch.latents).detach() + + def encode_audio(self, audio_tensor: torch.Tensor, device=None, dtype=None): + if device is None: + device = self.device_torch + if dtype is None: + dtype = self.torch_dtype + if self.vae.device == torch.device("cpu"): + self.vae.to(device) + output = self.vae.encode(audio_tensor.to(device=device, dtype=dtype)) + # transpose from [B, 64, T] to [B, T, 64] for DiT + output = output.transpose(1, 2).contiguous() + return output + + +class AceStep15XLModel(AceStep15Model): + arch = "ace_step_15_xl" diff --git a/ai-toolkit/extensions_built_in/audio_models/ace_step/src/__init__.py b/ai-toolkit/extensions_built_in/audio_models/ace_step/src/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/ai-toolkit/extensions_built_in/audio_models/ace_step/src/model.py b/ai-toolkit/extensions_built_in/audio_models/ace_step/src/model.py new file mode 100644 index 0000000000000000000000000000000000000000..8bf9ffaaea9729f784a3c6f94b7df8607e5ca920 --- /dev/null +++ b/ai-toolkit/extensions_built_in/audio_models/ace_step/src/model.py @@ -0,0 +1,1570 @@ +#!/usr/bin/env python3 +""" +ACE-Step v1.5 — Standalone single-file inference. + +Generates music from text + lyrics. All model code inlined — no project imports, +no trust_remote_code. Uses ComfyUI-style architecture for AIO checkpoint compat. + +Requirements: + pip install torch torchaudio transformers safetensors + +Usage: + python simple_inference.py --prompt "indie folk, warm female vocal, 100 bpm" \ + --lyrics "[Verse]\\nSunlight through the window pane" --duration 30 +""" + +import argparse +import math +import os +import time + +import torch +import torch.nn.functional as F +import torchaudio +from safetensors.torch import load_file +from torch import nn +from transformers import AutoTokenizer +import torch.utils.checkpoint as ckpt + +# ═══════════════════════════════════════════════════════════════════════════════ +# Constants +# ═══════════════════════════════════════════════════════════════════════════════ + +MODELS_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), "models") +MODEL_PATHS = { + "base": os.path.join(MODELS_DIR, "ace_step_1.5_xl_base_aio.safetensors"), + "turbo": os.path.join(MODELS_DIR, "ace_step_1.5_turbo_aio.safetensors"), +} +SAMPLE_RATE = 48000 +LATENT_RATE = 25 # 48000 / 1920 + +SFT_PROMPT = """# Instruction +{instruction} + +# Caption +{caption} + +# Metas +{metas}<|endoftext|> +""" + +TURBO_TIMESTEPS = { + 1.0: [1.0, 0.875, 0.75, 0.625, 0.5, 0.375, 0.25, 0.125], + 2.0: [1.0, 0.933, 0.857, 0.769, 0.667, 0.545, 0.4, 0.222], + 3.0: [ + 1.0, + 0.9545454545454546, + 0.9, + 0.8333333333333334, + 0.75, + 0.6428571428571429, + 0.5, + 0.3, + ], +} + + +def compute_timesteps(num_steps, shift=3.0): + """Compute flow-matching timestep schedule with shifting.""" + import numpy as np + + sigmas = np.linspace(1.0, 0.0, num_steps + 1)[:-1] # exclude final 0 + sigmas = shift * sigmas / (1 + (shift - 1) * sigmas) + return sigmas.tolist() + + +# ═══════════════════════════════════════════════════════════════════════════════ +# Silence latent (hardcoded, from ComfyUI) +# ═══════════════════════════════════════════════════════════════════════════════ + + +def get_silence_latent(length, device, dtype=torch.bfloat16): + head = torch.tensor( + [ + [ + [ + 0.5707, + 0.0982, + 0.6909, + -0.5658, + 0.6266, + 0.6996, + -0.1365, + -0.1291, + -0.0776, + -0.1171, + -0.2743, + -0.8422, + -0.1168, + 1.5539, + -4.6936, + 0.7436, + -1.1846, + -0.2637, + 0.6933, + -6.7266, + 0.0966, + -0.1187, + -0.3501, + -1.1736, + 0.0587, + -2.0517, + -1.3651, + 0.7508, + -0.2490, + -1.3548, + -0.1290, + -0.7261, + 1.1132, + -0.3249, + 0.2337, + 0.3004, + 0.6605, + -0.0298, + -0.1989, + -0.4041, + 0.2843, + -1.0963, + -0.5519, + 0.2639, + -1.0436, + -0.1183, + 0.0640, + 0.4460, + -1.1001, + -0.6172, + -1.3241, + 1.1379, + 0.5623, + -0.1507, + -0.1963, + -0.4742, + -2.4697, + 0.5302, + 0.5381, + 0.4636, + -0.1782, + -0.0687, + 1.0333, + 0.4202, + ], + [ + 0.3040, + -0.1367, + 0.6200, + 0.0665, + -0.0642, + 0.4655, + -0.1187, + -0.0440, + 0.2941, + -0.2753, + 0.0173, + -0.2421, + -0.0147, + 1.5603, + -2.7025, + 0.7907, + -0.9736, + -0.0682, + 0.1294, + -5.0707, + -0.2167, + 0.3302, + -0.1513, + -0.8100, + -0.3894, + -0.2884, + -0.3149, + 0.8660, + -0.3817, + -1.7061, + 0.5824, + -0.4840, + 0.6938, + 0.1859, + 0.1753, + 0.3081, + 0.0195, + 0.1403, + -0.0754, + -0.2091, + 0.1251, + -0.1578, + -0.4968, + -0.1052, + -0.4554, + -0.0320, + 0.1284, + 0.4974, + -1.1889, + -0.0344, + -0.8313, + 0.2953, + 0.5445, + -0.6249, + -0.1595, + -0.0682, + -3.1412, + 0.0484, + 0.4153, + 0.8260, + -0.1526, + -0.0625, + 0.5366, + 0.8473, + ], + [ + 5.3524e-02, + -1.7534e-01, + 5.4443e-01, + -4.3501e-01, + -2.1317e-03, + 3.7200e-01, + -4.0143e-03, + -1.5516e-01, + -1.2968e-01, + -1.5375e-01, + -7.7107e-02, + -2.0593e-01, + -3.2780e-01, + 1.5142e00, + -2.6101e00, + 5.8698e-01, + -1.2716e00, + -2.4773e-01, + -2.7933e-02, + -5.0799e00, + 1.1601e-01, + 4.0987e-01, + -2.2030e-02, + -6.6495e-01, + -2.0995e-01, + -6.3474e-01, + -1.5893e-01, + 8.2745e-01, + -2.2992e-01, + -1.6816e00, + 5.4440e-01, + -4.9579e-01, + 5.5128e-01, + 3.0477e-01, + 8.3052e-02, + -6.1782e-02, + 5.9036e-03, + 2.9553e-01, + -8.0645e-02, + -1.0060e-01, + 1.9144e-01, + -3.8124e-01, + -7.2949e-01, + 2.4520e-02, + -5.0814e-01, + 2.3977e-01, + 9.2943e-02, + 3.9256e-01, + -1.1993e00, + -3.2752e-01, + -7.2707e-01, + 2.9476e-01, + 4.3542e-01, + -8.8597e-01, + -4.1686e-01, + -8.5390e-02, + -2.9018e00, + 6.4988e-02, + 5.3945e-01, + 9.1988e-01, + 5.8762e-02, + -7.0098e-02, + 6.4772e-01, + 8.9118e-01, + ], + [ + -3.2225e-02, + -1.3195e-01, + 5.6411e-01, + -5.4766e-01, + -5.2170e-03, + 3.1425e-01, + -5.4367e-02, + -1.9419e-01, + -1.3059e-01, + -1.3660e-01, + -9.0984e-02, + -1.9540e-01, + -2.5590e-01, + 1.5440e00, + -2.6349e00, + 6.8273e-01, + -1.2532e00, + -1.9810e-01, + -2.2793e-02, + -5.0506e00, + 1.8818e-01, + 5.0109e-01, + 7.3546e-03, + -6.8771e-01, + -3.0676e-01, + -7.3257e-01, + -1.6687e-01, + 9.2232e-01, + -1.8987e-01, + -1.7267e00, + 5.3355e-01, + -5.3179e-01, + 4.4953e-01, + 2.8820e-01, + 1.3012e-01, + -2.0943e-01, + -1.1348e-01, + 3.3929e-01, + -1.5069e-01, + -1.2919e-01, + 1.8929e-01, + -3.6166e-01, + -8.0756e-01, + 6.6387e-02, + -5.8867e-01, + 1.6978e-01, + 1.0134e-01, + 3.3877e-01, + -1.2133e00, + -3.2492e-01, + -8.1237e-01, + 3.8101e-01, + 4.3765e-01, + -8.0596e-01, + -4.4531e-01, + -4.7513e-02, + -2.9266e00, + 1.1741e-03, + 4.5123e-01, + 9.3075e-01, + 5.3688e-02, + -1.9621e-01, + 6.4530e-01, + 9.3870e-01, + ], + ] + ], + device=device, + ).movedim(-1, 1) + body = ( + torch.tensor( + [ + [ + [ + -1.3672e-01, + -1.5820e-01, + 5.8594e-01, + -5.7422e-01, + 3.0273e-02, + 2.7930e-01, + -2.5940e-03, + -2.0703e-01, + -1.6113e-01, + -1.4746e-01, + -2.7710e-02, + -1.8066e-01, + -2.9688e-01, + 1.6016e00, + -2.6719e00, + 7.7734e-01, + -1.3516e00, + -1.9434e-01, + -7.1289e-02, + -5.0938e00, + 2.4316e-01, + 4.7266e-01, + 4.6387e-02, + -6.6406e-01, + -2.1973e-01, + -6.7578e-01, + -1.5723e-01, + 9.5312e-01, + -2.0020e-01, + -1.7109e00, + 5.8984e-01, + -5.7422e-01, + 5.1562e-01, + 2.8320e-01, + 1.4551e-01, + -1.8750e-01, + -5.9814e-02, + 3.6719e-01, + -1.0059e-01, + -1.5723e-01, + 2.0605e-01, + -4.3359e-01, + -8.2812e-01, + 4.5654e-02, + -6.6016e-01, + 1.4844e-01, + 9.4727e-02, + 3.8477e-01, + -1.2578e00, + -3.3203e-01, + -8.5547e-01, + 4.3359e-01, + 4.2383e-01, + -8.9453e-01, + -5.0391e-01, + -5.6152e-02, + -2.9219e00, + -2.4658e-02, + 5.0391e-01, + 9.8438e-01, + 7.2754e-02, + -2.1582e-01, + 6.3672e-01, + 1.0000e00, + ] + ] + ], + device=device, + ) + .movedim(-1, 1) + .repeat(1, 1, length) + ) + body[:, :, : head.shape[-1]] = head + return body.to(dtype) # [1, 64, T] + + +# ═══════════════════════════════════════════════════════════════════════════════ +# Helpers +# ═══════════════════════════════════════════════════════════════════════════════ + + +class RMSNorm(nn.Module): + def __init__(self, dim, eps=1e-6): + super().__init__() + self.weight = nn.Parameter(torch.ones(dim)) + self.eps = eps + + def forward(self, x): + return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) * self.weight + + +class RotaryEmbedding(nn.Module): + def __init__(self, dim, base=1000000.0): + super().__init__() + inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.float32) / dim)) + self.register_buffer("inv_freq", inv_freq, persistent=False) + self._cos = None + self._sin = None + self._cached_len = 0 + + def _build_cache(self, seq_len, device, dtype): + if ( + seq_len <= self._cached_len + and self._cos is not None + and self._cos.device == device + ): + return + t = torch.arange(seq_len, device=device, dtype=torch.float32) + freqs = torch.outer(t, self.inv_freq.to(device)) + emb = torch.cat((freqs, freqs), dim=-1) + self._cos = emb.cos().to(dtype) + self._sin = emb.sin().to(dtype) + self._cached_len = seq_len + + def forward(self, x, seq_len): + self._build_cache(seq_len, x.device, x.dtype) + return self._cos[:seq_len], self._sin[:seq_len] + + +def rotate_half(x): + x1, x2 = x[..., : x.shape[-1] // 2], x[..., x.shape[-1] // 2 :] + return torch.cat((-x2, x1), dim=-1) + + +def apply_rotary(q, k, cos, sin): + cos, sin = cos.unsqueeze(0).unsqueeze(0), sin.unsqueeze(0).unsqueeze(0) + return (q * cos + rotate_half(q) * sin), (k * cos + rotate_half(k) * sin) + + +class MLP(nn.Module): + def __init__(self, hidden, inter): + super().__init__() + self.gate_proj = nn.Linear(hidden, inter, bias=False) + self.up_proj = nn.Linear(hidden, inter, bias=False) + self.down_proj = nn.Linear(inter, hidden, bias=False) + + def forward(self, x): + return self.down_proj(F.silu(self.gate_proj(x)) * self.up_proj(x)) + + +def pack_sequences(h1, h2, m1, m2): + h = torch.cat([h1, h2], dim=1) + if m1 is not None and m2 is not None: + m = torch.cat([m1, m2], dim=1) + B, L, D = h.shape + idx = m.argsort(dim=1, descending=True, stable=True) + h = torch.gather(h, 1, idx.unsqueeze(-1).expand(B, L, D)) + lengths = m.sum(dim=1) + m = torch.arange(L, device=h.device).unsqueeze(0) < lengths.unsqueeze(1) + else: + m = None + return h, m + + +def timestep_embedding(t, dim, scale=1000, max_period=10000): + t = t * scale + half = dim // 2 + freqs = torch.exp( + -math.log(max_period) + * torch.arange(half, dtype=torch.float32, device=t.device) + / half + ) + args = t[:, None].float() * freqs[None] + return torch.cat([torch.cos(args), torch.sin(args)], dim=-1) + + +# ═══════════════════════════════════════════════════════════════════════════════ +# DiT model components (ComfyUI-style, matches AIO weight keys) +# ═══════════════════════════════════════════════════════════════════════════════ + + +class TimestepEmbed(nn.Module): + def __init__(self, hidden): + super().__init__() + self.linear_1 = nn.Linear(256, hidden) + self.act1 = nn.SiLU() + self.linear_2 = nn.Linear(hidden, hidden) + self.act2 = nn.SiLU() + self.time_proj = nn.Linear(hidden, hidden * 6) + self.scale = 1000 + + def forward(self, t, dtype=None): + emb = timestep_embedding(t, 256, self.scale) + temb = self.act1(self.linear_1(emb.to(dtype=dtype))) + temb = self.linear_2(temb) + proj = self.time_proj(self.act2(temb)).view(-1, 6, temb.shape[-1]) + return temb, proj + + +class Attention(nn.Module): + def __init__( + self, + hidden, + num_heads, + num_kv, + head_dim, + eps=1e-6, + is_cross=False, + sliding_window=None, + ): + super().__init__() + self.num_heads = num_heads + self.num_kv = num_kv + self.head_dim = head_dim + self.is_cross = is_cross + self.sliding_window = sliding_window + self.q_proj = nn.Linear(hidden, num_heads * head_dim, bias=False) + self.k_proj = nn.Linear(hidden, num_kv * head_dim, bias=False) + self.v_proj = nn.Linear(hidden, num_kv * head_dim, bias=False) + self.o_proj = nn.Linear(num_heads * head_dim, hidden, bias=False) + self.q_norm = RMSNorm(head_dim, eps) + self.k_norm = RMSNorm(head_dim, eps) + + def forward(self, x, encoder_hidden_states=None, position_embeddings=None): + B, L, _ = x.shape + q = self.q_norm( + self.q_proj(x).view(B, L, self.num_heads, self.head_dim) + ).transpose(1, 2) + + src = ( + encoder_hidden_states + if (self.is_cross and encoder_hidden_states is not None) + else x + ) + sL = src.shape[1] + k = self.k_norm( + self.k_proj(src).view(B, sL, self.num_kv, self.head_dim) + ).transpose(1, 2) + v = self.v_proj(src).view(B, sL, self.num_kv, self.head_dim).transpose(1, 2) + + if position_embeddings is not None and not ( + self.is_cross and encoder_hidden_states is not None + ): + q, k = apply_rotary(q, k, *position_embeddings) + + n_rep = self.num_heads // self.num_kv + if n_rep > 1: + k = k.repeat_interleave(n_rep, dim=1) + v = v.repeat_interleave(n_rep, dim=1) + + attn_bias = None + if self.sliding_window is not None and not self.is_cross: + idx = torch.arange(L, device=q.device) + in_win = ( + torch.abs(idx.unsqueeze(1) - idx.unsqueeze(0)) <= self.sliding_window + ) + attn_bias = torch.zeros(L, sL, device=q.device, dtype=q.dtype) + attn_bias.masked_fill_(~in_win, torch.finfo(q.dtype).min) + attn_bias = attn_bias.unsqueeze(0).unsqueeze(0) + + out = F.scaled_dot_product_attention(q, k, v, attn_mask=attn_bias) + return self.o_proj(out.transpose(1, 2).reshape(B, L, -1)) + + +class EncoderLayer(nn.Module): + def __init__(self, hidden, heads, kv, head_dim, inter, eps=1e-6): + super().__init__() + self.self_attn = Attention(hidden, heads, kv, head_dim, eps) + self.input_layernorm = RMSNorm(hidden, eps) + self.post_attention_layernorm = RMSNorm(hidden, eps) + self.mlp = MLP(hidden, inter) + + def forward(self, x, position_embeddings): + x = x + self.self_attn( + self.input_layernorm(x), position_embeddings=position_embeddings + ) + x = x + self.mlp(self.post_attention_layernorm(x)) + return x + + +class DiTLayer(nn.Module): + def __init__( + self, hidden, heads, kv, head_dim, inter, eps=1e-6, sliding_window=None + ): + super().__init__() + self.self_attn_norm = RMSNorm(hidden, eps) + self.self_attn = Attention( + hidden, heads, kv, head_dim, eps, sliding_window=sliding_window + ) + self.cross_attn_norm = RMSNorm(hidden, eps) + self.cross_attn = Attention(hidden, heads, kv, head_dim, eps, is_cross=True) + self.mlp_norm = RMSNorm(hidden, eps) + self.mlp = MLP(hidden, inter) + self.scale_shift_table = nn.Parameter(torch.empty(1, 6, hidden)) + + def forward(self, x, temb, enc, position_embeddings): + s_msa, sc_msa, g_msa, s_mlp, sc_mlp, g_mlp = ( + self.scale_shift_table.to(temb) + temb + ).chunk(6, dim=1) + x = ( + x + + self.self_attn( + self.self_attn_norm(x) * (1 + sc_msa) + s_msa, + position_embeddings=position_embeddings, + ) + * g_msa + ) + x = x + self.cross_attn(self.cross_attn_norm(x), encoder_hidden_states=enc) + x = x + self.mlp(self.mlp_norm(x) * (1 + sc_mlp) + s_mlp) * g_mlp + return x + + +# ── Encoders ── + + +class LyricEncoder(nn.Module): + def __init__( + self, text_dim, hidden, n_layers, heads, kv, head_dim, inter, eps=1e-6 + ): + super().__init__() + self.embed_tokens = nn.Linear(text_dim, hidden) + self.norm = RMSNorm(hidden, eps) + self.rotary_emb = RotaryEmbedding(head_dim) + self.layers = nn.ModuleList( + [ + EncoderLayer(hidden, heads, kv, head_dim, inter, eps) + for _ in range(n_layers) + ] + ) + + def forward(self, embeds): + x = self.embed_tokens(embeds) + cos, sin = self.rotary_emb(x, x.shape[1]) + for layer in self.layers: + x = layer(x, (cos, sin)) + return self.norm(x) + + +class TimbreEncoder(nn.Module): + def __init__( + self, timbre_dim, hidden, n_layers, heads, kv, head_dim, inter, eps=1e-6 + ): + super().__init__() + self.embed_tokens = nn.Linear(timbre_dim, hidden) + self.norm = RMSNorm(hidden, eps) + self.rotary_emb = RotaryEmbedding(head_dim) + self.layers = nn.ModuleList( + [ + EncoderLayer(hidden, heads, kv, head_dim, inter, eps) + for _ in range(n_layers) + ] + ) + self.special_token = nn.Parameter(torch.empty(1, 1, hidden)) + + def forward(self, packed, order_mask): + x = self.embed_tokens(packed) + cos, sin = self.rotary_emb(x, x.shape[1]) + for layer in self.layers: + x = layer(x, (cos, sin)) + x = self.norm(x) + cls = x[:, 0, :] + # Unpack to batch + N, D = cls.shape + B = int(order_mask.max().item() + 1) + counts = torch.bincount(order_mask, minlength=B) + mc = counts.max().item() + result = torch.zeros(B, mc, D, device=cls.device, dtype=cls.dtype) + mask = torch.zeros(B, mc, device=cls.device, dtype=torch.long) + for i in range(N): + b = order_mask[i].item() + pos = (order_mask[:i] == b).sum().item() + result[b, pos] = cls[i] + mask[b, pos] = 1 + return result, mask + + +class ConditionEncoder(nn.Module): + def __init__( + self, + text_dim, + timbre_dim, + hidden, + n_lyric, + n_timbre, + heads, + kv, + head_dim, + inter, + eps=1e-6, + ): + super().__init__() + self.text_projector = nn.Linear(text_dim, hidden, bias=False) + self.lyric_encoder = LyricEncoder( + text_dim, hidden, n_lyric, heads, kv, head_dim, inter, eps + ) + self.timbre_encoder = TimbreEncoder( + timbre_dim, hidden, n_timbre, heads, kv, head_dim, inter, eps + ) + + @property + def device(self): + return next(self.parameters()).device + + @property + def dtype(self): + return next(self.parameters()).dtype + + def forward(self, text_h, text_m, lyric_h, lyric_m, refer_packed, refer_order): + text_proj = self.text_projector(text_h) + lyric_enc = self.lyric_encoder(lyric_h) + timbre_enc, timbre_mask = self.timbre_encoder(refer_packed, refer_order) + merged, merged_m = pack_sequences(lyric_enc, timbre_enc, lyric_m, timbre_mask) + final, final_m = pack_sequences(merged, text_proj, merged_m, text_m) + return final, final_m + + +# ── DiT ── + + +class DiTModel(nn.Module): + def __init__( + self, + in_ch, + hidden, + n_layers, + heads, + kv, + head_dim, + inter, + patch, + out_ch, + layer_types=None, + sliding_window=128, + eps=1e-6, + cond_dim=None, + ): + super().__init__() + self.patch_size = patch + self.rotary_emb = RotaryEmbedding(head_dim) + self.proj_in = nn.Sequential( + nn.Identity(), nn.Conv1d(in_ch, hidden, kernel_size=patch, stride=patch) + ) + self.time_embed = TimestepEmbed(hidden) + self.time_embed_r = TimestepEmbed(hidden) + self.condition_embedder = nn.Linear(cond_dim or hidden, hidden) + lt = layer_types or [ + "sliding_attention" if i % 2 == 0 else "full_attention" + for i in range(n_layers) + ] + self.layers = nn.ModuleList( + [ + DiTLayer( + hidden, + heads, + kv, + head_dim, + inter, + eps, + sliding_window=sliding_window + if lt[i] == "sliding_attention" + else None, + ) + for i in range(n_layers) + ] + ) + self.norm_out = RMSNorm(hidden, eps) + self.proj_out = nn.Sequential( + nn.Identity(), + nn.ConvTranspose1d(hidden, out_ch, kernel_size=patch, stride=patch), + ) + self.scale_shift_table = nn.Parameter(torch.empty(1, 2, hidden)) + self.gradient_checkpointing = False + + @property + def device(self): + return next(self.parameters()).device + + @property + def dtype(self): + return next(self.parameters()).dtype + + def forward(self, x, timestep, timestep_r, attention_mask, enc_h, enc_m, context): + temb_t, proj_t = self.time_embed(timestep, dtype=x.dtype) + temb_r, proj_r = self.time_embed_r(timestep - timestep_r, dtype=x.dtype) + temb = temb_t + temb_r + tproj = proj_t + proj_r + + h = torch.cat([context, x], dim=-1) + orig_len = h.shape[1] + if h.shape[1] % self.patch_size != 0: + h = F.pad(h, (0, 0, 0, self.patch_size - h.shape[1] % self.patch_size)) + h = self.proj_in(h.transpose(1, 2)).transpose(1, 2) + enc = self.condition_embedder(enc_h) + cos, sin = self.rotary_emb(h, h.shape[1]) + for layer in self.layers: + if torch.is_grad_enabled() and self.gradient_checkpointing: + h = ckpt.checkpoint( + layer, h, tproj, enc, (cos, sin), use_reentrant=False + ) + else: + h = layer(h, tproj, enc, (cos, sin)) + shift, scale = (self.scale_shift_table.to(temb) + temb.unsqueeze(1)).chunk( + 2, dim=1 + ) + h = self.norm_out(h) * (1 + scale) + shift + h = self.proj_out(h.transpose(1, 2)).transpose(1, 2) + return h[:, :orig_len, :] + + +# ── Top-level model ── + + +class AceStep15(nn.Module): + def __init__( + self, + hidden=2048, + text_dim=1024, + timbre_dim=64, + out_ch=64, + n_dit=24, + n_lyric=8, + n_timbre=4, + heads=16, + kv=8, + head_dim=128, + inter=6144, + patch=2, + in_ch=192, + sliding_window=128, + eps=1e-6, + layer_types=None, + # Encoder can have different size than decoder (XL models) + enc_hidden=None, + enc_heads=None, + enc_kv=None, + enc_inter=None, + ): + super().__init__() + eh = enc_hidden or hidden + eheads = enc_heads or heads + ekv = enc_kv or kv + einter = enc_inter or inter + + self.decoder = DiTModel( + in_ch, + hidden, + n_dit, + heads, + kv, + head_dim, + inter, + patch, + out_ch, + layer_types, + sliding_window, + eps, + cond_dim=eh, + ) + self.encoder = ConditionEncoder( + text_dim, + timbre_dim, + eh, + n_lyric, + n_timbre, + eheads, + ekv, + head_dim, + einter, + eps, + ) + self.null_condition_emb = nn.Parameter(torch.empty(1, 1, eh)) + self._gradient_checkpointing = False + + @property + def device(self): + return next(self.parameters()).device + + @property + def dtype(self): + return next(self.parameters()).dtype + + def enable_gradient_checkpointing(self): + self.gradient_checkpointing = True + + @property + def gradient_checkpointing(self): + return self._gradient_checkpointing + + @gradient_checkpointing.setter + def gradient_checkpointing(self, value): + self._gradient_checkpointing = value + self.decoder.gradient_checkpointing = value + + def prepare_condition( + self, + text_h, + text_m, + lyric_h, + lyric_m, + refer_packed, + refer_order, + src_latents, + chunk_masks, + ): + enc_h, enc_m = self.encoder( + text_h, text_m, lyric_h, lyric_m, refer_packed, refer_order + ) + context = torch.cat([src_latents, chunk_masks.to(src_latents.dtype)], dim=-1) + return enc_h, enc_m, context + + +# ═══════════════════════════════════════════════════════════════════════════════ +# VAE (ComfyUI Oobleck style — uses parametrizations.weight_norm) +# ═══════════════════════════════════════════════════════════════════════════════ + + +def WNConv1d(*args, **kwargs): + return torch.nn.utils.parametrizations.weight_norm(nn.Conv1d(*args, **kwargs)) + + +def WNConvT1d(*args, **kwargs): + return torch.nn.utils.parametrizations.weight_norm( + nn.ConvTranspose1d(*args, **kwargs) + ) + + +class SnakeBeta(nn.Module): + def __init__(self, channels): + super().__init__() + self.alpha = nn.Parameter(torch.zeros(channels)) + self.beta = nn.Parameter(torch.zeros(channels)) + + def forward(self, x): + a = self.alpha.unsqueeze(0).unsqueeze(-1).exp().to(x.device) + b = self.beta.unsqueeze(0).unsqueeze(-1).exp().to(x.device) + return x + (1.0 / (b + 1e-9)) * torch.sin(x * a).pow(2) + + +class ResUnit(nn.Module): + def __init__(self, ch, dilation): + super().__init__() + self.layers = nn.Sequential( + SnakeBeta(ch), + WNConv1d(ch, ch, 7, dilation=dilation, padding=(dilation * 6) // 2), + SnakeBeta(ch), + WNConv1d(ch, ch, 1), + ) + + def forward(self, x): + return x + self.layers(x) + + +class EncBlock(nn.Module): + def __init__(self, in_ch, out_ch, stride): + super().__init__() + self.layers = nn.Sequential( + ResUnit(in_ch, 1), + ResUnit(in_ch, 3), + ResUnit(in_ch, 9), + SnakeBeta(in_ch), + WNConv1d( + in_ch, out_ch, 2 * stride, stride=stride, padding=math.ceil(stride / 2) + ), + ) + + def forward(self, x): + return self.layers(x) + + +class DecBlock(nn.Module): + def __init__(self, in_ch, out_ch, stride): + super().__init__() + self.layers = nn.Sequential( + SnakeBeta(in_ch), + WNConvT1d( + in_ch, out_ch, 2 * stride, stride=stride, padding=math.ceil(stride / 2) + ), + ResUnit(out_ch, 1), + ResUnit(out_ch, 3), + ResUnit(out_ch, 9), + ) + + def forward(self, x): + return self.layers(x) + + +class VAEBottleneck(nn.Module): + def encode(self, x): + mean, scale = x.chunk(2, dim=1) + return mean + + def decode(self, x): + return x + + +class _SeqWrap(nn.Module): + """Wraps Sequential as .layers so state_dict keys match AIO format.""" + + def __init__(self, *modules): + super().__init__() + self.layers = nn.Sequential(*modules) + + def forward(self, x): + return self.layers(x) + + +class OobleckVAE(nn.Module): + def __init__( + self, + in_ch=2, + channels=128, + latent_dim=64, + c_mults=(1, 2, 4, 8, 16), + strides=(2, 4, 4, 6, 10), + ): + super().__init__() + cm = [1] + list(c_mults) + # Encoder + enc = [WNConv1d(in_ch, cm[0] * channels, 7, padding=3)] + for i in range(len(cm) - 1): + enc.append(EncBlock(cm[i] * channels, cm[i + 1] * channels, strides[i])) + enc += [ + SnakeBeta(cm[-1] * channels), + WNConv1d(cm[-1] * channels, latent_dim * 2, 3, padding=1), + ] + self.encoder = _SeqWrap(*enc) + # Decoder + dec = [WNConv1d(latent_dim, cm[-1] * channels, 7, padding=3)] + for i in range(len(cm) - 1, 0, -1): + dec.append(DecBlock(cm[i] * channels, cm[i - 1] * channels, strides[i - 1])) + dec += [ + SnakeBeta(cm[0] * channels), + WNConv1d(cm[0] * channels, in_ch, 7, padding=3, bias=False), + ] + self.decoder = _SeqWrap(*dec) + self.bottleneck = VAEBottleneck() + self.upscale_factor = math.prod(strides) + + def encode(self, x): + return self.bottleneck.encode(self.encoder(x)) + + def decode(self, x): + return self.decoder(self.bottleneck.decode(x)) + + def tiled_decode(self, x, tile_seconds=10.0, overlap_seconds=1.0): + """VRAM-light decode: split the latent into ~tile_seconds tiles with + overlap_seconds of overlap, decode each tile independently, and + linearly crossfade the overlapping audio regions.""" + z = self.bottleneck.decode(x) + tile_frames = max(1, round(tile_seconds * LATENT_RATE)) + overlap_frames = max(1, round(overlap_seconds * LATENT_RATE)) + if overlap_frames >= tile_frames: + raise ValueError("overlap_seconds must be smaller than tile_seconds") + + T = z.shape[-1] + if T <= tile_frames: + return self.decoder(z) + + step = tile_frames - overlap_frames + fade_len = overlap_frames * self.upscale_factor + out_T = T * self.upscale_factor + + out = None + ramp = None + write_pos = 0 + + for i, start in enumerate(range(0, T, step)): + end = min(start + tile_frames, T) + decoded = self.decoder(z[..., start:end]) + + if out is None: + out = decoded.new_zeros(decoded.shape[0], decoded.shape[1], out_T) + ramp = torch.linspace(0, 1, fade_len, device=decoded.device, dtype=decoded.dtype) + + if i == 0: + n = decoded.shape[-1] + out[..., :n] = decoded + write_pos = n + else: + blend_start = write_pos - fade_len + out[..., blend_start:blend_start + fade_len] = ( + out[..., blend_start:blend_start + fade_len] * (1 - ramp) + + decoded[..., :fade_len] * ramp + ) + tail = decoded.shape[-1] - fade_len + out[..., write_pos:write_pos + tail] = decoded[..., fade_len:] + write_pos += tail + + if end == T: + break + + return out[..., :write_pos] + + @property + def device(self): + return next(self.parameters()).device + + @property + def dtype(self): + return next(self.parameters()).dtype + + +# ═══════════════════════════════════════════════════════════════════════════════ +# Text encoder (Qwen3-Embedding, just need embed_tokens + model) +# ═══════════════════════════════════════════════════════════════════════════════ + + +class TextEncoder(nn.Module): + """Wraps Qwen3 weights loaded from AIO. Forward returns last_hidden_state.""" + + def __init__(self, qwen_model): + super().__init__() + self.model = qwen_model # the inner model (layers, norm, embed_tokens) + + def encode_text(self, input_ids): + return self.model(input_ids=input_ids).last_hidden_state + + def encode_lyrics(self, input_ids): + return self.model.embed_tokens(input_ids) + + @property + def device(self): + return next(self.parameters()).device + + @property + def dtype(self): + return next(self.parameters()).dtype + + +# ═══════════════════════════════════════════════════════════════════════════════ +# Loading +# ═══════════════════════════════════════════════════════════════════════════════ + + +def infer_dit_config(dit_sd): + """Infer model config from DiT state dict tensor shapes.""" + # hidden_size from decoder norm + hidden = dit_sd["decoder.scale_shift_table"].shape[2] + # intermediate_size from MLP gate_proj + inter = dit_sd["decoder.layers.0.mlp.gate_proj.weight"].shape[0] + # num_heads from q_proj: q_proj.weight is [num_heads * head_dim, hidden] + q_size = dit_sd["decoder.layers.0.self_attn.q_proj.weight"].shape[0] + # head_dim from q_norm + head_dim = dit_sd["decoder.layers.0.self_attn.q_norm.weight"].shape[0] + heads = q_size // head_dim + # num_kv_heads from k_proj + k_size = dit_sd["decoder.layers.0.self_attn.k_proj.weight"].shape[0] + kv = k_size // head_dim + # num_dit_layers: count unique layer indices + n_dit = ( + max(int(k.split(".")[2]) for k in dit_sd if k.startswith("decoder.layers.")) + 1 + ) + # encoder hidden (may differ from decoder hidden for XL models) + enc_hidden = dit_sd["encoder.text_projector.weight"].shape[0] + # encoder layers + n_lyric = ( + max( + int(k.split(".")[3]) + for k in dit_sd + if k.startswith("encoder.lyric_encoder.layers.") + ) + + 1 + ) + n_timbre = ( + max( + int(k.split(".")[3]) + for k in dit_sd + if k.startswith("encoder.timbre_encoder.layers.") + ) + + 1 + ) + # encoder attention config + enc_heads = ( + dit_sd["encoder.lyric_encoder.layers.0.self_attn.q_proj.weight"].shape[0] + // head_dim + ) + enc_kv = ( + dit_sd["encoder.lyric_encoder.layers.0.self_attn.k_proj.weight"].shape[0] + // head_dim + ) + enc_inter = dit_sd["encoder.lyric_encoder.layers.0.mlp.gate_proj.weight"].shape[0] + config = dict( + hidden=hidden, + inter=inter, + heads=heads, + kv=kv, + head_dim=head_dim, + n_dit=n_dit, + n_lyric=n_lyric, + n_timbre=n_timbre, + enc_hidden=enc_hidden, + enc_heads=enc_heads, + enc_kv=enc_kv, + enc_inter=enc_inter, + ) + print( + f" Detected config: hidden={hidden}, inter={inter}, heads={heads}, kv={kv}, " + f"n_dit={n_dit}, enc_hidden={enc_hidden}" + ) + return config + + +def load_models(checkpoint_path, device="cuda", dtype=torch.bfloat16): + if not os.path.isfile(checkpoint_path): + raise FileNotFoundError(f"Checkpoint not found: {checkpoint_path}") + print(f"Loading from: {checkpoint_path}") + + sd = load_file(checkpoint_path) + + # --- DiT --- + print(" Loading DiT...") + dit_sd = { + k.removeprefix("model.diffusion_model."): v + for k, v in sd.items() + if k.startswith("model.diffusion_model.") + } + cfg = infer_dit_config(dit_sd) + model = AceStep15( + hidden=cfg["hidden"], + inter=cfg["inter"], + heads=cfg["heads"], + kv=cfg["kv"], + head_dim=cfg["head_dim"], + n_dit=cfg["n_dit"], + n_lyric=cfg["n_lyric"], + n_timbre=cfg["n_timbre"], + enc_hidden=cfg["enc_hidden"], + enc_heads=cfg["enc_heads"], + enc_kv=cfg["enc_kv"], + enc_inter=cfg["enc_inter"], + ) + missing, unexpected = model.load_state_dict(dit_sd, strict=False) + # tokenizer/detokenizer keys are expected to be unused (cover mode only) + unexpected = [ + k for k in unexpected if not k.startswith(("tokenizer.", "detokenizer.")) + ] + if missing: + print(f" DiT missing: {len(missing)} (first 3: {missing[:3]})") + if unexpected: + print(f" DiT unexpected: {len(unexpected)} (first 3: {unexpected[:3]})") + model = model.to(device).to(dtype).eval() + + # --- VAE --- + print(" Loading VAE...") + vae_sd = {k.removeprefix("vae."): v for k, v in sd.items() if k.startswith("vae.")} + vae = OobleckVAE() + m, u = vae.load_state_dict(vae_sd, strict=False) + if m: + print(f" VAE missing: {len(m)} (first 3: {m[:3]})") + if u: + print(f" VAE unexpected: {len(u)}") + vae = vae.to(device).to(dtype).eval() + + # --- Text encoder (Qwen3-Embedding from AIO) --- + print(" Loading text encoder...") + te_sd = { + k.removeprefix("text_encoders.qwen3_06b.transformer.model."): v + for k, v in sd.items() + if k.startswith("text_encoders.qwen3_06b.transformer.model.") + } + # Load Qwen3 model structure from transformers, then override weights + from transformers import Qwen3Model, Qwen3Config + + qwen_cfg = Qwen3Config( + vocab_size=151669, + hidden_size=1024, + intermediate_size=3072, + num_hidden_layers=28, + num_attention_heads=16, + num_key_value_heads=8, + head_dim=128, + max_position_embeddings=32768, + rms_norm_eps=1e-6, + ) + qwen = Qwen3Model(qwen_cfg) + m2, u2 = qwen.load_state_dict(te_sd, strict=False) + if m2: + print(f" TE missing: {len(m2)} (first 3: {m2[:3]})") + te = TextEncoder(qwen).to(device).to(dtype).eval() + + # Tokenizer — download from HF + print(" Loading tokenizer...") + tok = AutoTokenizer.from_pretrained( + "Qwen/Qwen3-Embedding-0.6B", trust_remote_code=False + ) + + del sd # free memory + torch.cuda.empty_cache() if torch.cuda.is_available() else None + + print(" Done.\n") + return dict( + model=model, vae=vae, text_encoder=te, tokenizer=tok, device=device, dtype=dtype + ) + + +# ═══════════════════════════════════════════════════════════════════════════════ +# Inference +# ═══════════════════════════════════════════════════════════════════════════════ + + +@torch.inference_mode() +def get_latent(audio_path, models): + """Encode audio file to VAE latent. Returns [1, 64, T] tensor.""" + vae, device, dtype = models["vae"], models["device"], models["dtype"] + wav, sr = torchaudio.load(audio_path) + if sr != SAMPLE_RATE: + wav = torchaudio.functional.resample(wav, sr, SAMPLE_RATE) + if wav.shape[0] == 1: + wav = wav.repeat(2, 1) + elif wav.shape[0] > 2: + wav = wav[:2] + return vae.encode(wav.unsqueeze(0).to(device, dtype)) # [1, 64, T] + + +@torch.inference_mode() +def generate( + models, + prompt, + lyrics="", + duration=30.0, + seed=42, + bpm="N/A", + key="N/A", + time_sig="N/A", + language="en", + timesteps=None, + guidance_scale=1.0, +): + model = models["model"] + vae = models["vae"] + te = models["text_encoder"] + tok = models["tokenizer"] + device = models["device"] + dtype = models["dtype"] + + t_sched = timesteps + latent_len = int(duration * LATENT_RATE) + print( + f"Duration: {duration}s -> {latent_len} latent frames, {len(t_sched)} steps" + + (f", CFG={guidance_scale}" if guidance_scale > 1.0 else "") + ) + + # Silence as source latent [1, 64, T] -> [1, T, 64] for DiT + sil = get_silence_latent(latent_len, device, dtype) # [1, 64, T] + src = sil.transpose(1, 2) # [1, T, 64] + chunk_masks = torch.ones_like(src) + + # Text encoding + metas = f"- bpm: {bpm}\n- timesignature: {time_sig}\n- keyscale: {key}\n- duration: {int(duration)} seconds\n" + caption = SFT_PROMPT.format( + instruction="Fill the audio semantic mask based on the given conditions:", + caption=prompt, + metas=metas, + ) + lyrics_text = f"# Languages\n{language}\n\n# Lyric\n{lyrics}<|endoftext|>" + + cap_tok = tok(caption, truncation=True, max_length=256, return_tensors="pt") + lyr_tok = tok(lyrics_text, truncation=True, max_length=2048, return_tensors="pt") + + text_h = te.encode_text(cap_tok.input_ids.to(device)).to(dtype) + text_m = cap_tok.attention_mask.to(device).bool() + lyric_h = te.encode_lyrics(lyr_tok.input_ids.to(device)).to(dtype) + lyric_m = lyr_tok.attention_mask.to(device).bool() + + # Reference audio (silence) + ref = sil[:, :, :750].transpose(1, 2) # [1, 750, 64] + ref_order = torch.zeros(1, device=device, dtype=torch.long) + + # Prepare conditions (conditional) + print("Preparing conditions...") + enc_h, enc_m, ctx = model.prepare_condition( + text_h, text_m, lyric_h, lyric_m, ref, ref_order, src, chunk_masks + ) + + # Prepare unconditional conditions for CFG + use_cfg = guidance_scale > 1.0 + enc_h_uncond = None + if use_cfg: + enc_h_uncond = model.null_condition_emb.expand_as(enc_h) + + # Noise + gen = torch.Generator(device=device).manual_seed(seed) + noise_ch = ctx.shape[-1] // 2 + xt = torch.randn(1, latent_len, noise_ch, generator=gen, device=device, dtype=dtype) + + # Diffusion + print("Running diffusion...") + t0 = time.time() + t_sched_t = torch.tensor(t_sched, device=device, dtype=dtype) + attn = torch.ones(1, latent_len, device=device, dtype=dtype) + + for i in range(len(t_sched_t)): + tv = t_sched_t[i].item() + tt = torch.full((1,), tv, device=device, dtype=dtype) + + vt_cond = model.decoder(xt, tt, tt, attn, enc_h, enc_m, ctx) + + if use_cfg: + vt_uncond = model.decoder(xt, tt, tt, attn, enc_h_uncond, enc_m, ctx) + vt = vt_uncond + guidance_scale * (vt_cond - vt_uncond) + else: + vt = vt_cond + + if i == len(t_sched_t) - 1: + xt = xt - vt * tv + else: + xt = xt - vt * (tv - t_sched_t[i + 1].item()) + + print(f"Diffusion: {time.time() - t0:.2f}s") + + # VAE decode + print("Decoding audio...") + t0 = time.time() + wav = vae.decode(xt.transpose(1, 2)) # [1, 2, samples] + wav = wav[0, :, : int(duration * SAMPLE_RATE)] + print(f"VAE decode: {time.time() - t0:.2f}s") + return wav.cpu().float() + + +# ═══════════════════════════════════════════════════════════════════════════════ +# CLI +# ═══════════════════════════════════════════════════════════════════════════════ + + +def main(): + p = argparse.ArgumentParser(description="ACE-Step v1.5 standalone inference") + p.add_argument("--prompt", required=True) + p.add_argument("--lyrics", default="") + p.add_argument("--duration", type=float, default=30.0) + p.add_argument("--output", default="output.wav") + p.add_argument("--seed", type=int, default=42) + p.add_argument( + "--model", + default="base", + choices=["base", "turbo"], + help="Model variant (default: base)", + ) + p.add_argument( + "--checkpoint", default=None, help="Override path to AIO .safetensors" + ) + p.add_argument("--device", default=None) + p.add_argument( + "--dtype", default="bfloat16", choices=["bfloat16", "float16", "float32"] + ) + p.add_argument("--bpm", default="N/A") + p.add_argument("--key", default="N/A") + p.add_argument("--time-sig", default="N/A") + p.add_argument("--language", default="en") + p.add_argument( + "--steps", + type=int, + default=None, + help="Diffusion steps (default: 30 for base, 8 for turbo)", + ) + p.add_argument( + "--shift", type=float, default=3.0, help="Timestep shift (default: 3.0)" + ) + p.add_argument( + "--cfg", + type=float, + default=None, + help="CFG guidance scale (default: 3.5 for base, 1.0 for turbo)", + ) + args = p.parse_args() + + device = args.device or ( + "cuda" + if torch.cuda.is_available() + else "mps" + if getattr(torch.backends, "mps", None) and torch.backends.mps.is_available() + else "cpu" + ) + dtype = { + "bfloat16": torch.bfloat16, + "float16": torch.float16, + "float32": torch.float32, + }[args.dtype] + if device == "mps": + dtype = torch.float32 + + lyrics = args.lyrics + if lyrics.startswith("@") and os.path.isfile(lyrics[1:]): + lyrics = open(lyrics[1:]).read() + else: + lyrics = lyrics.replace("\\n", "\n") + + # Model-specific defaults + is_turbo = args.model == "turbo" + ckpt = args.checkpoint or MODEL_PATHS[args.model] + steps = args.steps or (8 if is_turbo else 30) + cfg = args.cfg if args.cfg is not None else (1.0 if is_turbo else 3.5) + + # Timestep schedule + if is_turbo and steps == 8: + ts = TURBO_TIMESTEPS.get(args.shift, TURBO_TIMESTEPS[3.0]) + else: + ts = compute_timesteps(steps, args.shift) + + print( + f"ACE-Step v1.5 ({args.model}) | {device} ({dtype}) | seed={args.seed} | {args.duration}s | {steps} steps | CFG={cfg}" + ) + models = load_models(ckpt, device, dtype) + wav = generate( + models, + args.prompt, + lyrics, + args.duration, + args.seed, + args.bpm, + args.key, + args.time_sig, + args.language, + ts, + cfg, + ) + + os.makedirs(os.path.dirname(args.output) or ".", exist_ok=True) + torchaudio.save(args.output, wav, SAMPLE_RATE) + print(f"Saved: {args.output} ({wav.shape[1] / SAMPLE_RATE:.1f}s stereo)") + + +if __name__ == "__main__": + main() diff --git a/ai-toolkit/extensions_built_in/audio_models/ace_step/src/pipeline.py b/ai-toolkit/extensions_built_in/audio_models/ace_step/src/pipeline.py new file mode 100644 index 0000000000000000000000000000000000000000..57edff6404514985d2ab8c525de29b6ee9e48abc --- /dev/null +++ b/ai-toolkit/extensions_built_in/audio_models/ace_step/src/pipeline.py @@ -0,0 +1,167 @@ +from typing import List, Optional + +import torch +import time +import os +from .model import ( + SAMPLE_RATE, + AceStep15, + OobleckVAE, + TextEncoder, + get_silence_latent, + compute_timesteps, +) +from diffusers.utils.torch_utils import randn_tensor +from transformers import AutoTokenizer + +SFT_PROMPT = """# Instruction +{instruction} + +# Caption +{caption} + +# Metas +{metas}<|endoftext|> +""" + + +class AceStep15Pipeline: + SAMPLE_RATE = 48000 + LATENT_RATE = 25 # 48000 / 1920 + SFT_PROMPT = SFT_PROMPT + + def __init__(self, transformer, vae, text_encoder, tokenizer, scheduler): + self.transformer: AceStep15 = transformer + self.vae: OobleckVAE = vae + self.text_encoder: TextEncoder = text_encoder + self.tokenizer: AutoTokenizer = tokenizer + self.scheduler = scheduler + self.do_tiled_decoding = False + + def to(self, *args, **kwargs): + self.transformer.to(*args, **kwargs) + self.vae.to(*args, **kwargs) + self.text_encoder.to(*args, **kwargs) + + def get_text_embedings( + self, prompt, lyrics, bpm, key, time_sig, duration, language + ): + metas = f"- bpm: {bpm}\n- timesignature: {time_sig}\n- keyscale: {key}\n- duration: {int(duration)} seconds\n" + caption = self.SFT_PROMPT.format( + instruction="Fill the audio semantic mask based on the given conditions:", + caption=prompt, + metas=metas, + ) + lyrics_text = f"# Languages\n{language}\n\n# Lyric\n{lyrics}<|endoftext|>" + + cap_tok = self.tokenizer( + caption, truncation=True, max_length=256, return_tensors="pt" + ) + lyr_tok = self.tokenizer( + lyrics_text, truncation=True, max_length=2048, return_tensors="pt" + ) + + text_embeddings = self.text_encoder.encode_text( + cap_tok.input_ids.to(self.text_encoder.device) + ).to(self.transformer.dtype) + text_mask = cap_tok.attention_mask.to(self.text_encoder.device).bool() + lyric_embeddings = self.text_encoder.encode_lyrics( + lyr_tok.input_ids.to(self.text_encoder.device) + ).to(self.transformer.dtype) + lyric_mask = lyr_tok.attention_mask.to(self.text_encoder.device).bool() + + return text_embeddings, text_mask, lyric_embeddings, lyric_mask + + def __call__( + self, + prompt="", + lyrics="", + encoder_embeddings: Optional[List[torch.Tensor]] = None, + encoder_mask: Optional[List[torch.Tensor]] = None, + # uses a null conditional for unconditional if not provided, which is what we want for CFG + num_inference_steps=50, + duration=30.0, + generator: torch.Generator = None, + bpm="N/A", + key="N/A", + time_sig="N/A", + language="en", + guidance_scale=1.0, + ): + t_sched = compute_timesteps(num_inference_steps, 3.0) + latent_len = int(duration * self.LATENT_RATE) + device = self.transformer.device + dtype = self.transformer.dtype + + # Text encoding + if encoder_embeddings is not None and encoder_mask is not None: + enc_h = encoder_embeddings + enc_m = encoder_mask + sil = get_silence_latent(latent_len, device, dtype) # [1, 64, T] + src = sil.transpose(1, 2) # [1, T, 64] + chunk_masks = torch.ones_like(src) + ctx = torch.cat([src, chunk_masks.to(src.dtype)], dim=-1) + else: + text_h, text_m, lyric_h, lyric_m = self.get_text_embedings( + prompt, lyrics, bpm, key, time_sig, duration, language + ) + + # Silence as source latent [1, 64, T] -> [1, T, 64] for DiT + sil = get_silence_latent(latent_len, device, dtype) # [1, 64, T] + src = sil.transpose(1, 2) # [1, T, 64] + chunk_masks = torch.ones_like(src) + + # Reference audio (silence) + ref = sil[:, :, :750].transpose(1, 2) # [1, 750, 64] + ref_order = torch.zeros(1, device=device, dtype=torch.long) + + # Prepare conditions (conditional) + enc_h, enc_m, ctx = self.transformer.prepare_condition( + text_h, text_m, lyric_h, lyric_m, ref, ref_order, src, chunk_masks + ) + + # Prepare unconditional conditions for CFG + use_cfg = guidance_scale > 1.0 + enc_h_uncond = None + if use_cfg: + enc_h_uncond = self.transformer.null_condition_emb.expand_as(enc_h) + + # Noise + if generator is None: + generator = torch.Generator(device=device) + noise_ch = ctx.shape[-1] // 2 + xt = randn_tensor( + (1, latent_len, noise_ch), generator=generator, device=device, dtype=dtype + ) + # xt = torch.randn(1, latent_len, noise_ch, generator=generator, device=device, dtype=dtype) + + # Diffusion + t_sched_t = torch.tensor(t_sched, device=device, dtype=dtype) + attn = torch.ones(1, latent_len, device=device, dtype=dtype) + + for i in range(len(t_sched_t)): + tv = t_sched_t[i].item() + tt = torch.full((1,), tv, device=device, dtype=dtype) + + vt_cond = self.transformer.decoder(xt, tt, tt, attn, enc_h, enc_m, ctx) + + if use_cfg: + vt_uncond = self.transformer.decoder( + xt, tt, tt, attn, enc_h_uncond, enc_m, ctx + ) + vt = vt_uncond + guidance_scale * (vt_cond - vt_uncond) + else: + vt = vt_cond + + if i == len(t_sched_t) - 1: + xt = xt - vt * tv + else: + xt = xt - vt * (tv - t_sched_t[i + 1].item()) + + # VAE decode + if self.do_tiled_decoding: + wav = self.vae.tiled_decode(xt.transpose(1, 2)) # [1, 2, samples] + else: + wav = self.vae.decode(xt.transpose(1, 2)) # [1, 2, samples] + wav = wav[0, :, : int(duration * SAMPLE_RATE)] + return wav diff --git a/ai-toolkit/extensions_built_in/audio_models/base_audio_model.py b/ai-toolkit/extensions_built_in/audio_models/base_audio_model.py new file mode 100644 index 0000000000000000000000000000000000000000..6860a1aaf4466414da60ac1f4904bfc27f07013b --- /dev/null +++ b/ai-toolkit/extensions_built_in/audio_models/base_audio_model.py @@ -0,0 +1,99 @@ +import json + +import torch + +from toolkit.config_modules import GenerateImageConfig, ModelConfig +from toolkit.models.base_model import BaseModel +from toolkit.prompt_utils import PromptEmbeds + + +class BaseAudioModel(BaseModel): + sample_rate = 48000 + + def __init__( + self, + device, + model_config: ModelConfig, + dtype="bf16", + custom_pipeline=None, + noise_scheduler=None, + **kwargs, + ): + super().__init__( + device, model_config, dtype, custom_pipeline, noise_scheduler, **kwargs + ) + self.is_audio_model = True + + def generate_single_image( + self, + pipeline, + gen_config: GenerateImageConfig, + conditional_embeds: PromptEmbeds, + unconditional_embeds: PromptEmbeds, + generator: torch.Generator, + extra: dict, + ): + # This is called on the base model. We override it to make it make more sense for audio models. + return self.generate_single_audio( + pipeline, + gen_config, + conditional_embeds, + unconditional_embeds, + generator, + extra, + ) + + def generate_single_audio( + self, + pipeline, + gen_config: GenerateImageConfig, + conditional_embeds: PromptEmbeds, + unconditional_embeds: PromptEmbeds, + generator: torch.Generator, + extra: dict, + ): + # This is called on the base model. We override it to make it make more sense for audio models. + raise NotImplementedError( + "generate_single_audio is not implemented for this model" + ) + + def get_model_has_grad(self): + return False + + def get_te_has_grad(self): + return False + + def save_model(self, output_path, meta, save_dtype): + # we need to save the model, vae, text encoder, and tokenizer together since they are all trained together and depend on each other + raise NotImplementedError( + "save_model is not implemented for this model. Use the pipeline directly instead." + ) + + def convert_lora_weights_before_save(self, state_dict): + # currently starte with transformer. but needs to start with diffusion_model. for comfyui + new_sd = {} + for key, value in state_dict.items(): + new_key = key.replace("transformer.", "diffusion_model.") + new_sd[new_key] = value + return new_sd + + def convert_lora_weights_before_load(self, state_dict): + # saved as diffusion_model. but needs to be transformer. for ai-toolkit + new_sd = {} + for key, value in state_dict.items(): + new_key = key.replace("diffusion_model.", "transformer.") + new_sd[new_key] = value + return new_sd + + def encode_images(self, image_list: torch.Tensor, device=None, dtype=None): + # make it more obvious for audio models + return self.encode_audio(image_list, device=device, dtype=dtype) + + def encode_audio(self, audio_tensor: torch.Tensor, device=None, dtype=None): + if device is None: + device = self.device_torch + if dtype is None: + dtype = self.torch_dtype + if self.vae.device == torch.device("cpu"): + self.vae.to(device) + return self.vae.encode(audio_tensor.to(device=device, dtype=dtype)) diff --git a/ai-toolkit/extensions_built_in/captioner/AceStepCaptioner.py b/ai-toolkit/extensions_built_in/captioner/AceStepCaptioner.py new file mode 100644 index 0000000000000000000000000000000000000000..ce89a2f9cf0c1b509a5dd28305f8f94230506f24 --- /dev/null +++ b/ai-toolkit/extensions_built_in/captioner/AceStepCaptioner.py @@ -0,0 +1,261 @@ +from typing import Optional + +import librosa +import numpy as np +import torch +import torchaudio +from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor +from collections import OrderedDict + +from optimum.quanto import freeze +from toolkit.basic import flush +from toolkit.util.quantize import quantize, get_qtype + +from .BaseCaptioner import BaseCaptioner, CaptionConfig +import transformers +import logging +import warnings + +# transformers.logging.set_verbosity_error() +warnings.filterwarnings("ignore") +logging.disable(logging.WARNING) + +TARGET_SAMPLE_RATE = 16000 +CAPTIONER_ID = "ACE-Step/acestep-captioner" +TRANSCRIBER_ID = "ACE-Step/acestep-transcriber" + +# Key profiles for Krumhansl-Schmuckler key detection +MAJOR_PROFILE = np.array( + [6.35, 2.23, 3.48, 2.33, 4.38, 4.09, 2.52, 5.19, 2.39, 3.66, 2.29, 2.88] +) +MINOR_PROFILE = np.array( + [6.33, 2.68, 3.52, 5.38, 2.60, 3.53, 2.54, 4.75, 3.98, 2.69, 3.34, 3.17] +) +KEY_NAMES = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"] + + +# ═══════════════════════════════════════════════════════════════════════════════ +# Audio analysis (BPM, key, time signature) via librosa +# ═══════════════════════════════════════════════════════════════════════════════ + + +def analyze_audio(audio_path): + """Extract BPM, key, and time signature from audio using librosa.""" + y, sr = librosa.load(audio_path, sr=22050, mono=True) + duration = librosa.get_duration(y=y, sr=sr) + + # BPM + tempo, _ = librosa.beat.beat_track(y=y, sr=sr) + if hasattr(tempo, "__len__"): + tempo = tempo[0] + bpm = int(round(float(tempo))) + + # Key detection via chroma correlation with key profiles + chroma = librosa.feature.chroma_cqt(y=y, sr=sr) + chroma_avg = chroma.mean(axis=1) + major_corrs = np.array( + [np.corrcoef(np.roll(MAJOR_PROFILE, i), chroma_avg)[0, 1] for i in range(12)] + ) + minor_corrs = np.array( + [np.corrcoef(np.roll(MINOR_PROFILE, i), chroma_avg)[0, 1] for i in range(12)] + ) + + best_major_idx = major_corrs.argmax() + best_minor_idx = minor_corrs.argmax() + if major_corrs[best_major_idx] >= minor_corrs[best_minor_idx]: + keyscale = f"{KEY_NAMES[best_major_idx]} major" + else: + keyscale = f"{KEY_NAMES[best_minor_idx]} minor" + + # Time signature estimation from beat strength pattern + onset_env = librosa.onset.onset_strength(y=y, sr=sr) + tempo_est, beats = librosa.beat.beat_track(onset_envelope=onset_env, sr=sr) + if len(beats) >= 8: + beat_strengths = onset_env[beats] + # Check 3/4 vs 4/4 by looking at periodicity of strong beats + acf = np.correlate( + beat_strengths - beat_strengths.mean(), + beat_strengths - beat_strengths.mean(), + mode="full", + ) + acf = acf[len(acf) // 2 :] + if len(acf) > 6: + # Look at autocorrelation peaks at lag 3 vs lag 4 + score_3 = acf[3] if len(acf) > 3 else 0 + score_4 = acf[4] if len(acf) > 4 else 0 + timesig = "3" if score_3 > score_4 * 1.2 else "4" + else: + timesig = "4" + else: + timesig = "4" + + return { + "bpm": bpm, + "keyscale": keyscale, + "timesignature": timesig, + "duration": int(round(duration)), + } + + +class AceStepCaptionConfig(CaptionConfig): + def __init__(self, **kwargs): + super().__init__(**kwargs) + self.fixed_caption: Optional[str] = kwargs.get("fixed_caption", None) + + +class AceStepCaptioner(BaseCaptioner): + caption_config_class = AceStepCaptionConfig + caption_config: AceStepCaptionConfig + + def __init__(self, process_id: int, job, config: OrderedDict, **kwargs): + super(AceStepCaptioner, self).__init__(process_id, job, config, **kwargs) + + def load_model(self): + self.print_and_status_update("Loading transcriber model") + self.model = Qwen2_5OmniForConditionalGeneration.from_pretrained( + self.caption_config.model_name_or_path, + dtype=self.torch_dtype, + device_map="cpu", + ) + self.model.to(self.device_torch) + self.model.disable_talker() + if self.caption_config.quantize: + self.print_and_status_update("Quantizing transcriber model") + quantize(self.model, weights=get_qtype(self.caption_config.qtype)) + freeze(self.model) + flush() + self.processor = Qwen2_5OmniProcessor.from_pretrained( + self.caption_config.model_name_or_path + ) + if self.caption_config.low_vram: + self.model.to("cpu") + + self.model2 = None + self.processor2 = None + + if self.caption_config.fixed_caption is not None: + # load captioner model + self.print_and_status_update("Loading captioner model") + self.model2 = Qwen2_5OmniForConditionalGeneration.from_pretrained( + self.caption_config.model_name_or_path2, + dtype=self.torch_dtype, + device_map="cpu", + ) + self.model2.to(self.device_torch) + self.model2.disable_talker() + if self.caption_config.quantize: + self.print_and_status_update("Quantizing captioner model") + quantize(self.model2, weights=get_qtype(self.caption_config.qtype)) + freeze(self.model2) + flush() + self.processor2 = Qwen2_5OmniProcessor.from_pretrained( + self.caption_config.model_name_or_path2, + ) + + if self.caption_config.low_vram: + self.model2.to("cpu") + flush() + + def run_qwen_audio(self, model, processor, audio_data, sr, prompt_text): + """Run a Qwen2.5-Omni model on audio with a text prompt.""" + conversation = [ + { + "role": "user", + "content": [ + {"type": "audio", "audio": "<|audio_bos|><|AUDIO|><|audio_eos|>"}, + {"type": "text", "text": prompt_text}, + ], + } + ] + text = processor.apply_chat_template( + conversation, add_generation_prompt=True, tokenize=False + ) + inputs = processor( + text=text, + audio=[audio_data], + images=None, + videos=None, + return_tensors="pt", + padding=True, + sampling_rate=sr, + ) + inputs = inputs.to(model.device).to(model.dtype) + text_ids = model.generate(**inputs, return_audio=False) + output = processor.batch_decode( + text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False + ) + result = output[0] + marker = "assistant\n" + if marker in result: + result = result[result.rfind(marker) + len(marker) :] + return result.strip() + + def get_audio_lyrics(self, audio_data: torch.Tensor) -> str: + if self.caption_config.low_vram and self.model2.device != torch.device("cpu"): + # move captioner to cpu + self.model2.to("cpu") + # move lyric model if needed + if self.model.device == torch.device("cpu"): + self.model.to(self.device_torch) + + prompt_text = "*Task* Transcribe this audio in detail" + return self.run_qwen_audio( + self.model, self.processor, audio_data, TARGET_SAMPLE_RATE, prompt_text + ) + + def get_audio_caption(self, audio_data: torch.Tensor) -> str: + if self.caption_config.low_vram and self.model.device != torch.device("cpu"): + # move lyricmodel to cpu + self.model.to("cpu") + # move captioner model if needed + if self.model2.device == torch.device("cpu"): + self.model2.to(self.device_torch) + prompt_text = "*Task* Describe this music in detail. Include genre, mood, instrumentation, tempo feel, and vocal style if present." + return self.run_qwen_audio( + self.model2, self.processor2, audio_data, TARGET_SAMPLE_RATE, prompt_text + ) + + def get_caption_for_file(self, file_path: str) -> str: + try: + # analyze audio with librosa + analysis = analyze_audio(file_path) + + # load audio with torchaudio for transcription + waveform, sr = torchaudio.load(file_path) + waveform = waveform.to(self.device_torch) + if waveform.shape[0] > 1: + waveform = waveform.mean(dim=0, keepdim=True) + if sr != TARGET_SAMPLE_RATE: + waveform = torchaudio.functional.resample( + waveform, sr, TARGET_SAMPLE_RATE + ) + audio_data = waveform.squeeze(0).cpu().numpy() + + # get the lyrics from the audio + lyrics = self.get_audio_lyrics(audio_data) + + language = "en" + + if "# Languages" in lyrics and "# Lyrics" in lyrics: + language = lyrics.split("# Languages")[1].split("# Lyrics")[0] + # remove newlines and extra spaces from language + language = language.replace("\n", "").strip() + lyrics = lyrics.split("# Lyrics")[1].strip() + + # get the caption from the audio + if self.caption_config.fixed_caption is not None: + caption = self.caption_config.fixed_caption + else: + caption = self.get_audio_caption(audio_data) + + output = f"
You can optionally add a custom caption for each image (or use an AI model for this). [trigger] will represent your concept sentence/trigger word.
+""", elem_classes="group_padding") + do_captioning = gr.Button("Add AI captions with Florence-2") + output_components = [captioning_area] + caption_list = [] + for i in range(1, MAX_IMAGES + 1): + locals()[f"captioning_row_{i}"] = gr.Row(visible=False) + with locals()[f"captioning_row_{i}"]: + locals()[f"image_{i}"] = gr.Image( + type="filepath", + width=111, + height=111, + min_width=111, + interactive=False, + scale=2, + show_label=False, + show_share_button=False, + show_download_button=False, + ) + locals()[f"caption_{i}"] = gr.Textbox( + label=f"Caption {i}", scale=15, interactive=True + ) + + output_components.append(locals()[f"captioning_row_{i}"]) + output_components.append(locals()[f"image_{i}"]) + output_components.append(locals()[f"caption_{i}"]) + caption_list.append(locals()[f"caption_{i}"]) + + with gr.Accordion("Advanced options", open=False): + steps = gr.Number(label="Steps", value=1000, minimum=1, maximum=10000, step=1) + lr = gr.Number(label="Learning Rate", value=4e-4, minimum=1e-6, maximum=1e-3, step=1e-6) + rank = gr.Number(label="LoRA Rank", value=16, minimum=4, maximum=128, step=4) + model_to_train = gr.Radio(["dev", "schnell"], value="dev", label="Model to train") + low_vram = gr.Checkbox(label="Low VRAM", value=True) + with gr.Accordion("Even more advanced options", open=False): + use_more_advanced_options = gr.Checkbox(label="Use more advanced options", value=False) + more_advanced_options = gr.Code(config_yaml, language="yaml") + + with gr.Accordion("Sample prompts (optional)", visible=False) as sample: + gr.Markdown( + "Include sample prompts to test out your trained model. Don't forget to include your trigger word/sentence (optional)" + ) + sample_1 = gr.Textbox(label="Test prompt 1") + sample_2 = gr.Textbox(label="Test prompt 2") + sample_3 = gr.Textbox(label="Test prompt 3") + + output_components.append(sample) + output_components.append(sample_1) + output_components.append(sample_2) + output_components.append(sample_3) + start = gr.Button("Start training", visible=False) + output_components.append(start) + progress_area = gr.Markdown("") + + dataset_folder = gr.State() + + images.upload( + load_captioning, + inputs=[images, concept_sentence], + outputs=output_components + ) + + images.delete( + load_captioning, + inputs=[images, concept_sentence], + outputs=output_components + ) + + images.clear( + hide_captioning, + outputs=[captioning_area, sample, start] + ) + + start.click(fn=create_dataset, inputs=[images] + caption_list, outputs=dataset_folder).then( + fn=start_training, + inputs=[ + lora_name, + concept_sentence, + steps, + lr, + rank, + model_to_train, + low_vram, + dataset_folder, + sample_1, + sample_2, + sample_3, + use_more_advanced_options, + more_advanced_options + ], + outputs=progress_area, + ) + + do_captioning.click(fn=run_captioning, inputs=[images, concept_sentence] + caption_list, outputs=caption_list) + +if __name__ == "__main__": + demo.launch(share=True, show_error=True) \ No newline at end of file diff --git a/ai-toolkit/info.py b/ai-toolkit/info.py new file mode 100644 index 0000000000000000000000000000000000000000..2eb2a82ef027b50275bc70dbe4cfb86f644d65e7 --- /dev/null +++ b/ai-toolkit/info.py @@ -0,0 +1,9 @@ +from collections import OrderedDict +from version import VERSION + +v = OrderedDict() +v["name"] = "ai-toolkit" +v["repo"] = "https://github.com/ostris/ai-toolkit" +v["version"] = VERSION + +software_meta = v diff --git a/ai-toolkit/jobs/BaseJob.py b/ai-toolkit/jobs/BaseJob.py new file mode 100644 index 0000000000000000000000000000000000000000..5b339ebe6d942f73f55e14f3de265e7e1db833b7 --- /dev/null +++ b/ai-toolkit/jobs/BaseJob.py @@ -0,0 +1,71 @@ +import importlib +from collections import OrderedDict +from typing import List + +from jobs.process import BaseProcess + + +class BaseJob: + + def __init__(self, config: OrderedDict): + if not config: + raise ValueError('config is required') + self.process: List[BaseProcess] + + self.config = config['config'] + self.raw_config = config + self.job = config['job'] + self.name = self.get_conf('name', required=True) + if 'meta' in config: + self.meta = config['meta'] + else: + self.meta = OrderedDict() + + def get_conf(self, key, default=None, required=False): + if key in self.config: + return self.config[key] + elif required: + raise ValueError(f'config file error. Missing "config.{key}" key') + else: + return default + + def run(self): + print("") + print(f"#############################################") + print(f"# Running job: {self.name}") + print(f"#############################################") + print("") + # implement in child class + # be sure to call super().run() first + pass + + def load_processes(self, process_dict: dict): + # only call if you have processes in this job type + if 'process' not in self.config: + raise ValueError('config file is invalid. Missing "config.process" key') + if len(self.config['process']) == 0: + raise ValueError('config file is invalid. "config.process" must be a list of processes') + + module = importlib.import_module('jobs.process') + + # add the processes + self.process = [] + for i, process in enumerate(self.config['process']): + if 'type' not in process: + raise ValueError(f'config file is invalid. Missing "config.process[{i}].type" key') + + # check if dict key is process type + if process['type'] in process_dict: + if isinstance(process_dict[process['type']], str): + ProcessClass = getattr(module, process_dict[process['type']]) + else: + # it is the class + ProcessClass = process_dict[process['type']] + self.process.append(ProcessClass(i, self, process)) + else: + raise ValueError(f'config file is invalid. Unknown process type: {process["type"]}') + + def cleanup(self): + # if you implement this in child clas, + # be sure to call super().cleanup() LAST + del self diff --git a/ai-toolkit/jobs/ExtensionJob.py b/ai-toolkit/jobs/ExtensionJob.py new file mode 100644 index 0000000000000000000000000000000000000000..def4f8530a8a92c65369cd63a3e69c16bf0bb7de --- /dev/null +++ b/ai-toolkit/jobs/ExtensionJob.py @@ -0,0 +1,22 @@ +import os +from collections import OrderedDict +from jobs import BaseJob +from toolkit.extension import get_all_extensions_process_dict +from toolkit.paths import CONFIG_ROOT + +class ExtensionJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.device = self.get_conf('device', 'cpu') + self.process_dict = get_all_extensions_process_dict() + self.load_processes(self.process_dict) + + def run(self): + super().run() + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/ai-toolkit/jobs/ExtractJob.py b/ai-toolkit/jobs/ExtractJob.py new file mode 100644 index 0000000000000000000000000000000000000000..d710d4128db5304569357ee05d2fb31fa15c6e39 --- /dev/null +++ b/ai-toolkit/jobs/ExtractJob.py @@ -0,0 +1,58 @@ +from toolkit.kohya_model_util import load_models_from_stable_diffusion_checkpoint +from collections import OrderedDict +from jobs import BaseJob +from toolkit.train_tools import get_torch_dtype + +process_dict = { + 'locon': 'ExtractLoconProcess', + 'lora': 'ExtractLoraProcess', +} + + +class ExtractJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.base_model_path = self.get_conf('base_model', required=True) + self.model_base = None + self.model_base_text_encoder = None + self.model_base_vae = None + self.model_base_unet = None + self.extract_model_path = self.get_conf('extract_model', required=True) + self.model_extract = None + self.model_extract_text_encoder = None + self.model_extract_vae = None + self.model_extract_unet = None + self.extract_unet = self.get_conf('extract_unet', True) + self.extract_text_encoder = self.get_conf('extract_text_encoder', True) + self.dtype = self.get_conf('dtype', 'fp16') + self.torch_dtype = get_torch_dtype(self.dtype) + self.output_folder = self.get_conf('output_folder', required=True) + self.is_v2 = self.get_conf('is_v2', False) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + # load models + print(f"Loading models for extraction") + print(f" - Loading base model: {self.base_model_path}") + # (text_model, vae, unet) + self.model_base = load_models_from_stable_diffusion_checkpoint(self.is_v2, self.base_model_path) + self.model_base_text_encoder = self.model_base[0] + self.model_base_vae = self.model_base[1] + self.model_base_unet = self.model_base[2] + + print(f" - Loading extract model: {self.extract_model_path}") + self.model_extract = load_models_from_stable_diffusion_checkpoint(self.is_v2, self.extract_model_path) + self.model_extract_text_encoder = self.model_extract[0] + self.model_extract_vae = self.model_extract[1] + self.model_extract_unet = self.model_extract[2] + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/ai-toolkit/jobs/GenerateJob.py b/ai-toolkit/jobs/GenerateJob.py new file mode 100644 index 0000000000000000000000000000000000000000..bd57a6ac7a1a97d9e68e86131b9e61ac9922e6d0 --- /dev/null +++ b/ai-toolkit/jobs/GenerateJob.py @@ -0,0 +1,24 @@ +from jobs import BaseJob +from collections import OrderedDict + +process_dict = { + 'to_folder': 'GenerateProcess', +} + + +class GenerateJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/ai-toolkit/jobs/MergeJob.py b/ai-toolkit/jobs/MergeJob.py new file mode 100644 index 0000000000000000000000000000000000000000..b9e3b87b9ff589438d06c56019446f06efb76cda --- /dev/null +++ b/ai-toolkit/jobs/MergeJob.py @@ -0,0 +1,29 @@ +from toolkit.kohya_model_util import load_models_from_stable_diffusion_checkpoint +from collections import OrderedDict +from jobs import BaseJob +from toolkit.train_tools import get_torch_dtype + +process_dict = { +} + + +class MergeJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.dtype = self.get_conf('dtype', 'fp16') + self.torch_dtype = get_torch_dtype(self.dtype) + self.is_v2 = self.get_conf('is_v2', False) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/ai-toolkit/jobs/ModJob.py b/ai-toolkit/jobs/ModJob.py new file mode 100644 index 0000000000000000000000000000000000000000..e37990de95a0d2ad78a94f9cdfd6dfbda0cdc529 --- /dev/null +++ b/ai-toolkit/jobs/ModJob.py @@ -0,0 +1,28 @@ +import os +from collections import OrderedDict +from jobs import BaseJob +from toolkit.metadata import get_meta_for_safetensors +from toolkit.train_tools import get_torch_dtype + +process_dict = { + 'rescale_lora': 'ModRescaleLoraProcess', +} + + +class ModJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/ai-toolkit/jobs/TrainJob.py b/ai-toolkit/jobs/TrainJob.py new file mode 100644 index 0000000000000000000000000000000000000000..b4982d26690a0c63d5dbdd9063614308ee94491f --- /dev/null +++ b/ai-toolkit/jobs/TrainJob.py @@ -0,0 +1,44 @@ +import json +import os + +from jobs import BaseJob +from toolkit.kohya_model_util import load_models_from_stable_diffusion_checkpoint +from collections import OrderedDict +from typing import List +from jobs.process import BaseExtractProcess, TrainFineTuneProcess +from datetime import datetime + + +process_dict = { + 'vae': 'TrainVAEProcess', + 'slider': 'TrainSliderProcess', + 'slider_old': 'TrainSliderProcessOld', + 'lora_hack': 'TrainLoRAHack', + 'rescale_sd': 'TrainSDRescaleProcess', + 'esrgan': 'TrainESRGANProcess', + 'reference': 'TrainReferenceProcess', +} + + +class TrainJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.training_folder = self.get_conf('training_folder', required=True) + self.is_v2 = self.get_conf('is_v2', False) + self.device = self.get_conf('device', 'cpu') + # self.gradient_accumulation_steps = self.get_conf('gradient_accumulation_steps', 1) + # self.mixed_precision = self.get_conf('mixed_precision', False) # fp16 + self.log_dir = self.get_conf('log_dir', None) + + # loads the processes from the config + self.load_processes(process_dict) + + + def run(self): + super().run() + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/ai-toolkit/jobs/__init__.py b/ai-toolkit/jobs/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..7da6c22b1ddd0ea9248e5afbf9b2ba014c137c1a --- /dev/null +++ b/ai-toolkit/jobs/__init__.py @@ -0,0 +1,7 @@ +from .BaseJob import BaseJob +from .ExtractJob import ExtractJob +from .TrainJob import TrainJob +from .MergeJob import MergeJob +from .ModJob import ModJob +from .GenerateJob import GenerateJob +from .ExtensionJob import ExtensionJob diff --git a/ai-toolkit/jobs/process/BaseExtensionProcess.py b/ai-toolkit/jobs/process/BaseExtensionProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..b53dc1c498e64bb4adbc2b967b329fdc4a374925 --- /dev/null +++ b/ai-toolkit/jobs/process/BaseExtensionProcess.py @@ -0,0 +1,19 @@ +from collections import OrderedDict +from typing import ForwardRef +from jobs.process.BaseProcess import BaseProcess + + +class BaseExtensionProcess(BaseProcess): + def __init__( + self, + process_id: int, + job, + config: OrderedDict + ): + super().__init__(process_id, job, config) + self.process_id: int + self.config: OrderedDict + self.progress_bar: ForwardRef('tqdm') = None + + def run(self): + super().run() diff --git a/ai-toolkit/jobs/process/BaseExtractProcess.py b/ai-toolkit/jobs/process/BaseExtractProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..ac10da54d82f15c8264b2799b10b01bb5cf8dc66 --- /dev/null +++ b/ai-toolkit/jobs/process/BaseExtractProcess.py @@ -0,0 +1,86 @@ +import os +from collections import OrderedDict + +from safetensors.torch import save_file + +from jobs.process.BaseProcess import BaseProcess +from toolkit.metadata import get_meta_for_safetensors + +from typing import ForwardRef + +from toolkit.train_tools import get_torch_dtype + + +class BaseExtractProcess(BaseProcess): + + def __init__( + self, + process_id: int, + job, + config: OrderedDict + ): + super().__init__(process_id, job, config) + self.config: OrderedDict + self.output_folder: str + self.output_filename: str + self.output_path: str + self.process_id = process_id + self.job = job + self.config = config + self.dtype = self.get_conf('dtype', self.job.dtype) + self.torch_dtype = get_torch_dtype(self.dtype) + self.extract_unet = self.get_conf('extract_unet', self.job.extract_unet) + self.extract_text_encoder = self.get_conf('extract_text_encoder', self.job.extract_text_encoder) + + def run(self): + # here instead of init because child init needs to go first + self.output_path = self.get_output_path() + # implement in child class + # be sure to call super().run() first + pass + + # you can override this in the child class if you want + # call super().get_output_path(prefix="your_prefix_", suffix="_your_suffix") to extend this + def get_output_path(self, prefix=None, suffix=None): + config_output_path = self.get_conf('output_path', None) + config_filename = self.get_conf('filename', None) + # replace [name] with name + + if config_output_path is not None: + config_output_path = config_output_path.replace('[name]', self.job.name) + return config_output_path + + if config_output_path is None and config_filename is not None: + # build the output path from the output folder and filename + return os.path.join(self.job.output_folder, config_filename) + + # build our own + + if suffix is None: + # we will just add process it to the end of the filename if there is more than one process + # and no other suffix was given + suffix = f"_{self.process_id}" if len(self.config['process']) > 1 else '' + + if prefix is None: + prefix = '' + + output_filename = f"{prefix}{self.output_filename}{suffix}" + + return os.path.join(self.job.output_folder, output_filename) + + def save(self, state_dict): + # prepare meta + save_meta = get_meta_for_safetensors(self.meta, self.job.name) + + # save + os.makedirs(os.path.dirname(self.output_path), exist_ok=True) + + for key in list(state_dict.keys()): + v = state_dict[key] + v = v.detach().clone().to("cpu").to(self.torch_dtype) + state_dict[key] = v + + # having issues with meta + save_file(state_dict, self.output_path, save_meta) + + print(f"Saved to {self.output_path}") diff --git a/ai-toolkit/jobs/process/BaseMergeProcess.py b/ai-toolkit/jobs/process/BaseMergeProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..55dfec68ae62383afae539ff6cb51862033a7e10 --- /dev/null +++ b/ai-toolkit/jobs/process/BaseMergeProcess.py @@ -0,0 +1,46 @@ +import os +from collections import OrderedDict + +from safetensors.torch import save_file + +from jobs.process.BaseProcess import BaseProcess +from toolkit.metadata import get_meta_for_safetensors +from toolkit.train_tools import get_torch_dtype + + +class BaseMergeProcess(BaseProcess): + + def __init__( + self, + process_id: int, + job, + config: OrderedDict + ): + super().__init__(process_id, job, config) + self.process_id: int + self.config: OrderedDict + self.output_path = self.get_conf('output_path', required=True) + self.dtype = self.get_conf('dtype', self.job.dtype) + self.torch_dtype = get_torch_dtype(self.dtype) + + def run(self): + # implement in child class + # be sure to call super().run() first + pass + + def save(self, state_dict): + # prepare meta + save_meta = get_meta_for_safetensors(self.meta, self.job.name) + + # save + os.makedirs(os.path.dirname(self.output_path), exist_ok=True) + + for key in list(state_dict.keys()): + v = state_dict[key] + v = v.detach().clone().to("cpu").to(self.torch_dtype) + state_dict[key] = v + + # having issues with meta + save_file(state_dict, self.output_path, save_meta) + + print(f"Saved to {self.output_path}") diff --git a/ai-toolkit/jobs/process/BaseProcess.py b/ai-toolkit/jobs/process/BaseProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..c58724c987abb4521efc2afa9b1a85740f7429b8 --- /dev/null +++ b/ai-toolkit/jobs/process/BaseProcess.py @@ -0,0 +1,64 @@ +import copy +import json +from collections import OrderedDict + +from toolkit.timer import Timer + + +class BaseProcess(object): + + def __init__( + self, + process_id: int, + job: 'BaseJob', + config: OrderedDict + ): + self.process_id = process_id + self.meta: OrderedDict + self.job = job + self.config = config + self.raw_process_config = config + self.name = self.get_conf('name', self.job.name) + self.meta = copy.deepcopy(self.job.meta) + self.timer: Timer = Timer(f'{self.name} Timer') + self.performance_log_every = self.get_conf('performance_log_every', 0) + + print(json.dumps(self.config, indent=4)) + + def on_error(self, e: Exception): + pass + + def get_conf(self, key, default=None, required=False, as_type=None): + # split key by '.' and recursively get the value + keys = key.split('.') + + # see if it exists in the config + value = self.config + for subkey in keys: + if subkey in value: + value = value[subkey] + else: + value = None + break + + if value is not None: + if as_type is not None: + value = as_type(value) + return value + elif required: + raise ValueError(f'config file error. Missing "config.process[{self.process_id}].{key}" key') + else: + if as_type is not None and default is not None: + return as_type(default) + return default + + def run(self): + # implement in child class + # be sure to call super().run() first incase something is added here + pass + + def add_meta(self, additional_meta: OrderedDict): + self.meta.update(additional_meta) + + +from jobs import BaseJob diff --git a/ai-toolkit/jobs/process/BaseSDTrainProcess.py b/ai-toolkit/jobs/process/BaseSDTrainProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..4e7945fe5e5d0138d06aa1e5fa38a7cdc49a30bb --- /dev/null +++ b/ai-toolkit/jobs/process/BaseSDTrainProcess.py @@ -0,0 +1,2789 @@ +import copy +import glob +import inspect +import json +import random +import shutil +from collections import OrderedDict +import os +import re +import traceback +from typing import Union, List, Optional + +import numpy as np +import yaml +from diffusers import T2IAdapter, ControlNetModel +from diffusers.training_utils import compute_density_for_timestep_sampling +from safetensors.torch import save_file, load_file +# from lycoris.config import PRESET +from torch.utils.data import DataLoader +import torch +import torch.backends.cuda +from huggingface_hub import HfApi, interpreter_login +from toolkit.memory_management import MemoryManager + +from toolkit.basic import value_map +from toolkit.clip_vision_adapter import ClipVisionAdapter +from toolkit.custom_adapter import CustomAdapter +from toolkit.data_loader import get_dataloader_from_datasets, trigger_dataloader_setup_epoch +from toolkit.data_transfer_object.data_loader import FileItemDTO, DataLoaderBatchDTO +from toolkit.ema import ExponentialMovingAverage +from toolkit.embedding import Embedding +from toolkit.image_utils import show_tensors, show_latents, reduce_contrast +from toolkit.ip_adapter import IPAdapter +from toolkit.lora_special import LoRASpecialNetwork +from toolkit.lorm import convert_diffusers_unet_to_lorm, count_parameters, print_lorm_extract_details, \ + lorm_ignore_if_contains, lorm_parameter_threshold, LORM_TARGET_REPLACE_MODULE +from toolkit.lycoris_special import LycorisSpecialNetwork +from toolkit.models.decorator import Decorator +from toolkit.network_mixins import Network +from toolkit.optimizer import get_optimizer +from toolkit.paths import CONFIG_ROOT +from toolkit.progress_bar import ToolkitProgressBar +from toolkit.reference_adapter import ReferenceAdapter +from toolkit.sampler import get_sampler +from toolkit.saving import save_t2i_from_diffusers, load_t2i_model, save_ip_adapter_from_diffusers, \ + load_ip_adapter_model, load_custom_adapter_model + +from toolkit.scheduler import get_lr_scheduler +from toolkit.sd_device_states_presets import get_train_sd_device_state_preset +from toolkit.stable_diffusion_model import StableDiffusion + +from jobs.process import BaseTrainProcess +from toolkit.metadata import get_meta_for_safetensors, load_metadata_from_safetensors, add_base_model_info_to_meta, \ + parse_metadata_from_safetensors +from toolkit.train_tools import get_torch_dtype, LearnableSNRGamma, apply_learnable_snr_gos, apply_snr_weight +import gc + +from tqdm import tqdm + +from toolkit.config_modules import SaveConfig, LoggingConfig, SampleConfig, NetworkConfig, TrainConfig, ModelConfig, \ + GenerateImageConfig, EmbeddingConfig, DatasetConfig, preprocess_dataset_raw_config, AdapterConfig, GuidanceConfig, validate_configs, \ + DecoratorConfig +from toolkit.logging_aitk import create_logger +from diffusers import FluxTransformer2DModel +from toolkit.accelerator import get_accelerator, unwrap_model +from toolkit.print import print_acc +from accelerate import Accelerator +import transformers +import diffusers +import hashlib + +from toolkit.util.blended_blur_noise import get_blended_blur_noise +from toolkit.util.get_model import get_model_class +from toolkit.basic import flush + + +class BaseSDTrainProcess(BaseTrainProcess): + + def __init__(self, process_id: int, job, config: OrderedDict, custom_pipeline=None): + super().__init__(process_id, job, config) + self.accelerator: Accelerator = get_accelerator() + if self.accelerator.is_local_main_process: + transformers.utils.logging.set_verbosity_warning() + diffusers.utils.logging.set_verbosity_error() + else: + transformers.utils.logging.set_verbosity_error() + diffusers.utils.logging.set_verbosity_error() + + self.sd: StableDiffusion + self.embedding: Union[Embedding, None] = None + + self.custom_pipeline = custom_pipeline + self.step_num = 0 + self.start_step = 0 + self.epoch_num = 0 + self.last_save_step = 0 + # start at 1 so we can do a sample at the start + self.grad_accumulation_step = 1 + # if true, then we do not do an optimizer step. We are accumulating gradients + self.is_grad_accumulation_step = False + self.device = str(self.accelerator.device) + self.device_torch = self.accelerator.device + network_config = self.get_conf('network', None) + if network_config is not None: + self.network_config = NetworkConfig(**network_config) + else: + self.network_config = None + self.train_config = TrainConfig(**self.get_conf('train', {})) + model_config = self.get_conf('model', {}) + self.modules_being_trained: List[torch.nn.Module] = [] + + # update modelconfig dtype to match train + model_config['dtype'] = self.train_config.dtype + self.model_config = ModelConfig(**model_config) + + self.save_config = SaveConfig(**self.get_conf('save', {})) + self.sample_config = SampleConfig(**self.get_conf('sample', {})) + first_sample_config = self.get_conf('first_sample', None) + if first_sample_config is not None: + self.has_first_sample_requested = True + self.first_sample_config = SampleConfig(**first_sample_config) + else: + self.has_first_sample_requested = False + self.first_sample_config = self.sample_config + self.logging_config = LoggingConfig(**self.get_conf('logging', {})) + self.logger = create_logger(self.logging_config, config, self.save_root) + self.optimizer: torch.optim.Optimizer = None + self.lr_scheduler = None + self.data_loader: Union[DataLoader, None] = None + self.data_loader_reg: Union[DataLoader, None] = None + self.trigger_word = self.get_conf('trigger_word', None) + + self.guidance_config: Union[GuidanceConfig, None] = None + guidance_config_raw = self.get_conf('guidance', None) + if guidance_config_raw is not None: + self.guidance_config = GuidanceConfig(**guidance_config_raw) + + # store is all are cached. Allows us to not load vae if we don't need to + self.is_latents_cached = True + raw_datasets = self.get_conf('datasets', None) + if raw_datasets is not None and len(raw_datasets) > 0: + raw_datasets = preprocess_dataset_raw_config(raw_datasets) + self.datasets = None + self.datasets_reg = None + self.dataset_configs: List[DatasetConfig] = [] + self.params = [] + + # add dataset text embedding cache to their config + if self.train_config.cache_text_embeddings: + for raw_dataset in raw_datasets: + raw_dataset['cache_text_embeddings'] = True + + if raw_datasets is not None and len(raw_datasets) > 0: + for raw_dataset in raw_datasets: + dataset = DatasetConfig(**raw_dataset) + # handle trigger word per dataset + if dataset.trigger_word is None and self.trigger_word is not None: + dataset.trigger_word = self.trigger_word + is_caching = dataset.cache_latents or dataset.cache_latents_to_disk + if not is_caching: + self.is_latents_cached = False + if dataset.is_reg: + if self.datasets_reg is None: + self.datasets_reg = [] + self.datasets_reg.append(dataset) + else: + if self.datasets is None: + self.datasets = [] + self.datasets.append(dataset) + self.dataset_configs.append(dataset) + + self.is_caching_text_embeddings = any( + dataset.cache_text_embeddings for dataset in self.dataset_configs + ) + + self.embed_config = None + embedding_raw = self.get_conf('embedding', None) + if embedding_raw is not None: + self.embed_config = EmbeddingConfig(**embedding_raw) + + self.decorator_config: DecoratorConfig = None + decorator_raw = self.get_conf('decorator', None) + if decorator_raw is not None: + if not self.model_config.is_flux: + raise ValueError("Decorators are only supported for Flux models currently") + self.decorator_config = DecoratorConfig(**decorator_raw) + + # t2i adapter + self.adapter_config = None + adapter_raw = self.get_conf('adapter', None) + if adapter_raw is not None: + self.adapter_config = AdapterConfig(**adapter_raw) + # sdxl adapters end in _xl. Only full_adapter_xl for now + if self.model_config.is_xl and not self.adapter_config.adapter_type.endswith('_xl'): + self.adapter_config.adapter_type += '_xl' + + # to hold network if there is one + self.network: Union[Network, None] = None + self.adapter: Union[T2IAdapter, IPAdapter, ClipVisionAdapter, ReferenceAdapter, CustomAdapter, ControlNetModel, None] = None + self.embedding: Union[Embedding, None] = None + self.decorator: Union[Decorator, None] = None + + is_training_adapter = self.adapter_config is not None and self.adapter_config.train + + self.do_lorm = self.get_conf('do_lorm', False) + self.lorm_extract_mode = self.get_conf('lorm_extract_mode', 'ratio') + self.lorm_extract_mode_param = self.get_conf('lorm_extract_mode_param', 0.25) + # 'ratio', 0.25) + + # get the device state preset based on what we are training + self.train_device_state_preset = get_train_sd_device_state_preset( + device=self.device_torch, + train_unet=self.train_config.train_unet, + train_text_encoder=self.train_config.train_text_encoder, + cached_latents=self.is_latents_cached, + train_lora=self.network_config is not None, + train_adapter=is_training_adapter, + train_embedding=self.embed_config is not None, + train_decorator=self.decorator_config is not None, + train_refiner=self.train_config.train_refiner, + unload_text_encoder=self.train_config.unload_text_encoder or self.is_caching_text_embeddings, + require_grads=False # we ensure them later + ) + + self.get_params_device_state_preset = get_train_sd_device_state_preset( + device=self.device_torch, + train_unet=self.train_config.train_unet, + train_text_encoder=self.train_config.train_text_encoder, + cached_latents=self.is_latents_cached, + train_lora=self.network_config is not None, + train_adapter=is_training_adapter, + train_embedding=self.embed_config is not None, + train_decorator=self.decorator_config is not None, + train_refiner=self.train_config.train_refiner, + unload_text_encoder=self.train_config.unload_text_encoder or self.is_caching_text_embeddings, + require_grads=True # We check for grads when getting params + ) + + # fine_tuning here is for training actual SD network, not LoRA, embeddings, etc. it is (Dreambooth, etc) + self.is_fine_tuning = True + if self.network_config is not None or is_training_adapter or self.embed_config is not None or self.decorator_config is not None: + self.is_fine_tuning = False + + self.named_lora = False + if self.embed_config is not None or is_training_adapter: + self.named_lora = True + self.snr_gos: Union[LearnableSNRGamma, None] = None + self.ema: ExponentialMovingAverage = None + + validate_configs(self.train_config, self.model_config, self.save_config, self.dataset_configs) + + do_profiler = self.get_conf('torch_profiler', False) + self.torch_profiler = None if not do_profiler else torch.profiler.profile( + activities=[ + torch.profiler.ProfilerActivity.CPU, + torch.profiler.ProfilerActivity.CUDA, + ], + ) + + self.current_boundary_index = 0 + self.steps_this_boundary = 0 + self.num_consecutive_oom = 0 + self.additional_logs = {} + + def post_process_generate_image_config_list(self, generate_image_config_list: List[GenerateImageConfig]): + # override in subclass + return generate_image_config_list + + def sample(self, step=None, is_first=False): + if not self.accelerator.is_main_process: + return + flush() + sample_folder = os.path.join(self.save_root, 'samples') + gen_img_config_list = [] + + sample_config = self.first_sample_config if is_first else self.sample_config + start_seed = sample_config.seed + current_seed = start_seed + + test_image_paths = [] + if self.adapter_config is not None and self.adapter_config.test_img_path is not None: + test_image_path_list = self.adapter_config.test_img_path + # divide up images so they are evenly distributed across prompts + for i in range(len(sample_config.prompts)): + test_image_paths.append(test_image_path_list[i % len(test_image_path_list)]) + + for i in range(len(sample_config.prompts)): + if sample_config.walk_seed: + current_seed = start_seed + i + + step_num = '' + if step is not None: + # zero-pad 9 digits + step_num = f"_{str(step).zfill(9)}" + + filename = f"[time]_{step_num}_[count].{self.sample_config.ext}" + + output_path = os.path.join(sample_folder, filename) + + prompt = sample_config.prompts[i] + + # add embedding if there is one + # note: diffusers will automatically expand the trigger to the number of added tokens + # ie test123 will become test123 test123_1 test123_2 etc. Do not add this yourself here + if self.embedding is not None: + prompt = self.embedding.inject_embedding_to_prompt( + prompt, expand_token=True, add_if_not_present=False + ) + if self.adapter is not None and isinstance(self.adapter, ClipVisionAdapter): + prompt = self.adapter.inject_trigger_into_prompt( + prompt, expand_token=True, add_if_not_present=False + ) + if self.trigger_word is not None: + prompt = self.sd.inject_trigger_into_prompt( + prompt, self.trigger_word, add_if_not_present=False + ) + + extra_args = {} + if self.adapter_config is not None and self.adapter_config.test_img_path is not None: + extra_args['adapter_image_path'] = test_image_paths[i] + + sample_item = sample_config.samples[i] + if sample_item.seed is not None: + current_seed = sample_item.seed + + gen_img_config_list.append(GenerateImageConfig( + prompt=prompt, # it will autoparse the prompt + width=sample_item.width, + height=sample_item.height, + negative_prompt=sample_item.neg, + seed=current_seed, + guidance_scale=sample_item.guidance_scale, + guidance_rescale=sample_config.guidance_rescale, + num_inference_steps=sample_item.sample_steps, + network_multiplier=sample_item.network_multiplier, + output_path=output_path, + output_ext=sample_config.ext, + adapter_conditioning_scale=sample_config.adapter_conditioning_scale, + refiner_start_at=sample_config.refiner_start_at, + extra_values=sample_config.extra_values, + logger=self.logger, + num_frames=sample_item.num_frames, + fps=sample_item.fps, + ctrl_img=sample_item.ctrl_img, + ctrl_idx=sample_item.ctrl_idx, + ctrl_img_1=sample_item.ctrl_img_1, + ctrl_img_2=sample_item.ctrl_img_2, + ctrl_img_3=sample_item.ctrl_img_3, + do_cfg_norm=sample_config.do_cfg_norm, + **extra_args + )) + + # post process + gen_img_config_list = self.post_process_generate_image_config_list(gen_img_config_list) + + # if we have an ema, set it to validation mode + if self.ema is not None: + self.ema.eval() + + # let adapter know we are sampling + if self.adapter is not None and isinstance(self.adapter, CustomAdapter): + self.adapter.is_sampling = True + + # send to be generated + self.sd.generate_images(gen_img_config_list, sampler=sample_config.sampler) + + + if self.adapter is not None and isinstance(self.adapter, CustomAdapter): + self.adapter.is_sampling = False + + if self.ema is not None: + self.ema.train() + + def update_training_metadata(self): + o_dict = OrderedDict({ + "training_info": self.get_training_info() + }) + o_dict['ss_base_model_version'] = self.sd.get_base_model_version() + + # o_dict = add_base_model_info_to_meta( + # o_dict, + # is_v2=self.model_config.is_v2, + # is_xl=self.model_config.is_xl, + # ) + o_dict['ss_output_name'] = self.job.name + + if self.trigger_word is not None: + # just so auto1111 will pick it up + o_dict['ss_tag_frequency'] = { + f"1_{self.trigger_word}": { + f"{self.trigger_word}": 1 + } + } + + self.add_meta(o_dict) + + def get_training_info(self): + info = OrderedDict({ + 'step': self.step_num, + 'epoch': self.epoch_num, + }) + return info + + def clean_up_saves(self): + if not self.accelerator.is_main_process: + return + # remove old saves + # get latest saved step + latest_item = None + if os.path.exists(self.save_root): + # pattern is {job_name}_{zero_filled_step} for both files and directories + pattern = f"{self.job.name}_*" + items = glob.glob(os.path.join(self.save_root, pattern)) + # Separate files and directories + safetensors_files = [f for f in items if f.endswith('.safetensors')] + pt_files = [f for f in items if f.endswith('.pt')] + directories = [d for d in items if os.path.isdir(d) and not d.endswith('.safetensors')] + embed_files = [] + # do embedding files + if self.embed_config is not None: + embed_pattern = f"{self.embed_config.trigger}_*" + embed_items = glob.glob(os.path.join(self.save_root, embed_pattern)) + # will end in safetensors or pt + embed_files = [f for f in embed_items if f.endswith('.safetensors') or f.endswith('.pt')] + + # check for critic files + critic_pattern = f"CRITIC_{self.job.name}_*" + critic_items = glob.glob(os.path.join(self.save_root, critic_pattern)) + + # Sort the lists by creation time if they are not empty + if safetensors_files: + safetensors_files.sort(key=os.path.getctime) + if pt_files: + pt_files.sort(key=os.path.getctime) + if directories: + directories.sort(key=os.path.getctime) + if embed_files: + embed_files.sort(key=os.path.getctime) + if critic_items: + critic_items.sort(key=os.path.getctime) + + # Combine and sort the lists + combined_items = safetensors_files + directories + pt_files + combined_items.sort(key=os.path.getctime) + + num_saves_to_keep = self.save_config.max_step_saves_to_keep + + if hasattr(self.sd, 'max_step_saves_to_keep_multiplier'): + num_saves_to_keep *= self.sd.max_step_saves_to_keep_multiplier + + # Use slicing with a check to avoid 'NoneType' error + safetensors_to_remove = safetensors_files[ + :-num_saves_to_keep] if safetensors_files else [] + pt_files_to_remove = pt_files[:-num_saves_to_keep] if pt_files else [] + directories_to_remove = directories[:-num_saves_to_keep] if directories else [] + embeddings_to_remove = embed_files[:-num_saves_to_keep] if embed_files else [] + critic_to_remove = critic_items[:-num_saves_to_keep] if critic_items else [] + + items_to_remove = safetensors_to_remove + pt_files_to_remove + directories_to_remove + embeddings_to_remove + critic_to_remove + + # remove all but the latest max_step_saves_to_keep + # items_to_remove = combined_items[:-num_saves_to_keep] + + # remove duplicates + items_to_remove = list(dict.fromkeys(items_to_remove)) + + for item in items_to_remove: + print_acc(f"Removing old save: {item}") + if os.path.isdir(item): + shutil.rmtree(item) + else: + os.remove(item) + # see if a yaml file with same name exists + yaml_file = os.path.splitext(item)[0] + ".yaml" + if os.path.exists(yaml_file): + os.remove(yaml_file) + if combined_items: + latest_item = combined_items[-1] + return latest_item + + def post_save_hook(self, save_path): + # override in subclass + pass + + def done_hook(self): + pass + + def end_step_hook(self): + pass + + def save(self, step=None): + if not self.accelerator.is_main_process: + return + flush() + if self.ema is not None: + # always save params as ema + self.ema.eval() + + if not os.path.exists(self.save_root): + os.makedirs(self.save_root, exist_ok=True) + + step_num = '' + if step is not None: + self.last_save_step = step + # zeropad 9 digits + step_num = f"_{str(step).zfill(9)}" + + self.update_training_metadata() + filename = f'{self.job.name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + + save_meta = copy.deepcopy(self.meta) + # get extra meta + if self.adapter is not None and isinstance(self.adapter, CustomAdapter): + additional_save_meta = self.adapter.get_additional_save_metadata() + if additional_save_meta is not None: + for key, value in additional_save_meta.items(): + save_meta[key] = value + + # prepare meta + save_meta = get_meta_for_safetensors(save_meta, self.job.name) + if not self.is_fine_tuning and not self.train_config.merge_network_on_save: + if self.network is not None: + lora_name = self.job.name + if self.named_lora: + # add _lora to name + lora_name += '_LoRA' + + filename = f'{lora_name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + prev_multiplier = self.network.multiplier + self.network.multiplier = 1.0 + + # if we are doing embedding training as well, add that + embedding_dict = self.embedding.state_dict() if self.embedding else None + self.network.save_weights( + file_path, + dtype=get_torch_dtype(self.save_config.dtype), + metadata=save_meta, + extra_state_dict=embedding_dict + ) + self.network.multiplier = prev_multiplier + # if we have an embedding as well, pair it with the network + + # even if added to lora, still save the trigger version + if self.embedding is not None: + emb_filename = f'{self.embed_config.trigger}{step_num}.safetensors' + emb_file_path = os.path.join(self.save_root, emb_filename) + # for combo, above will get it + # set current step + self.embedding.step = self.step_num + # change filename to pt if that is set + if self.embed_config.save_format == "pt": + # replace extension + emb_file_path = os.path.splitext(emb_file_path)[0] + ".pt" + self.embedding.save(emb_file_path) + + if self.decorator is not None: + dec_filename = f'{self.job.name}{step_num}.safetensors' + dec_file_path = os.path.join(self.save_root, dec_filename) + decorator_state_dict = self.decorator.state_dict() + for key, value in decorator_state_dict.items(): + if isinstance(value, torch.Tensor): + decorator_state_dict[key] = value.clone().to('cpu', dtype=get_torch_dtype(self.save_config.dtype)) + save_file( + decorator_state_dict, + dec_file_path, + metadata=save_meta, + ) + + if self.adapter is not None and self.adapter_config.train: + adapter_name = self.job.name + if self.network_config is not None or self.embedding is not None: + # add _lora to name + if self.adapter_config.type == 't2i': + adapter_name += '_t2i' + elif self.adapter_config.type == 'control_net': + adapter_name += '_cn' + elif self.adapter_config.type == 'clip': + adapter_name += '_clip' + elif self.adapter_config.type.startswith('ip'): + adapter_name += '_ip' + else: + adapter_name += '_adapter' + + filename = f'{adapter_name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + # save adapter + state_dict = self.adapter.state_dict() + if self.adapter_config.type == 't2i': + save_t2i_from_diffusers( + state_dict, + output_file=file_path, + meta=save_meta, + dtype=get_torch_dtype(self.save_config.dtype) + ) + elif self.adapter_config.type == 'control_net': + # save in diffusers format + name_or_path = file_path.replace('.safetensors', '') + # move it to the new dtype and cpu + orig_device = self.adapter.device + orig_dtype = self.adapter.dtype + self.adapter = self.adapter.to(torch.device('cpu'), dtype=get_torch_dtype(self.save_config.dtype)) + self.adapter.save_pretrained( + name_or_path, + dtype=get_torch_dtype(self.save_config.dtype), + safe_serialization=True + ) + meta_path = os.path.join(name_or_path, 'aitk_meta.yaml') + with open(meta_path, 'w') as f: + yaml.dump(self.meta, f) + # move it back + self.adapter = self.adapter.to(orig_device, dtype=orig_dtype) + else: + direct_save = False + if self.adapter_config.train_only_image_encoder: + direct_save = True + elif isinstance(self.adapter, CustomAdapter): + direct_save = self.adapter.do_direct_save + save_ip_adapter_from_diffusers( + state_dict, + output_file=file_path, + meta=save_meta, + dtype=get_torch_dtype(self.save_config.dtype), + direct_save=direct_save + ) + else: + if self.network is not None and self.train_config.merge_network_on_save: + # merge the network weights into a full model and save that. + # torchao quantized weights can be force merged here (dequantize -> merge -> re-quantize) + # even though can_merge_in is False (kept False so sampling never merges). quanto and + # layer_offloading still cannot merge. + from toolkit.util.quantize import get_torchao_config + can_force_quantized_merge = ( + self.model_config.quantize and not self.model_config.layer_offloading + and get_torchao_config(self.model_config.qtype) is not None + ) + if not self.network.can_merge_in and not can_force_quantized_merge: + raise ValueError("Network cannot merge in weights. Cannot save full model.") + + print_acc("Merging network weights into full model for saving...") + + self.network.merge_in(merge_weight=self.train_config.merge_network_on_save_strength) + # reset weights to zero + self.network.reset_weights() + self.network.is_merged_in = False + + print_acc("Done merging network weights. Saving model...") + + if self.save_config.save_format == "diffusers": + # saving as a folder path + file_path = file_path.replace('.safetensors', '') + # convert it back to normal object + save_meta = parse_metadata_from_safetensors(save_meta) + + if self.sd.refiner_unet and self.train_config.train_refiner: + # save refiner + refiner_name = self.job.name + '_refiner' + filename = f'{refiner_name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + self.sd.save_refiner( + file_path, + save_meta, + get_torch_dtype(self.save_config.dtype) + ) + if self.train_config.train_unet or self.train_config.train_text_encoder: + self.sd.save( + file_path, + save_meta, + get_torch_dtype(self.save_config.dtype) + ) + + # save learnable params as json if we have thim + if self.snr_gos: + json_data = { + 'offset_1': self.snr_gos.offset_1.item(), + 'offset_2': self.snr_gos.offset_2.item(), + 'scale': self.snr_gos.scale.item(), + 'gamma': self.snr_gos.gamma.item(), + } + path_to_save = file_path = os.path.join(self.save_root, 'learnable_snr.json') + with open(path_to_save, 'w') as f: + json.dump(json_data, f, indent=4) + + print_acc(f"Saved checkpoint to {file_path}") + + # save optimizer + if self.optimizer is not None: + try: + filename = f'optimizer.pt' + file_path = os.path.join(self.save_root, filename) + try: + state_dict = unwrap_model(self.optimizer).state_dict() + except Exception as e: + state_dict = self.optimizer.state_dict() + torch.save(state_dict, file_path) + print_acc(f"Saved optimizer to {file_path}") + except Exception as e: + print_acc(e) + print_acc("Could not save optimizer") + + self.clean_up_saves() + self.post_save_hook(file_path) + + if self.ema is not None: + self.ema.train() + flush() + + # Called before the model is loaded + def hook_before_model_load(self): + # override in subclass + pass + + def hook_after_model_load(self): + # override in subclass + pass + + def hook_add_extra_train_params(self, params): + # override in subclass + return params + + def hook_before_train_loop(self): + if self.accelerator.is_main_process: + self.logger.start() + self.prepare_accelerator() + + def sample_step_hook(self, img_num, total_imgs): + pass + + def prepare_accelerator(self): + # set some config + self.accelerator.even_batches=False + + # # prepare all the models stuff for accelerator (hopefully we dont miss any) + self.sd.vae = self.accelerator.prepare(self.sd.vae) + if self.sd.unet is not None: + self.sd.unet = self.accelerator.prepare(self.sd.unet) + # todo always tdo it? + self.modules_being_trained.append(self.sd.unet) + if self.sd.text_encoder is not None and self.train_config.train_text_encoder: + if isinstance(self.sd.text_encoder, list): + self.sd.text_encoder = [self.accelerator.prepare(model) for model in self.sd.text_encoder] + self.modules_being_trained.extend(self.sd.text_encoder) + else: + self.sd.text_encoder = self.accelerator.prepare(self.sd.text_encoder) + self.modules_being_trained.append(self.sd.text_encoder) + if self.sd.refiner_unet is not None and self.train_config.train_refiner: + self.sd.refiner_unet = self.accelerator.prepare(self.sd.refiner_unet) + self.modules_being_trained.append(self.sd.refiner_unet) + # todo, do we need to do the network or will "unet" get it? + if self.sd.network is not None: + self.sd.network = self.accelerator.prepare(self.sd.network) + self.modules_being_trained.append(self.sd.network) + if self.adapter is not None and self.adapter_config.train: + # todo adapters may not be a module. need to check + self.adapter = self.accelerator.prepare(self.adapter) + self.modules_being_trained.append(self.adapter) + + # prepare other things + self.optimizer = self.accelerator.prepare(self.optimizer) + if self.lr_scheduler is not None: + self.lr_scheduler = self.accelerator.prepare(self.lr_scheduler) + # self.data_loader = self.accelerator.prepare(self.data_loader) + # if self.data_loader_reg is not None: + # self.data_loader_reg = self.accelerator.prepare(self.data_loader_reg) + + + def ensure_params_requires_grad(self, force=False): + if self.train_config.do_paramiter_swapping and not force: + # the optimizer will handle this if we are not forcing + return + for group in self.params: + for param in group['params']: + if isinstance(param, torch.nn.Parameter): # Ensure it's a proper parameter + param.requires_grad_(True) + + def setup_ema(self): + if self.train_config.ema_config.use_ema: + # our params are in groups. We need them as a single iterable + params = [] + for group in self.optimizer.param_groups: + for param in group['params']: + params.append(param) + self.ema = ExponentialMovingAverage( + params, + decay=self.train_config.ema_config.ema_decay, + use_feedback=self.train_config.ema_config.use_feedback, + param_multiplier=self.train_config.ema_config.param_multiplier, + ) + + def before_dataset_load(self): + pass + + def get_params(self): + # you can extend this in subclass to get params + # otherwise params will be gathered through normal means + return None + + def hook_train_loop(self, batch): + # return loss + return 0.0 + + def hook_after_sd_init_before_load(self): + pass + + def get_latest_save_path(self, name=None, post=''): + if name == None: + name = self.job.name + # get latest saved step + latest_path = None + if os.path.exists(self.save_root): + # Define patterns for both files and directories + patterns = [ + f"{name}*{post}.safetensors", + f"{name}*{post}.pt", + f"{name}*{post}" + ] + # Search for both files and directories + paths = [] + for pattern in patterns: + paths.extend(glob.glob(os.path.join(self.save_root, pattern))) + + # Filter out non-existent paths and sort by creation time + if paths: + paths = [p for p in paths if os.path.exists(p)] + # remove false positives + if '_LoRA' not in name: + paths = [p for p in paths if '_LoRA' not in p] + if '_refiner' not in name: + paths = [p for p in paths if '_refiner' not in p] + if '_t2i' not in name: + paths = [p for p in paths if '_t2i' not in p] + if '_cn' not in name: + paths = [p for p in paths if '_cn' not in p] + + if len(paths) > 0: + latest_path = max(paths, key=os.path.getctime) + + if latest_path is None and self.network_config is not None and self.network_config.pretrained_lora_path is not None: + # set pretrained lora path as load path if we do not have a checkpoint to resume from + if os.path.exists(self.network_config.pretrained_lora_path): + latest_path = self.network_config.pretrained_lora_path + print_acc(f"Using pretrained lora path from config: {latest_path}") + else: + # no pretrained lora found + print_acc(f"Pretrained lora path from config does not exist: {self.network_config.pretrained_lora_path}") + + return latest_path + + def load_training_state_from_metadata(self, path): + if not self.accelerator.is_main_process: + return + if path is not None and self.network_config is not None and path == self.network_config.pretrained_lora_path: + # dont load metadata from pretrained lora + return + meta = None + # if path is folder, then it is diffusers + if os.path.isdir(path): + meta_path = os.path.join(path, 'aitk_meta.yaml') + # load it + if os.path.exists(meta_path): + with open(meta_path, 'r') as f: + meta = yaml.load(f, Loader=yaml.FullLoader) + else: + meta = load_metadata_from_safetensors(path) + # if 'training_info' in Orderdict keys + if meta is not None and 'training_info' in meta and 'step' in meta['training_info'] and self.train_config.start_step is None: + self.step_num = meta['training_info']['step'] + if 'epoch' in meta['training_info']: + self.epoch_num = meta['training_info']['epoch'] + self.start_step = self.step_num + print_acc(f"Found step {self.step_num} in metadata, starting from there") + + def load_weights(self, path): + if self.network is not None: + extra_weights = self.network.load_weights(path) + self.load_training_state_from_metadata(path) + return extra_weights + else: + print_acc("load_weights not implemented for non-network models") + return None + + def apply_snr(self, seperated_loss, timesteps): + if self.train_config.learnable_snr_gos: + # add snr_gamma + seperated_loss = apply_learnable_snr_gos(seperated_loss, timesteps, self.snr_gos) + elif self.train_config.snr_gamma is not None and self.train_config.snr_gamma > 0.000001: + # add snr_gamma + seperated_loss = apply_snr_weight(seperated_loss, timesteps, self.sd.noise_scheduler, self.train_config.snr_gamma, fixed=True) + elif self.train_config.min_snr_gamma is not None and self.train_config.min_snr_gamma > 0.000001: + # add min_snr_gamma + seperated_loss = apply_snr_weight(seperated_loss, timesteps, self.sd.noise_scheduler, self.train_config.min_snr_gamma) + + return seperated_loss + + def load_lorm(self): + latest_save_path = self.get_latest_save_path() + if latest_save_path is not None: + # hacky way to reload weights for now + # todo, do this + state_dict = load_file(latest_save_path, device=self.device) + self.sd.unet.load_state_dict(state_dict) + + meta = load_metadata_from_safetensors(latest_save_path) + # if 'training_info' in Orderdict keys + if 'training_info' in meta and 'step' in meta['training_info']: + self.step_num = meta['training_info']['step'] + if 'epoch' in meta['training_info']: + self.epoch_num = meta['training_info']['epoch'] + self.start_step = self.step_num + print_acc(f"Found step {self.step_num} in metadata, starting from there") + + # def get_sigmas(self, timesteps, n_dim=4, dtype=torch.float32): + # self.sd.noise_scheduler.set_timesteps(1000, device=self.device_torch) + # sigmas = self.sd.noise_scheduler.sigmas.to(device=self.device_torch, dtype=dtype) + # schedule_timesteps = self.sd.noise_scheduler.timesteps.to(self.device_torch, ) + # timesteps = timesteps.to(self.device_torch, ) + # + # # step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps] + # step_indices = [t for t in timesteps] + # + # sigma = sigmas[step_indices].flatten() + # while len(sigma.shape) < n_dim: + # sigma = sigma.unsqueeze(-1) + # return sigma + + def load_additional_training_modules(self, params): + # override in subclass + return params + + def get_sigmas(self, timesteps, n_dim=4, dtype=torch.float32): + sigmas = self.sd.noise_scheduler.sigmas.to(device=self.device, dtype=dtype) + schedule_timesteps = self.sd.noise_scheduler.timesteps.to(self.device) + timesteps = timesteps.to(self.device) + + step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps] + + sigma = sigmas[step_indices].flatten() + while len(sigma.shape) < n_dim: + sigma = sigma.unsqueeze(-1) + return sigma + + def get_optimal_noise(self, latents, dtype=torch.float32): + batch_num = latents.shape[0] + chunks = torch.chunk(latents, batch_num, dim=0) + noise_chunks = [] + for chunk in chunks: + noise_samples = [torch.randn_like(chunk, device=chunk.device, dtype=dtype) for _ in range(self.train_config.optimal_noise_pairing_samples)] + # find the one most similar to the chunk + lowest_loss = 999999999999 + best_noise = None + for noise in noise_samples: + loss = torch.nn.functional.mse_loss(chunk, noise) + if loss < lowest_loss: + lowest_loss = loss + best_noise = noise + noise_chunks.append(best_noise) + noise = torch.cat(noise_chunks, dim=0) + return noise + + def get_consistent_noise(self, latents, batch: 'DataLoaderBatchDTO', dtype=torch.float32): + batch_num = latents.shape[0] + chunks = torch.chunk(latents, batch_num, dim=0) + noise_chunks = [] + for idx, chunk in enumerate(chunks): + # get seed from path + file_item = batch.file_items[idx] + img_path = file_item.path + # add augmentors + if file_item.flip_x: + img_path += '_fx' + if file_item.flip_y: + img_path += '_fy' + seed = int(hashlib.md5(img_path.encode()).hexdigest(), 16) & 0xffffffff + generator = torch.Generator("cpu").manual_seed(seed) + noise_chunk = torch.randn(chunk.shape, generator=generator).to(chunk.device, dtype=dtype) + noise_chunks.append(noise_chunk) + noise = torch.cat(noise_chunks, dim=0).to(dtype=dtype) + return noise + + + def get_noise( + self, + latents, + batch_size, + dtype=torch.float32, + batch: 'DataLoaderBatchDTO' = None, + timestep=None, + ): + if self.train_config.optimal_noise_pairing_samples > 1: + noise = self.get_optimal_noise(latents, dtype=dtype) + elif self.train_config.force_consistent_noise: + if batch is None: + raise ValueError("Batch must be provided for consistent noise") + noise = self.get_consistent_noise(latents, batch, dtype=dtype) + else: + if hasattr(self.sd, 'get_latent_noise_from_latents'): + noise = self.sd.get_latent_noise_from_latents( + latents, + noise_offset=self.train_config.noise_offset + ).to(self.device_torch, dtype=dtype) + else: + # get noise + noise = self.sd.get_latent_noise( + height=latents.shape[2], + width=latents.shape[3], + num_channels=latents.shape[1], + batch_size=batch_size, + noise_offset=self.train_config.noise_offset, + ).to(self.device_torch, dtype=dtype) + + if self.train_config.blended_blur_noise: + noise = get_blended_blur_noise( + latents, noise, timestep + ) + + return noise + + def process_general_training_batch(self, batch: 'DataLoaderBatchDTO'): + with torch.no_grad(): + with self.timer('prepare_prompt'): + prompts = batch.get_caption_list() + is_reg_list = batch.get_is_reg_list() + + is_any_reg = any([is_reg for is_reg in is_reg_list]) + + do_double = self.train_config.short_and_long_captions and not is_any_reg + + if self.train_config.short_and_long_captions and do_double: + # dont do this with regs. No point + + # double batch and add short captions to the end + prompts = prompts + batch.get_caption_short_list() + is_reg_list = is_reg_list + is_reg_list + if self.model_config.refiner_name_or_path is not None and self.train_config.train_unet: + prompts = prompts + prompts + is_reg_list = is_reg_list + is_reg_list + + conditioned_prompts = [] + + for prompt, is_reg in zip(prompts, is_reg_list): + + # make sure the embedding is in the prompts + if self.embedding is not None: + prompt = self.embedding.inject_embedding_to_prompt( + prompt, + expand_token=True, + add_if_not_present=not is_reg, + ) + + if self.adapter and isinstance(self.adapter, ClipVisionAdapter): + prompt = self.adapter.inject_trigger_into_prompt( + prompt, + expand_token=True, + add_if_not_present=not is_reg, + ) + + # make sure trigger is in the prompts if not a regularization run + if self.trigger_word is not None: + prompt = self.sd.inject_trigger_into_prompt( + prompt, + trigger=self.trigger_word, + add_if_not_present=not is_reg, + ) + + if not is_reg and self.train_config.prompt_saturation_chance > 0.0: + # do random prompt saturation by expanding the prompt to hit at least 77 tokens + if random.random() < self.train_config.prompt_saturation_chance: + est_num_tokens = len(prompt.split(' ')) + if est_num_tokens < 77: + num_repeats = int(77 / est_num_tokens) + 1 + prompt = ', '.join([prompt] * num_repeats) + + + conditioned_prompts.append(prompt) + + with self.timer('prepare_latents'): + dtype = get_torch_dtype(self.train_config.dtype) + imgs = None + is_reg = any(batch.get_is_reg_list()) + if batch.tensor is not None: + imgs = batch.tensor + imgs = imgs.to(self.device_torch, dtype=dtype) + # dont adjust for regs. + if self.train_config.img_multiplier is not None and not is_reg: + # do it ad contrast + imgs = reduce_contrast(imgs, self.train_config.img_multiplier) + if batch.latents is not None: + latents = batch.latents.to(self.device_torch, dtype=dtype) + batch.latents = latents + else: + # normalize to + if self.train_config.standardize_images: + if self.sd.is_xl or self.sd.is_vega or self.sd.is_ssd: + target_mean_list = [0.0002, -0.1034, -0.1879] + target_std_list = [0.5436, 0.5116, 0.5033] + else: + target_mean_list = [-0.0739, -0.1597, -0.2380] + target_std_list = [0.5623, 0.5295, 0.5347] + # Mean: tensor([-0.0739, -0.1597, -0.2380]) + # Standard Deviation: tensor([0.5623, 0.5295, 0.5347]) + imgs_channel_mean = imgs.mean(dim=(2, 3), keepdim=True) + imgs_channel_std = imgs.std(dim=(2, 3), keepdim=True) + imgs = (imgs - imgs_channel_mean) / imgs_channel_std + target_mean = torch.tensor(target_mean_list, device=self.device_torch, dtype=dtype) + target_std = torch.tensor(target_std_list, device=self.device_torch, dtype=dtype) + # expand them to match dim + target_mean = target_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3) + target_std = target_std.unsqueeze(0).unsqueeze(2).unsqueeze(3) + + imgs = imgs * target_std + target_mean + batch.tensor = imgs + + # show_tensors(imgs, 'imgs') + + latents = self.sd.encode_images(imgs) + batch.latents = latents + + if self.train_config.standardize_latents: + if self.sd.is_xl or self.sd.is_vega or self.sd.is_ssd: + target_mean_list = [-0.1075, 0.0231, -0.0135, 0.2164] + target_std_list = [0.8979, 0.7505, 0.9150, 0.7451] + else: + target_mean_list = [0.2949, -0.3188, 0.0807, 0.1929] + target_std_list = [0.8560, 0.9629, 0.7778, 0.6719] + + latents_channel_mean = latents.mean(dim=(2, 3), keepdim=True) + latents_channel_std = latents.std(dim=(2, 3), keepdim=True) + latents = (latents - latents_channel_mean) / latents_channel_std + target_mean = torch.tensor(target_mean_list, device=self.device_torch, dtype=dtype) + target_std = torch.tensor(target_std_list, device=self.device_torch, dtype=dtype) + # expand them to match dim + target_mean = target_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3) + target_std = target_std.unsqueeze(0).unsqueeze(2).unsqueeze(3) + + latents = latents * target_std + target_mean + batch.latents = latents + + # show_latents(latents, self.sd.vae, 'latents') + + + if batch.unconditional_tensor is not None and batch.unconditional_latents is None: + unconditional_imgs = batch.unconditional_tensor + unconditional_imgs = unconditional_imgs.to(self.device_torch, dtype=dtype) + unconditional_latents = self.sd.encode_images(unconditional_imgs) + batch.unconditional_latents = unconditional_latents * self.train_config.latent_multiplier + + unaugmented_latents = None + if self.train_config.loss_target == 'differential_noise': + # we determine noise from the differential of the latents + unaugmented_latents = self.sd.encode_images(batch.unaugmented_tensor) + + with self.timer('prepare_scheduler'): + + batch_size = len(batch.file_items) + min_noise_steps = self.train_config.min_denoising_steps + max_noise_steps = self.train_config.max_denoising_steps + if self.model_config.refiner_name_or_path is not None: + # if we are not training the unet, then we are only doing refiner and do not need to double up + if self.train_config.train_unet: + max_noise_steps = round(self.train_config.max_denoising_steps * self.model_config.refiner_start_at) + do_double = True + else: + min_noise_steps = round(self.train_config.max_denoising_steps * self.model_config.refiner_start_at) + do_double = False + + num_train_timesteps = self.train_config.num_train_timesteps + + if self.train_config.noise_scheduler in ['custom_lcm']: + # we store this value on our custom one + self.sd.noise_scheduler.set_timesteps( + self.sd.noise_scheduler.train_timesteps, device=self.device_torch + ) + elif self.train_config.noise_scheduler in ['lcm']: + self.sd.noise_scheduler.set_timesteps( + num_train_timesteps, device=self.device_torch, original_inference_steps=num_train_timesteps + ) + elif self.train_config.noise_scheduler == 'flowmatch': + linear_timesteps = any([ + self.train_config.linear_timesteps, + self.train_config.linear_timesteps2, + self.train_config.timestep_type == 'linear', + self.train_config.timestep_type in ['one_step', 'two_step', 'four_step', 'eight_step'], + ]) + + timestep_type = 'linear' if linear_timesteps else None + if timestep_type is None: + timestep_type = self.train_config.timestep_type + + if self.train_config.timestep_type == 'next_sample': + # simulate a sample + num_train_timesteps = self.train_config.next_sample_timesteps + timestep_type = 'shift' + + patch_size = 1 + if self.sd.is_flux or 'flex' in self.sd.arch: + # flux is a patch size of 1, but latents are divided by 2, so we need to double it + patch_size = 2 + elif hasattr(self.sd.unet, 'config') and hasattr(self.sd.unet.config, 'patch_size'): + patch_size = self.sd.unet.config.patch_size + + self.sd.noise_scheduler.set_train_timesteps( + num_train_timesteps, + device=self.device_torch, + timestep_type=timestep_type, + latents=latents, + patch_size=patch_size, + ) + else: + self.sd.noise_scheduler.set_timesteps( + num_train_timesteps, device=self.device_torch + ) + if self.sd.is_multistage: + with self.timer('adjust_multistage_timesteps'): + # get our current sample range + boundaries = [1] + self.sd.multistage_boundaries + boundary_max, boundary_min = boundaries[self.current_boundary_index], boundaries[self.current_boundary_index + 1] + asc_timesteps = torch.flip(self.sd.noise_scheduler.timesteps, dims=[0]) + lo = len(asc_timesteps) - torch.searchsorted(asc_timesteps, torch.tensor(boundary_max * 1000, device=asc_timesteps.device), right=False) + hi = len(asc_timesteps) - torch.searchsorted(asc_timesteps, torch.tensor(boundary_min * 1000, device=asc_timesteps.device), right=True) + first_idx = (lo - 1).item() if hi > lo else 0 + last_idx = (hi - 1).item() if hi > lo else 999 + min_noise_steps = first_idx + max_noise_steps = last_idx + + # clip min max indicies + min_noise_steps = max(min_noise_steps, 0) + max_noise_steps = min(max_noise_steps, num_train_timesteps - 1) + + + with self.timer('prepare_timesteps_indices'): + + content_or_style = self.train_config.content_or_style + if is_reg: + content_or_style = self.train_config.content_or_style_reg + + if self.train_config.timestep_type in ['two_step', 'four_step', 'eight_step']: + if self.train_config.timestep_type == 'two_step': + indice_choices = [0, 499] + elif self.train_config.timestep_type == 'four_step': + indice_choices = [0, 250, 500, 750] + elif self.train_config.timestep_type == 'eight_step': + indice_choices = [0, 125, 250, 375, 500, 625, 750, 875] + timestep_indices = torch.tensor(random.choices(indice_choices, k=batch_size), device=self.device_torch) + timestep_indices = timestep_indices.long() + elif self.train_config.timestep_type == 'next_sample': + timestep_indices = torch.randint( + 0, + num_train_timesteps - 2, # -1 for 0 idx, -1 so we can step + (batch_size,), + device=self.device_torch + ) + timestep_indices = timestep_indices.long() + elif self.train_config.timestep_type == 'one_step': + timestep_indices = torch.zeros((batch_size,), device=self.device_torch, dtype=torch.long) + elif content_or_style in ['style', 'content']: + # this is from diffusers training code + # Cubic sampling for favoring later or earlier timesteps + # For more details about why cubic sampling is used for content / structure, + # refer to section 3.4 of https://arxiv.org/abs/2302.08453 + + # for content / structure, it is best to favor earlier timesteps + # for style, it is best to favor later timesteps + + orig_timesteps = torch.rand((batch_size,), device=latents.device) + + if content_or_style == 'content': + timestep_indices = orig_timesteps ** 3 * self.train_config.num_train_timesteps + elif content_or_style == 'style': + timestep_indices = (1 - orig_timesteps ** 3) * self.train_config.num_train_timesteps + + timestep_indices = value_map( + timestep_indices, + 0, + self.train_config.num_train_timesteps - 1, + min_noise_steps, + max_noise_steps + ) + timestep_indices = timestep_indices.long().clamp( + min_noise_steps, + max_noise_steps + ) + + elif content_or_style == 'balanced': + if min_noise_steps == max_noise_steps: + timestep_indices = torch.ones((batch_size,), device=self.device_torch) * min_noise_steps + else: + # todo, some schedulers use indices, otheres use timesteps. Not sure what to do here + min_idx = min_noise_steps + 1 + max_idx = max_noise_steps - 1 + if self.train_config.noise_scheduler == 'flowmatch': + # flowmatch uses indices, so we need to use indices + min_idx = min_noise_steps + max_idx = max_noise_steps + timestep_indices = torch.randint( + min_idx, + max_idx, + (batch_size,), + device=self.device_torch + ) + timestep_indices = timestep_indices.long() + else: + raise ValueError(f"Unknown content_or_style {content_or_style}") + with self.timer('convert_timestep_indices_to_timesteps'): + # convert the timestep_indices to a timestep + timesteps = self.sd.noise_scheduler.timesteps[timestep_indices.long()] + + with self.timer('prepare_noise'): + # get noise + noise = self.get_noise(latents, batch_size, dtype=dtype, batch=batch, timestep=timesteps) + + # add dynamic noise offset. Dynamic noise is offsetting the noise to the same channelwise mean as the latents + # this will negate any noise offsets + if self.train_config.dynamic_noise_offset and not is_reg: + latents_channel_mean = latents.mean(dim=(2, 3), keepdim=True) / 2 + # subtract channel mean to that we compensate for the mean of the latents on the noise offset per channel + noise = noise + latents_channel_mean + + if self.train_config.loss_target == 'differential_noise': + differential = latents - unaugmented_latents + # add noise to differential + # noise = noise + differential + noise = noise + (differential * 0.5) + # noise = value_map(differential, 0, torch.abs(differential).max(), 0, torch.abs(noise).max()) + latents = unaugmented_latents + + noise_multiplier = self.train_config.noise_multiplier + + s = (noise.shape[0], noise.shape[1], 1, 1) + if len(noise.shape) == 5: + # if we have a 5d tensor, then we need to do it on a per batch item, per channel basis, per frame + s = (noise.shape[0], noise.shape[1], noise.shape[2], 1, 1) + + noise = noise * noise_multiplier + + if self.train_config.do_signal_correction_noise: + batch_noise = latents.clone().to(noise.device, dtype=noise.dtype) + scn_scale = torch.randn( + batch_noise.shape[0], batch_noise.shape[1], 1, 1, + device=batch_noise.device, + dtype=batch_noise.dtype + ) * self.train_config.signal_correction_noise_scale + batch_noise = batch_noise * scn_scale + noise = noise + batch_noise + + if self.train_config.do_batch_noise_correction: + if latents.shape[0] == 1: + # if we only have a batch size of 1, then we cant do batch noise correction, so we skip it + print_acc("Skipping batch noise correction because batch size is 1, increase batch size and num_repeats to use this feature") + else: + # shuffle tensors ensuring that no tensor is in the same position as before + batch_noise = latents.clone().roll(shifts=torch.randint(1, latents.shape[0], (1,)).item(), dims=0).to(noise.device, dtype=noise.dtype) + batch_noise_scale = torch.randn( + batch_noise.shape[0], batch_noise.shape[1], 1, 1, + device=batch_noise.device, + dtype=batch_noise.dtype + ) * self.train_config.batch_noise_correction_scale + batch_noise = batch_noise * batch_noise_scale + noise = noise + batch_noise + + if self.train_config.random_noise_shift > 0.0: + # get random noise -1 to 1 + noise_shift = torch.randn( + batch_size, latents.shape[1], 1, 1, + device=noise.device, + dtype=noise.dtype + ) * self.train_config.random_noise_shift + # add to noise + noise += noise_shift + + if self.train_config.random_noise_multiplier > 0.0: + sigma = self.train_config.random_noise_multiplier + noise_multiplier = torch.exp(torch.randn(s, device=noise.device, dtype=noise.dtype) * sigma) + noise = noise * noise_multiplier + with self.timer('make_noisy_latents'): + + latent_multiplier = self.train_config.latent_multiplier + + # handle adaptive scaling mased on std + if self.train_config.adaptive_scaling_factor: + std = latents.std(dim=(2, 3), keepdim=True) + normalizer = 1 / (std + 1e-6) + latent_multiplier = normalizer + + latents = latents * latent_multiplier + + if self.train_config.do_blank_stabilization: + # zero out latents with blank prompts + blank_latent = torch.zeros_like(latents) + for i, prompt in enumerate(conditioned_prompts): + if prompt.strip() == '': + latents[i] = blank_latent[i] + + batch.latents = latents + + # normalize latents to a mean of 0 and an std of 1 + # mean_zero_latents = latents - latents.mean() + # latents = mean_zero_latents / mean_zero_latents.std() + + if batch.unconditional_latents is not None: + batch.unconditional_latents = batch.unconditional_latents * self.train_config.latent_multiplier + + + noisy_latents = self.sd.add_noise(latents, noise, timesteps) + + # determine scaled noise + # todo do we need to scale this or does it always predict full intensity + # noise = noisy_latents - latents + + # https://github.com/huggingface/diffusers/blob/324d18fba23f6c9d7475b0ff7c777685f7128d40/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L1170C17-L1171C77 + if self.train_config.loss_target == 'source' or self.train_config.loss_target == 'unaugmented': + sigmas = self.get_sigmas(timesteps, len(noisy_latents.shape), noisy_latents.dtype) + # add it to the batch + batch.sigmas = sigmas + # todo is this for sdxl? find out where this came from originally + # noisy_latents = noisy_latents / ((sigmas ** 2 + 1) ** 0.5) + + def double_up_tensor(tensor: torch.Tensor): + if tensor is None: + return None + return torch.cat([tensor, tensor], dim=0) + + if do_double: + if self.model_config.refiner_name_or_path: + # apply refiner double up + refiner_timesteps = torch.randint( + max_noise_steps, + self.train_config.max_denoising_steps, + (batch_size,), + device=self.device_torch + ) + refiner_timesteps = refiner_timesteps.long() + # add our new timesteps on to end + timesteps = torch.cat([timesteps, refiner_timesteps], dim=0) + + refiner_noisy_latents = self.sd.noise_scheduler.add_noise(latents, noise, refiner_timesteps) + noisy_latents = torch.cat([noisy_latents, refiner_noisy_latents], dim=0) + + else: + # just double it + noisy_latents = double_up_tensor(noisy_latents) + timesteps = double_up_tensor(timesteps) + + noise = double_up_tensor(noise) + # prompts are already updated above + imgs = double_up_tensor(imgs) + batch.mask_tensor = double_up_tensor(batch.mask_tensor) + batch.control_tensor = double_up_tensor(batch.control_tensor) + + noisy_latent_multiplier = self.train_config.noisy_latent_multiplier + + if noisy_latent_multiplier != 1.0: + noisy_latents = noisy_latents * noisy_latent_multiplier + + # remove grads for these + noisy_latents.requires_grad = False + noisy_latents = noisy_latents.detach() + noise.requires_grad = False + noise = noise.detach() + + return noisy_latents, noise, timesteps, conditioned_prompts, imgs + + def setup_adapter(self): + # t2i adapter + is_t2i = self.adapter_config.type == 't2i' + is_control_net = self.adapter_config.type == 'control_net' + if self.adapter_config.type == 't2i': + suffix = 't2i' + elif self.adapter_config.type == 'control_net': + suffix = 'cn' + elif self.adapter_config.type == 'clip': + suffix = 'clip' + elif self.adapter_config.type == 'reference': + suffix = 'ref' + elif self.adapter_config.type.startswith('ip'): + suffix = 'ip' + else: + suffix = 'adapter' + adapter_name = self.name + if self.network_config is not None: + adapter_name = f"{adapter_name}_{suffix}" + latest_save_path = self.get_latest_save_path(adapter_name) + + if latest_save_path is not None and not self.adapter_config.train: + # the save path is for something else since we are not training + latest_save_path = self.adapter_config.name_or_path + + dtype = get_torch_dtype(self.train_config.dtype) + if is_t2i: + # if we do not have a last save path and we have a name_or_path, + # load from that + if latest_save_path is None and self.adapter_config.name_or_path is not None: + self.adapter = T2IAdapter.from_pretrained( + self.adapter_config.name_or_path, + torch_dtype=get_torch_dtype(self.train_config.dtype), + varient="fp16", + # use_safetensors=True, + ) + else: + self.adapter = T2IAdapter( + in_channels=self.adapter_config.in_channels, + channels=self.adapter_config.channels, + num_res_blocks=self.adapter_config.num_res_blocks, + downscale_factor=self.adapter_config.downscale_factor, + adapter_type=self.adapter_config.adapter_type, + ) + elif is_control_net: + if self.adapter_config.name_or_path is None: + raise ValueError("ControlNet requires a name_or_path to load from currently") + load_from_path = self.adapter_config.name_or_path + if latest_save_path is not None: + load_from_path = latest_save_path + self.adapter = ControlNetModel.from_pretrained( + load_from_path, + torch_dtype=get_torch_dtype(self.train_config.dtype), + ) + elif self.adapter_config.type == 'clip': + self.adapter = ClipVisionAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + ) + elif self.adapter_config.type == 'reference': + self.adapter = ReferenceAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + ) + elif self.adapter_config.type.startswith('ip'): + self.adapter = IPAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + ) + if self.train_config.gradient_checkpointing: + self.adapter.enable_gradient_checkpointing() + else: + self.adapter = CustomAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + train_config=self.train_config, + ) + self.adapter.to(self.device_torch, dtype=dtype) + if latest_save_path is not None and not is_control_net: + # load adapter from path + print_acc(f"Loading adapter from {latest_save_path}") + if is_t2i: + loaded_state_dict = load_t2i_model( + latest_save_path, + self.device, + dtype=dtype + ) + self.adapter.load_state_dict(loaded_state_dict) + elif self.adapter_config.type.startswith('ip'): + # ip adapter + loaded_state_dict = load_ip_adapter_model( + latest_save_path, + self.device, + dtype=dtype, + direct_load=self.adapter_config.train_only_image_encoder + ) + self.adapter.load_state_dict(loaded_state_dict) + else: + # custom adapter + loaded_state_dict = load_custom_adapter_model( + latest_save_path, + self.device, + dtype=dtype + ) + self.adapter.load_state_dict(loaded_state_dict) + if latest_save_path is not None and self.adapter_config.train: + self.load_training_state_from_metadata(latest_save_path) + # set trainable params + self.sd.adapter = self.adapter + + def run(self): + # torch.autograd.set_detect_anomaly(True) + # run base process run + BaseTrainProcess.run(self) + params = [] + + ### HOOK ### + self.hook_before_model_load() + model_config_to_load = copy.deepcopy(self.model_config) + + if self.is_fine_tuning or self.train_config.merge_network_on_save: + # get the latest checkpoint + # check to see if we have a latest save + latest_save_path = self.get_latest_save_path() + + if latest_save_path is not None: + print_acc(f"#### IMPORTANT RESUMING FROM {latest_save_path} ####") + model_config_to_load.name_or_path = latest_save_path + self.load_training_state_from_metadata(latest_save_path) + + ModelClass = get_model_class(self.model_config) + # if the model class has get_train_scheduler static method + if hasattr(ModelClass, 'get_train_scheduler'): + sampler = ModelClass.get_train_scheduler() + else: + # get the noise scheduler + arch = 'sd' + if self.model_config.is_pixart: + arch = 'pixart' + if self.model_config.is_flux: + arch = 'flux' + if self.model_config.is_lumina2: + arch = 'lumina2' + sampler = get_sampler( + self.train_config.noise_scheduler, + { + "prediction_type": "v_prediction" if self.model_config.is_v_pred else "epsilon", + }, + arch=arch, + ) + + if self.train_config.train_refiner and self.model_config.refiner_name_or_path is not None and self.network_config is None: + previous_refiner_save = self.get_latest_save_path(self.job.name + '_refiner') + if previous_refiner_save is not None: + model_config_to_load.refiner_name_or_path = previous_refiner_save + self.load_training_state_from_metadata(previous_refiner_save) + + self.sd = ModelClass( + # todo handle single gpu and multi gpu here + # device=self.device, + device=self.accelerator.device, + model_config=model_config_to_load, + dtype=self.train_config.dtype, + custom_pipeline=self.custom_pipeline, + noise_scheduler=sampler, + ) + + self.hook_after_sd_init_before_load() + # run base sd process run + self.sd.load_model() + + self.sd.add_after_sample_image_hook(self.sample_step_hook) + + dtype = get_torch_dtype(self.train_config.dtype) + + # model is loaded from BaseSDProcess + unet = self.sd.unet + vae = self.sd.vae + tokenizer = self.sd.tokenizer + text_encoder = self.sd.text_encoder + noise_scheduler = self.sd.noise_scheduler + + if self.train_config.xformers: + vae.enable_xformers_memory_efficient_attention() + unet.enable_xformers_memory_efficient_attention() + if isinstance(text_encoder, list): + for te in text_encoder: + # if it has it + if hasattr(te, 'enable_xformers_memory_efficient_attention'): + te.enable_xformers_memory_efficient_attention() + + if self.train_config.attention_backend != 'native': + if hasattr(vae, 'set_attention_backend'): + vae.set_attention_backend(self.train_config.attention_backend) + if hasattr(unet, 'set_attention_backend'): + unet.set_attention_backend(self.train_config.attention_backend) + if isinstance(text_encoder, list): + for te in text_encoder: + if hasattr(te, 'set_attention_backend'): + te.set_attention_backend(self.train_config.attention_backend) + else: + if hasattr(text_encoder, 'set_attention_backend'): + text_encoder.set_attention_backend(self.train_config.attention_backend) + if self.train_config.sdp: + torch.backends.cuda.enable_math_sdp(True) + torch.backends.cuda.enable_flash_sdp(True) + torch.backends.cuda.enable_mem_efficient_sdp(True) + + # # check if we have sage and is flux + # if self.sd.is_flux: + # # try_to_activate_sage_attn() + # try: + # from sageattention import sageattn + # from toolkit.models.flux_sage_attn import FluxSageAttnProcessor2_0 + # model: FluxTransformer2DModel = self.sd.unet + # # enable sage attention on each block + # for block in model.transformer_blocks: + # processor = FluxSageAttnProcessor2_0() + # block.attn.set_processor(processor) + # for block in model.single_transformer_blocks: + # processor = FluxSageAttnProcessor2_0() + # block.attn.set_processor(processor) + + # except ImportError: + # print_acc("sage attention is not installed. Using SDP instead") + + if self.train_config.gradient_checkpointing: + # if has method enable_gradient_checkpointing + if hasattr(unet, 'enable_gradient_checkpointing'): + unet.enable_gradient_checkpointing() + elif hasattr(unet, 'gradient_checkpointing'): + unet.gradient_checkpointing = True + else: + print("Gradient checkpointing not supported on this model") + if isinstance(text_encoder, list): + for te in text_encoder: + if hasattr(te, 'enable_gradient_checkpointing'): + te.enable_gradient_checkpointing() + if hasattr(te, "gradient_checkpointing_enable"): + te.gradient_checkpointing_enable() + else: + if hasattr(text_encoder, 'enable_gradient_checkpointing'): + text_encoder.enable_gradient_checkpointing() + if hasattr(text_encoder, "gradient_checkpointing_enable"): + text_encoder.gradient_checkpointing_enable() + + if self.sd.refiner_unet is not None: + self.sd.refiner_unet.to(self.device_torch, dtype=dtype) + self.sd.refiner_unet.requires_grad_(False) + self.sd.refiner_unet.eval() + if self.train_config.xformers: + self.sd.refiner_unet.enable_xformers_memory_efficient_attention() + if self.train_config.gradient_checkpointing: + self.sd.refiner_unet.enable_gradient_checkpointing() + + if isinstance(text_encoder, list): + for te in text_encoder: + te.requires_grad_(False) + te.eval() + else: + text_encoder.requires_grad_(False) + text_encoder.eval() + unet.to(self.device_torch, dtype=dtype) + unet.requires_grad_(False) + unet.eval() + vae = vae.to(torch.device('cpu'), dtype=dtype) + vae.requires_grad_(False) + vae.eval() + if self.train_config.learnable_snr_gos: + self.snr_gos = LearnableSNRGamma( + self.sd.noise_scheduler, device=self.device_torch + ) + # check to see if previous settings exist + path_to_load = os.path.join(self.save_root, 'learnable_snr.json') + if os.path.exists(path_to_load): + with open(path_to_load, 'r') as f: + json_data = json.load(f) + if 'offset' in json_data: + # legacy + self.snr_gos.offset_2.data = torch.tensor(json_data['offset'], device=self.device_torch) + else: + self.snr_gos.offset_1.data = torch.tensor(json_data['offset_1'], device=self.device_torch) + self.snr_gos.offset_2.data = torch.tensor(json_data['offset_2'], device=self.device_torch) + self.snr_gos.scale.data = torch.tensor(json_data['scale'], device=self.device_torch) + self.snr_gos.gamma.data = torch.tensor(json_data['gamma'], device=self.device_torch) + + self.hook_after_model_load() + flush() + if not self.is_fine_tuning: + if self.network_config is not None: + # TODO should we completely switch to LycorisSpecialNetwork? + network_kwargs = self.network_config.network_kwargs + is_lycoris = False + is_lorm = self.network_config.type.lower() == 'lorm' + # default to LoCON if there are any conv layers or if it is named + NetworkClass = LoRASpecialNetwork + if self.network_config.type.lower() == 'locon' or self.network_config.type.lower() == 'lycoris': + NetworkClass = LycorisSpecialNetwork + is_lycoris = True + + if is_lorm: + network_kwargs['ignore_if_contains'] = lorm_ignore_if_contains + network_kwargs['parameter_threshold'] = lorm_parameter_threshold + network_kwargs['target_lin_modules'] = LORM_TARGET_REPLACE_MODULE + + # if is_lycoris: + # preset = PRESET['full'] + # NetworkClass.apply_preset(preset) + + if hasattr(self.sd, 'target_lora_modules'): + network_kwargs['target_lin_modules'] = self.sd.target_lora_modules + + self.network = NetworkClass( + text_encoder=text_encoder, + unet=self.sd.get_model_to_train(), + lora_dim=self.network_config.linear, + multiplier=1.0, + alpha=self.network_config.linear_alpha, + train_unet=self.train_config.train_unet, + train_text_encoder=self.train_config.train_text_encoder, + conv_lora_dim=self.network_config.conv, + conv_alpha=self.network_config.conv_alpha, + is_sdxl=self.model_config.is_xl or self.model_config.is_ssd, + is_v2=self.model_config.is_v2, + is_v3=self.model_config.is_v3, + is_pixart=self.model_config.is_pixart, + is_auraflow=self.model_config.is_auraflow, + is_flux=self.model_config.is_flux, + is_lumina2=self.model_config.is_lumina2, + is_ssd=self.model_config.is_ssd, + is_vega=self.model_config.is_vega, + dropout=self.network_config.dropout, + use_text_encoder_1=self.model_config.use_text_encoder_1, + use_text_encoder_2=self.model_config.use_text_encoder_2, + use_bias=is_lorm, + is_lorm=is_lorm, + network_config=self.network_config, + network_type=self.network_config.type, + transformer_only=self.network_config.transformer_only, + is_transformer=self.sd.is_transformer, + base_model=self.sd, + **network_kwargs + ) + + + # todo switch everything to proper mixed precision like this + self.network.force_to(self.device_torch, dtype=torch.float32) + # give network to sd so it can use it + self.sd.network = self.network + self.network._update_torch_multiplier() + + self.network.apply_to( + text_encoder, + unet, + self.train_config.train_text_encoder, + self.train_config.train_unet + ) + + # we cannot merge in if quantized or offloading. note: torchao quantized weights can + # still be force merged at save time for the merge-and-reset method (see save logic), + # but we keep can_merge_in False here so sampling never merges in/out. + if self.model_config.quantize or self.model_config.layer_offloading: + # todo find a way around this + self.network.can_merge_in = False + + if is_lorm: + self.network.is_lorm = True + # make sure it is on the right device + self.sd.unet.to(self.sd.device, dtype=dtype) + original_unet_param_count = count_parameters(self.sd.unet) + self.network.setup_lorm() + new_unet_param_count = original_unet_param_count - self.network.calculate_lorem_parameter_reduction() + + print_lorm_extract_details( + start_num_params=original_unet_param_count, + end_num_params=new_unet_param_count, + num_replaced=len(self.network.get_all_modules()), + ) + + self.network.prepare_grad_etc(text_encoder, unet) + flush() + + # LyCORIS doesnt have default_lr + config = { + 'text_encoder_lr': self.train_config.lr, + 'unet_lr': self.train_config.lr, + } + sig = inspect.signature(self.network.prepare_optimizer_params) + if 'default_lr' in sig.parameters: + config['default_lr'] = self.train_config.lr + if 'learning_rate' in sig.parameters: + config['learning_rate'] = self.train_config.lr + params_net = self.network.prepare_optimizer_params( + **config + ) + + params += params_net + + if self.train_config.gradient_checkpointing: + self.network.enable_gradient_checkpointing() + + lora_name = self.name + # need to adapt name so they are not mixed up + if self.named_lora: + lora_name = f"{lora_name}_LoRA" + + latest_save_path = self.get_latest_save_path(lora_name) + extra_weights = None + if latest_save_path is not None and not self.train_config.merge_network_on_save: + print_acc(f"#### IMPORTANT RESUMING FROM {latest_save_path} ####") + print_acc(f"Loading from {latest_save_path}") + extra_weights = self.load_weights(latest_save_path) + self.network.multiplier = 1.0 + + if self.network_config.layer_offloading: + MemoryManager.attach( + self.network, + self.device_torch + ) + + if self.embed_config is not None: + # we are doing embedding training as well + self.embedding = Embedding( + sd=self.sd, + embed_config=self.embed_config + ) + latest_save_path = self.get_latest_save_path(self.embed_config.trigger) + # load last saved weights + if latest_save_path is not None: + self.embedding.load_embedding_from_file(latest_save_path, self.device_torch) + if self.embedding.step > 1: + self.step_num = self.embedding.step + self.start_step = self.step_num + + # self.step_num = self.embedding.step + # self.start_step = self.step_num + params.append({ + 'params': list(self.embedding.get_trainable_params()), + 'lr': self.train_config.embedding_lr + }) + + flush() + + if self.decorator_config is not None: + self.decorator = Decorator( + num_tokens=self.decorator_config.num_tokens, + token_size=4096 # t5xxl hidden size for flux + ) + latest_save_path = self.get_latest_save_path() + # load last saved weights + if latest_save_path is not None: + state_dict = load_file(latest_save_path) + self.decorator.load_state_dict(state_dict) + self.load_training_state_from_metadata(latest_save_path) + + params.append({ + 'params': list(self.decorator.parameters()), + 'lr': self.train_config.lr + }) + + # give it to the sd network + self.sd.decorator = self.decorator + self.decorator.to(self.device_torch, dtype=torch.float32) + self.decorator.train() + + flush() + + if self.adapter_config is not None: + self.setup_adapter() + if self.adapter_config.train: + + if isinstance(self.adapter, IPAdapter): + # we have custom LR groups for IPAdapter + adapter_param_groups = self.adapter.get_parameter_groups(self.train_config.adapter_lr) + for group in adapter_param_groups: + params.append(group) + else: + # set trainable params + params.append({ + 'params': list(self.adapter.parameters()), + 'lr': self.train_config.adapter_lr + }) + + if self.train_config.gradient_checkpointing: + self.adapter.enable_gradient_checkpointing() + flush() + + params = self.load_additional_training_modules(params) + + else: # no network, embedding or adapter + # set the device state preset before getting params + self.sd.set_device_state(self.get_params_device_state_preset) + + # params = self.get_params() + if len(params) == 0: + # will only return savable weights and ones with grad + params = self.sd.prepare_optimizer_params( + unet=self.train_config.train_unet, + text_encoder=self.train_config.train_text_encoder, + text_encoder_lr=self.train_config.lr, + unet_lr=self.train_config.lr, + default_lr=self.train_config.lr, + refiner=self.train_config.train_refiner and self.sd.refiner_unet is not None, + refiner_lr=self.train_config.refiner_lr, + ) + # we may be using it for prompt injections + if self.adapter_config is not None and self.adapter is None: + self.setup_adapter() + flush() + + ### HOOK ### + params = self.hook_add_extra_train_params(params) + self.params = params + # self.params = [] + + # for param in params: + # if isinstance(param, dict): + # self.params += param['params'] + # else: + # self.params.append(param) + + if self.train_config.start_step is not None: + self.step_num = self.train_config.start_step + self.start_step = self.step_num + + optimizer_type = self.train_config.optimizer.lower() + + # esure params require grad + self.ensure_params_requires_grad(force=True) + optimizer = get_optimizer(self.params, optimizer_type, learning_rate=self.train_config.lr, + optimizer_params=self.train_config.optimizer_params) + self.optimizer = optimizer + + # set it to do paramiter swapping + if self.train_config.do_paramiter_swapping: + # only works for adafactor, but it should have thrown an error prior to this otherwise + self.optimizer.enable_paramiter_swapping(self.train_config.paramiter_swapping_factor) + + # check if it exists + optimizer_state_filename = f'optimizer.pt' + optimizer_state_file_path = os.path.join(self.save_root, optimizer_state_filename) + if os.path.exists(optimizer_state_file_path): + # try to load + # previous param groups + # previous_params = copy.deepcopy(optimizer.param_groups) + previous_lrs = [] + for group in optimizer.param_groups: + previous_lrs.append(group['lr']) + + load_optimizer = True + if self.network is not None: + if self.network.did_change_weights: + # do not load optimizer if the network changed, it will result in + # a double state that will oom. + load_optimizer = False + + if load_optimizer: + try: + print_acc(f"Loading optimizer state from {optimizer_state_file_path}") + optimizer_state_dict = torch.load(optimizer_state_file_path, weights_only=True) + optimizer.load_state_dict(optimizer_state_dict) + del optimizer_state_dict + flush() + except Exception as e: + print_acc(f"Failed to load optimizer state from {optimizer_state_file_path}") + print_acc(e) + + # update the optimizer LR from the params + print_acc(f"Updating optimizer LR from params") + if len(previous_lrs) > 0: + for i, group in enumerate(optimizer.param_groups): + group['lr'] = previous_lrs[i] + group['initial_lr'] = previous_lrs[i] + + # Update the learning rates if they changed + # optimizer.param_groups = previous_params + + # set up the ema now that the optimizer (and its params) are ready + self.setup_ema() + + lr_scheduler_params = self.train_config.lr_scheduler_params + + # make sure it had bare minimum + if 'max_iterations' not in lr_scheduler_params: + lr_scheduler_params['total_iters'] = self.train_config.steps + + lr_scheduler = get_lr_scheduler( + self.train_config.lr_scheduler, + optimizer, + **lr_scheduler_params + ) + self.lr_scheduler = lr_scheduler + + ### HOOk ### + self.before_dataset_load() + # load datasets if passed in the root process + if self.datasets is not None: + self.data_loader = get_dataloader_from_datasets(self.datasets, self.train_config.batch_size, self.sd) + if self.datasets_reg is not None: + self.data_loader_reg = get_dataloader_from_datasets(self.datasets_reg, self.train_config.batch_size, + self.sd) + + flush() + self.last_save_step = self.step_num + ### HOOK ### + self.hook_before_train_loop() + + # ============================================================ + # COMPILE + # + # compile: true + # -> whole-model torch.compile + # + # compile: true + # block_compile: true + # -> block-level compilation + # ============================================================ + if self.model_config.compile: + compiled_refs = [] # (block_list, index, original_block) for rollback on failure + try: + inner_unet_check = unwrap_model(self.sd.unet) + is_unet_offloaded = hasattr(inner_unet_check, '_memory_manager') + + text_encoder = getattr(self.sd, "text_encoder", None) + text_encoder_check = unwrap_model(text_encoder) if text_encoder is not None else None + is_te_offloaded = hasattr(text_encoder_check, '_memory_manager') if text_encoder_check is not None else False + + is_unet_quantized = getattr(self.model_config, 'quantize', False) + is_quantized = is_unet_quantized or getattr(self.model_config, 'quantize_te', False) + + if not is_unet_offloaded: + self.sd.unet.to(self.device_torch) + + cache_size_limit = getattr(self.model_config, 'cache_size_limit', None) + user_set_cache_limit = cache_size_limit is not None + if user_set_cache_limit: + torch._dynamo.config.cache_size_limit = cache_size_limit + torch._dynamo.config.suppress_errors = False + + compile_mode = getattr(self.model_config, 'compile_mode', 'default') + compile_dynamic = getattr(self.model_config, 'compile_dynamic', True) + compile_fullgraph = getattr(self.model_config, 'compile_fullgraph', False) + block_compile = getattr(self.model_config, 'block_compile', False) + + # quantized + offloaded unet is incompatible with fullgraph; force it off + if is_unet_quantized and is_unet_offloaded and compile_fullgraph: + print_acc( + "Quantized offloaded Transformer detected: fullgraph=True is incompatible, " + "switching to fullgraph=False." + ) + compile_fullgraph = False + + cache_info = "" + # ==================================================== + # BLOCK COMPILE + # ==================================================== + if block_compile: + BLOCK_LIST_ATTRS = self.sd.get_transformer_block_names() + + if BLOCK_LIST_ATTRS is None or len(BLOCK_LIST_ATTRS) == 0: + BLOCK_LIST_ATTRS = [ + 'layers', + 'transformer_blocks', + 'single_transformer_blocks', + 'double_stream_blocks', + 'single_stream_blocks', + 'double_blocks', + 'single_blocks', + 'blocks', + ] + inner_unet = unwrap_model(self.sd.unet) + + compiled_block_count = 0 + + for attr_name in BLOCK_LIST_ATTRS: + # attr_name may be a dotted path for models that nest their + # blocks (e.g. hidream_o1's "model.language_model.layers"). + block_list = inner_unet + for part in attr_name.split('.'): + block_list = getattr(block_list, part, None) + if block_list is None: + break + + if block_list is None: + continue + + if not hasattr(block_list, '__len__'): + continue + + for i, block in enumerate(block_list): + if not isinstance(block, torch.nn.Module): + continue + + if hasattr(block, '_hf_hook'): + continue + + compiled_refs.append((block_list, i, block)) + block_list[i] = torch.compile( + block, + mode=compile_mode, + dynamic=compile_dynamic, + fullgraph=compile_fullgraph, + ) + compiled_block_count += 1 + + if compiled_block_count > 0: + if user_set_cache_limit: + auto_cache_limit = max(cache_size_limit, compiled_block_count * 2) + if auto_cache_limit != cache_size_limit: + torch._dynamo.config.cache_size_limit = auto_cache_limit + cache_info = f", cache_size_limit={auto_cache_limit} (auto)" + else: + cache_info = f", cache_size_limit={cache_size_limit}" + else: + auto_cache_limit = compiled_block_count * 2 + torch._dynamo.config.cache_size_limit = auto_cache_limit + cache_info = f", cache_size_limit={auto_cache_limit} (auto)" + print_acc( + f"Compiled {compiled_block_count} transformer block(s) " + f"with torch.compile (mode='{compile_mode}', fullgraph={compile_fullgraph}, dynamic={compile_dynamic}{cache_info})." + ) + print_acc("The first forward pass will be slow during compile. This is normal.") + print_acc("If you are experiencing issues, disable block_compile.") + else: + print_acc( + f"No individual transformer blocks found; " + f"falling back to whole-model torch.compile " + f"(mode='{compile_mode}', fullgraph={compile_fullgraph}, dynamic={compile_dynamic}{cache_info})." + ) + print_acc("The first forward pass will hang for a while. This is normal.") + + if is_unet_quantized and not is_unet_offloaded and compile_fullgraph: + print_acc( + "Quantized model detected: fullgraph=True is incompatible " + "for whole-model compile, switching to fullgraph=False." + ) + compile_fullgraph = False + + if compile_mode == 'default': + self.sd.unet = torch.compile( + self.sd.unet, + dynamic=compile_dynamic, + fullgraph=compile_fullgraph, + ) + else: + self.sd.unet = torch.compile( + self.sd.unet, + mode=compile_mode, + dynamic=compile_dynamic, + fullgraph=compile_fullgraph, + ) + + # ==================================================== + # WHOLE MODEL COMPILE + # ==================================================== + else: + print_acc("Compiling model with torch.compile (whole-model compile).") + print_acc("The first forward pass will hang for a while. This is normal.") + + print_acc( + f"Using torch.compile settings: " + f"mode={compile_mode}, " + f"dynamic={compile_dynamic}, " + f"fullgraph={compile_fullgraph}{cache_info}" + ) + + if compile_fullgraph: + print_acc( + "fullgraph=True is incompatible with whole-model compile, " + "switching to fullgraph=False." + ) + compile_fullgraph = False + + if compile_mode == 'default': + self.sd.unet = torch.compile( + self.sd.unet, + dynamic=compile_dynamic, + fullgraph=compile_fullgraph, + ) + else: + self.sd.unet = torch.compile( + self.sd.unet, + mode=compile_mode, + dynamic=compile_dynamic, + fullgraph=compile_fullgraph, + ) + + if not is_unet_offloaded: + # once compiled, dynamo guards hold weakrefs to the params; + # .to() on quantized params requires swap_tensors, which fails + # on tensors with weakrefs. The model stays on device anyway, + # so make .to() a no-op. + unet_module = self.sd.unet + unet_module.to = lambda *args, **kwargs: unet_module + + except Exception as e: + # undo any block-level compiles that happened before the failure, + # so "continuing without compilation" is actually true + if len(compiled_refs) > 0: + for block_list, i, original_block in compiled_refs: + block_list[i] = original_block + + if 'triton' in str(e).lower(): + print_acc("WARNING: compile is disabled.") + print_acc("Triton is not available or not working on this system.") + print_acc("Install a working 'triton' package to use compile.") + print_acc("Continuing without compilation.") + else: + print_acc(f"Failed to compile model: {e}") + print_acc("Continuing without compilation") + + if self.has_first_sample_requested and self.step_num <= 1 and not self.train_config.disable_sampling: + print_acc("Generating first sample from first sample config") + self.sample(0, is_first=True) + + # sample first + if self.train_config.skip_first_sample or self.train_config.disable_sampling: + print_acc("Skipping first sample due to config setting") + elif self.step_num <= 1 or self.train_config.force_first_sample: + print_acc("Generating baseline samples before training") + self.sample(self.step_num) + + if self.accelerator.is_local_main_process: + self.progress_bar = ToolkitProgressBar( + total=self.train_config.steps, + desc=self.job.name, + leave=True, + initial=self.step_num, + iterable=range(0, self.train_config.steps), + ) + self.progress_bar.pause() + else: + self.progress_bar = None + + if self.data_loader is not None: + dataloader = self.data_loader + dataloader_iterator = iter(dataloader) + else: + dataloader = None + dataloader_iterator = None + + if self.data_loader_reg is not None: + dataloader_reg = self.data_loader_reg + dataloader_iterator_reg = iter(dataloader_reg) + else: + dataloader_reg = None + dataloader_iterator_reg = None + + # zero any gradients + optimizer.zero_grad() + + self.lr_scheduler.step(self.step_num) + + self.sd.set_device_state(self.train_device_state_preset) + flush() + # self.step_num = 0 + + # print_acc(f"Compiling Model") + # torch.compile(self.sd.unet, dynamic=True) + + # make sure all params require grad + self.ensure_params_requires_grad(force=True) + + + ################################################################### + # TRAIN LOOP + ################################################################### + + + start_step_num = self.step_num + did_first_flush = False + flush_next = False + for step in range(start_step_num, self.train_config.steps): + if self.train_config.do_paramiter_swapping: + self.optimizer.optimizer.swap_paramiters() + self.timer.start('train_loop') + if flush_next: + flush() + flush_next = False + if self.train_config.do_random_cfg: + self.train_config.do_cfg = True + self.train_config.cfg_scale = value_map(random.random(), 0, 1, 1.0, self.train_config.max_cfg_scale) + self.step_num = step + # default to true so various things can turn it off + self.is_grad_accumulation_step = True + if self.train_config.free_u: + self.sd.pipeline.enable_freeu(s1=0.9, s2=0.2, b1=1.1, b2=1.2) + if self.progress_bar is not None: + self.progress_bar.unpause() + with torch.no_grad(): + # if is even step and we have a reg dataset, use that + # todo improve this logic to send one of each through if we can buckets and batch size might be an issue + is_reg_step = False + is_save_step = self.save_config.save_every and self.step_num % self.save_config.save_every == 0 + is_sample_step = self.sample_config.sample_every and self.step_num % self.sample_config.sample_every == 0 + if self.train_config.disable_sampling: + is_sample_step = False + + batch_list = [] + + for b in range(self.train_config.gradient_accumulation): + # keep track to alternate on an accumulation step for reg + batch_step = step + # don't do a reg step on sample or save steps as we dont want to normalize on those + if batch_step % 2 == 0 and dataloader_reg is not None and not is_save_step and not is_sample_step: + try: + with self.timer('get_batch:reg'): + batch = next(dataloader_iterator_reg) + except StopIteration: + with self.timer('reset_batch:reg'): + # hit the end of an epoch, reset + if self.progress_bar is not None: + self.progress_bar.pause() + dataloader_iterator_reg = iter(dataloader_reg) + trigger_dataloader_setup_epoch(dataloader_reg) + + with self.timer('get_batch:reg'): + batch = next(dataloader_iterator_reg) + if self.progress_bar is not None: + self.progress_bar.unpause() + is_reg_step = True + elif dataloader is not None: + try: + with self.timer('get_batch'): + batch = next(dataloader_iterator) + except StopIteration: + with self.timer('reset_batch'): + # hit the end of an epoch, reset + if self.progress_bar is not None: + self.progress_bar.pause() + dataloader_iterator = iter(dataloader) + trigger_dataloader_setup_epoch(dataloader) + self.epoch_num += 1 + if self.train_config.gradient_accumulation_steps == -1: + # if we are accumulating for an entire epoch, trigger a step + self.is_grad_accumulation_step = False + self.grad_accumulation_step = 0 + with self.timer('get_batch'): + batch = next(dataloader_iterator) + if self.progress_bar is not None: + self.progress_bar.unpause() + else: + batch = None + batch_list.append(batch) + batch_step += 1 + + # setup accumulation + if self.train_config.gradient_accumulation_steps == -1: + # epoch is handling the accumulation, dont touch it + pass + else: + # determine if we are accumulating or not + # since optimizer step happens in the loop, we trigger it a step early + # since we cannot reprocess it before them + optimizer_step_at = self.train_config.gradient_accumulation_steps + is_optimizer_step = self.grad_accumulation_step >= optimizer_step_at + self.is_grad_accumulation_step = not is_optimizer_step + if is_optimizer_step: + self.grad_accumulation_step = 0 + + # flush() + ### HOOK ### + if self.torch_profiler is not None: + self.torch_profiler.start() + did_oom = False + loss_dict = None + try: + with self.accelerator.accumulate(self.modules_being_trained): + loss_dict = self.hook_train_loop(batch_list) + except torch.cuda.OutOfMemoryError: + did_oom = True + except RuntimeError as e: + if "CUDA out of memory" in str(e): + did_oom = True + else: + raise # not an OOM; surface real errors + if did_oom: + self.num_consecutive_oom += 1 + if self.num_consecutive_oom > 3: + raise RuntimeError("OOM during training step 3 times in a row, aborting training") + optimizer.zero_grad(set_to_none=True) + flush() + torch.cuda.ipc_collect() + # skip this step and keep going + print_acc("") + print_acc("################################################") + print_acc(f"# OOM during training step, skipping batch {self.num_consecutive_oom}/3 #") + print_acc("################################################") + print_acc("") + else: + self.num_consecutive_oom = 0 + if self.torch_profiler is not None: + torch.cuda.synchronize() # Make sure all CUDA ops are done + self.torch_profiler.stop() + + print("\n==== Profile Results ====") + print(self.torch_profiler.key_averages().table(sort_by="cpu_time_total", row_limit=1000)) + self.timer.stop('train_loop') + if not did_first_flush: + flush() + did_first_flush = True + # flush() + # setup the networks to gradient checkpointing and everything works + if self.adapter is not None and isinstance(self.adapter, ReferenceAdapter): + self.adapter.clear_memory() + + with torch.no_grad(): + # torch.cuda.empty_cache() + # if optimizer has get_lrs method, then use it + learning_rate = 0.0 + if not did_oom and loss_dict is not None: + if hasattr(optimizer, 'get_avg_learning_rate'): + learning_rate = optimizer.get_avg_learning_rate() + elif hasattr(optimizer, 'get_learning_rates'): + learning_rate = optimizer.get_learning_rates()[0] + elif self.train_config.optimizer.lower().startswith('dadaptation') or \ + self.train_config.optimizer.lower().startswith('prodigy'): + learning_rate = ( + optimizer.param_groups[0]["d"] * + optimizer.param_groups[0]["lr"] + ) + else: + learning_rate = optimizer.param_groups[0]['lr'] + + prog_bar_string = f"lr: {learning_rate:.1e}" + for key, value in loss_dict.items(): + prog_bar_string += f" {key}: {value:.3e}" + + if self.progress_bar is not None: + self.progress_bar.set_postfix_str(prog_bar_string) + + # if the batch is a DataLoaderBatchDTO, then we need to clean it up + if isinstance(batch, DataLoaderBatchDTO): + with self.timer('batch_cleanup'): + batch.cleanup() + + # don't do on first step + if self.step_num != self.start_step: + if is_sample_step or is_save_step: + self.accelerator.wait_for_everyone() + + if is_save_step: + self.accelerator + # print above the progress bar + if self.progress_bar is not None: + self.progress_bar.pause() + print_acc(f"\nSaving at step {self.step_num}") + self.save(self.step_num) + self.ensure_params_requires_grad() + # clear any grads + optimizer.zero_grad() + flush() + flush_next = True + if self.progress_bar is not None: + self.progress_bar.unpause() + + if is_sample_step: + if self.progress_bar is not None: + self.progress_bar.pause() + flush() + # print above the progress bar + if self.train_config.free_u: + self.sd.pipeline.disable_freeu() + self.sample(self.step_num) + if self.train_config.unload_text_encoder: + # make sure the text encoder is unloaded + self.sd.text_encoder_to('cpu') + flush() + + self.ensure_params_requires_grad() + if self.progress_bar is not None: + self.progress_bar.unpause() + + if self.logging_config.log_every and self.step_num % self.logging_config.log_every == 0: + if self.progress_bar is not None: + self.progress_bar.pause() + with self.timer('log_to_tensorboard'): + # log to tensorboard + if self.accelerator.is_main_process: + if self.writer is not None: + if loss_dict is not None: + for key, value in loss_dict.items(): + self.writer.add_scalar(f"{key}", value, self.step_num) + self.writer.add_scalar(f"lr", learning_rate, self.step_num) + if self.progress_bar is not None: + self.progress_bar.unpause() + + if self.accelerator.is_main_process: + # log to logger + self.logger.log({ + 'learning_rate': learning_rate, + }) + if loss_dict is not None: + for key, value in loss_dict.items(): + self.logger.log({ + f'loss/{key}': value, + }) + if self.additional_logs is not None: + for key, value in self.additional_logs.items(): + self.logger.log({ + key: value, + }) + self.additional_logs = {} + elif self.logging_config.log_every is None: + if self.accelerator.is_main_process: + # log every step + self.logger.log({ + 'learning_rate': learning_rate, + }) + for key, value in loss_dict.items(): + self.logger.log({ + f'loss/{key}': value, + }) + if self.additional_logs is not None: + for key, value in self.additional_logs.items(): + self.logger.log({ + key: value, + }) + self.additional_logs = {} + + + if self.performance_log_every > 0 and self.step_num % self.performance_log_every == 0: + if self.progress_bar is not None: + self.progress_bar.pause() + # print the timers and clear them + self.timer.print() + self.timer.reset() + if self.progress_bar is not None: + self.progress_bar.unpause() + + # commit log + if self.accelerator.is_main_process: + with self.timer('commit_logger'): + self.logger.commit(step=self.step_num) + + # sets progress bar to match out step + if self.progress_bar is not None: + self.progress_bar.update(step - self.progress_bar.n) + + ############################# + # End of step + ############################# + + # update various steps + self.step_num = step + 1 + self.grad_accumulation_step += 1 + self.end_step_hook() + + + ################################################################### + ## END TRAIN LOOP + ################################################################### + self.accelerator.wait_for_everyone() + if self.progress_bar is not None: + self.progress_bar.close() + if self.train_config.free_u: + self.sd.pipeline.disable_freeu() + if self.accelerator.is_main_process: + self.save() + if not self.train_config.disable_sampling: + self.sample(self.step_num) + self.logger.commit(step=self.step_num) + print_acc("") + if self.accelerator.is_main_process: + self.logger.finish() + self.accelerator.end_training() + + if self.accelerator.is_main_process: + # push to hub + if self.save_config.push_to_hub: + if("HF_TOKEN" not in os.environ): + interpreter_login(new_session=False, write_permission=True) + self.push_to_hub( + repo_id=self.save_config.hf_repo_id, + private=self.save_config.hf_private + ) + del ( + self.sd, + unet, + noise_scheduler, + optimizer, + self.network, + tokenizer, + text_encoder, + ) + + flush() + self.done_hook() + + def push_to_hub( + self, + repo_id: str, + private: bool = False, + ): + if not self.accelerator.is_main_process: + return + readme_content = self._generate_readme(repo_id) + readme_path = os.path.join(self.save_root, "README.md") + with open(readme_path, "w", encoding="utf-8") as f: + f.write(readme_content) + + api = HfApi() + + api.create_repo( + repo_id, + private=private, + exist_ok=True + ) + + api.upload_folder( + repo_id=repo_id, + folder_path=self.save_root, + ignore_patterns=["*.yaml", "*.pt"], + repo_type="model", + ) + + + def _generate_readme(self, repo_id: str) -> str: + """Generates the content of the README.md file.""" + + # Gather model info + base_model = self.model_config.name_or_path + instance_prompt = self.trigger_word if hasattr(self, "trigger_word") else None + if base_model == "black-forest-labs/FLUX.1-schnell": + license = "apache-2.0" + elif base_model == "black-forest-labs/FLUX.1-dev": + license = "other" + license_name = "flux-1-dev-non-commercial-license" + license_link = "https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md" + else: + license = "creativeml-openrail-m" + tags = [ + "text-to-image", + ] + if self.model_config.is_xl: + tags.append("stable-diffusion-xl") + if self.model_config.is_flux: + tags.append("flux") + if self.model_config.is_lumina2: + tags.append("lumina2") + if self.model_config.is_v3: + tags.append("sd3") + if self.network_config: + tags.extend( + [ + "lora", + "diffusers", + "template:sd-lora", + "ai-toolkit", + ] + ) + + # Generate the widget section + widgets = [] + sample_image_paths = [] + samples_dir = os.path.join(self.save_root, "samples") + if os.path.isdir(samples_dir): + for filename in os.listdir(samples_dir): + #The filenames are structured as 1724085406830__00000500_0.jpg + #So here we capture the 2nd part (steps) and 3rd (index the matches the prompt) + match = re.search(r"__(\d+)_(\d+)\.jpg$", filename) + if match: + steps, index = int(match.group(1)), int(match.group(2)) + #Here we only care about uploading the latest samples, the match with the # of steps + if steps == self.train_config.steps: + sample_image_paths.append((index, f"samples/{filename}")) + + # Sort by numeric index + sample_image_paths.sort(key=lambda x: x[0]) + + # Create widgets matching prompt with the index + for i, prompt in enumerate(self.sample_config.prompts): + if i < len(sample_image_paths): + # Associate prompts with sample image paths based on the extracted index + _, image_path = sample_image_paths[i] + widgets.append( + { + "text": prompt, + "output": { + "url": image_path + }, + } + ) + dtype = "torch.bfloat16" if self.model_config.is_flux else "torch.float16" + # Construct the README content + readme_content = f"""--- +tags: +{yaml.dump(tags, indent=4).strip()} +{"widget:" if os.path.isdir(samples_dir) else ""} +{yaml.dump(widgets, indent=4).strip() if widgets else ""} +base_model: {base_model} +{"instance_prompt: " + instance_prompt if instance_prompt else ""} +license: {license} +{'license_name: ' + license_name if license == "other" else ""} +{'license_link: ' + license_link if license == "other" else ""} +--- + +# {self.job.name} +Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) +
+
+
+ Dashboard
+
+
+
+
+ Queues
+
+ View All
+
+
+
+ );
+ }, [status, imgList.length]);
+
+ return (
+ <>
+ {/* Fixed top bar */}
+ {icon}
+ {text}
+{subtitle}
+
+
+
+
+
+
+ + Dataset: + {datasetName} +
+
+
+
+
+ setCaptionExt(value)}
+ options={[
+ { value: 'txt', label: 'txt' },
+ { value: 'json', label: 'json' },
+ { value: 'caption', label: 'caption' },
+ ]}
+ />
+
+
+
+
+ Datasets
+
+
+
+
+
+
+
+
+
+
+
+
+ {job && (
+ {title}
+Loading...
} + {status === 'error' && job == null &&Error fetching job
} + {job && ( + <> + {pages.map(page => { + const Component = page.component; + return page.value === pageKey ?
+ {pages.map(page => {
+ if (page.jobTypes && !page.jobTypes.includes(jobType)) {
+ return null;
+ }
+ if (page.value === 'plugin' && !hasPlugin) {
+ return null;
+ }
+ return (
+
+ );
+ })}
+ {page?.menuItem && (
+ <>
+
+
+
+ );
+}
diff --git a/ai-toolkit/ui/src/app/jobs/new/SimpleJob.tsx b/ai-toolkit/ui/src/app/jobs/new/SimpleJob.tsx
new file mode 100644
index 0000000000000000000000000000000000000000..5f9d9bc15a0eb803540ce95ad319fc5e6b76c4fa
--- /dev/null
+++ b/ai-toolkit/ui/src/app/jobs/new/SimpleJob.tsx
@@ -0,0 +1,1643 @@
+'use client';
+import { useMemo } from 'react';
+import {
+ modelArchs,
+ ModelArch,
+ groupedModelOptions,
+ quantizationOptions,
+ defaultQtype,
+ jobTypeOptions,
+ SampleTags,
+} from './options';
+import { defaultCompileOptions, defaultDatasetConfig } from './jobConfig';
+import { GroupedSelectOption, JobConfig, SelectOption } from '@/types';
+import { objectCopy, tagsToObj, objToTags } from '@/utils/basic';
+import {
+ TextInput,
+ TextAreaInput,
+ SelectInput,
+ Checkbox,
+ FormGroup,
+ NumberInput,
+ SliderInput,
+ CreatableSelectInput,
+} from '@/components/formInputs';
+import Card from '@/components/Card';
+import { X, Copy, Wand2, SquareDashed } from 'lucide-react';
+import { openUpsamplePromptsModal, toAspectRatio } from '@/components/UpsamplePromptsModal';
+import { openPromptBoxEditor } from '@/components/PromptBoxEditorModal';
+import AddSingleImageModal, { openAddImageModal } from '@/components/AddSingleImageModal';
+import SampleControlImage from '@/components/SampleControlImage';
+import { FlipHorizontal2, FlipVertical2 } from 'lucide-react';
+import { handleModelArchChange } from './utils';
+import { IoFlaskSharp } from 'react-icons/io5';
+import { isMac } from '@/helpers/basic';
+
+type Props = {
+ jobConfig: JobConfig;
+ setJobConfig: (value: any, key: string) => void;
+ status: 'idle' | 'saving' | 'success' | 'error';
+ handleSubmit: (event: React.FormEvent
+
+
+
+
+
+ {showAdvancedView && (
+ <>
+ + {runId ? 'Edit Training Job' : 'New Training Job'} +
+
+ setGpuIDs(value)}
+ options={gpuList.map((gpu: any) => ({ value: `${gpu.index}`, label: `GPU #${gpu.index}` }))}
+ />
+
+
+
+
+
+
+
+ )}
+ {!showAdvancedView && (
+ <>
+
+ {
+ // undo current job type changes
+ const currentOption = jobTypeOptions.find(
+ option => option.value === jobConfig?.config.process[0].type,
+ );
+ if (currentOption && currentOption.onDeactivate) {
+ setJobConfig(currentOption.onDeactivate(objectCopy(jobConfig)));
+ }
+ const option = jobTypeOptions.find(option => option.value === value);
+ if (option) {
+ if (option.onActivate) {
+ setJobConfig(option.onActivate(objectCopy(jobConfig)));
+ }
+ jobTypeOptions.forEach(opt => {
+ if (opt.value !== option.value && opt.onDeactivate) {
+ setJobConfig(opt.onDeactivate(objectCopy(jobConfig)));
+ }
+ });
+ }
+ setJobConfig(value, 'config.process[0].type');
+ }}
+ options={jobTypeOptions}
+ />
+
+
+
+ )}
+
+
+
+
+
+
+
+
+ {
+ try {
+ parsed.config.process[0].sqlite_db_path = './aitk_db.db';
+ parsed.config.process[0].training_folder = settings.TRAINING_FOLDER;
+ parsed.config.process[0].device = 'cuda';
+ parsed.config.process[0].performance_log_every = 10;
+ } catch (e) {
+ console.warn(e);
+ }
+ return migrateJobConfig(parsed);
+ }}
+ />
+
+ ) : (
+
+
+
+ Queue
+
+
+ + New Job
+ New Training Job
+
+
+
+
+ {children}
+
+
+
+
+
+ Settings
+
+
+ );
+}
diff --git a/ai-toolkit/ui/src/components/AddImagesModal.tsx b/ai-toolkit/ui/src/components/AddImagesModal.tsx
new file mode 100644
index 0000000000000000000000000000000000000000..a33e5d1b898ac2aecfd89804304609ea300dfcd7
--- /dev/null
+++ b/ai-toolkit/ui/src/components/AddImagesModal.tsx
@@ -0,0 +1,383 @@
+'use client';
+import { createGlobalState } from 'react-global-hooks';
+import { Dialog, DialogBackdrop, DialogPanel, DialogTitle } from '@headlessui/react';
+import { FaUpload, FaTimesCircle, FaSpinner } from 'react-icons/fa';
+import { useCallback, useEffect, useMemo, useRef, useState } from 'react';
+import { useDropzone } from 'react-dropzone';
+import { apiClient } from '@/utils/api';
+
+export interface AddImagesModalState {
+ datasetName: string;
+ onComplete?: () => void;
+ openedByDrag?: boolean;
+}
+
+export const addImagesModalState = createGlobalState
+
+ -
+ {jobs.map(job => {
+ let totalSteps: number | undefined;
+ try {
+ totalSteps = getTotalSteps(job);
+ } catch {
+ totalSteps = undefined;
+ }
+ const pct = totalSteps ? Math.min(100, (job.step / totalSteps) * 100) : 0;
+ const isRunning = job.status === 'running' || job.status === 'stopping';
+
+ let label = job.name;
+ let href = `/jobs/${job.id}`;
+ if (job.job_type === 'caption') {
+ const splits = (job.job_ref ?? '').split(/[/\\]/);
+ label = splits[splits.length - 1] || job.name;
+ href = `/datasets/${label}`;
+ }
+
+ let statusColor = 'text-gray-400';
+ if (job.status === 'running') statusColor = 'text-blue-400';
+ if (job.status === 'queued') statusColor = 'text-yellow-400';
+ if (job.status === 'stopping') statusColor = 'text-orange-400';
+
+ return (
+
-
+
+ + {isRunning &&+ {totalSteps ? ( +
} + {label} + ++ ) : ( ++ +++ {job.info || job.status} + + {job.step} / {totalSteps} + ++{job.info || job.status}+ )} + +
+ );
+ })}
+
+
+ );
+}
+
+function FileRow({ entry }: { entry: FileEntry }) {
+ return (
+
+
+
+ {visibleEntries.map(entry => (
+
+
+
+ {entry.status === 'error' &&
+ );
+}
diff --git a/ai-toolkit/ui/src/components/AddSingleImageModal.tsx b/ai-toolkit/ui/src/components/AddSingleImageModal.tsx
new file mode 100644
index 0000000000000000000000000000000000000000..ba32ef9dff916b5f6e605909f5d328dfce49783a
--- /dev/null
+++ b/ai-toolkit/ui/src/components/AddSingleImageModal.tsx
@@ -0,0 +1,141 @@
+'use client';
+import { createGlobalState } from 'react-global-hooks';
+import { Dialog, DialogBackdrop, DialogPanel, DialogTitle } from '@headlessui/react';
+import { FaUpload } from 'react-icons/fa';
+import { useCallback, useState } from 'react';
+import { useDropzone } from 'react-dropzone';
+import { apiClient } from '@/utils/api';
+
+export interface AddSingleImageModalState {
+
+ onComplete?: (imagePath: string|null) => void;
+}
+
+export const addSingleImageModalState = createGlobalState
+ {hasError && (
+
+ )}
+
+ );
+}
diff --git a/ai-toolkit/ui/src/components/AudioPlayer.tsx b/ai-toolkit/ui/src/components/AudioPlayer.tsx
new file mode 100644
index 0000000000000000000000000000000000000000..93f1a58892ae8903a8ae21a21e895606e9fb0784
--- /dev/null
+++ b/ai-toolkit/ui/src/components/AudioPlayer.tsx
@@ -0,0 +1,563 @@
+'use client';
+
+import React, { useEffect, useMemo, useRef, useState } from 'react';
+import { apiClient } from '@/utils/api';
+
+type AudioPlayerProps = {
+ src: string;
+
+ /** Fallbacks (used only if meta missing) */
+ title?: string;
+ subtitle?: string;
+
+ /** Optional: default background image if no embedded album art is found */
+ defaultAlbumArtUrl?: string;
+
+ className?: string;
+ autoPlay?: boolean;
+ onPlay?: () => void;
+ onPause?: () => void;
+};
+
+function clamp(n: number, a: number, b: number) {
+ return Math.min(b, Math.max(a, n));
+}
+function fmtTime(sec: number) {
+ if (!isFinite(sec) || sec < 0) return '0:00';
+ const s = Math.floor(sec % 60);
+ const m = Math.floor(sec / 60);
+ return `${m}:${String(s).padStart(2, '0')}`;
+}
+
+/**
+ * Global “only one plays at a time” channel.
+ */
+const AUDIO_EXCLUSIVE_EVENT = 'app:exclusive-audio-play';
+type ExclusivePlayDetail = { token: string };
+function broadcastExclusivePlay(token: string) {
+ window.dispatchEvent(new CustomEvent