---
license: apache-2.0
language:
- en
library_name: pytorch
pipeline_tag: text-generation
tags:
- instruct
- sft
- transformer
- PolyGLU
- activation-routing
- math
- research
- from-scratch
base_model: tylerxdurden/PolyChromaticLM-1.0-base-0.6B
model-index:
- name: PolyChromaticLM-1.0-instruct-0.6B
results:
- task:
type: multiple-choice
name: HellaSwag
dataset:
name: HellaSwag
type: hellaswag
metrics:
- type: acc_norm
value: 27.84
name: Normalized Accuracy
- task:
type: multiple-choice
name: ARC-Easy
dataset:
name: ARC-Easy
type: ai2_arc
config: ARC-Easy
metrics:
- type: acc_norm
value: 36.11
name: Normalized Accuracy
- task:
type: multiple-choice
name: ARC-Challenge
dataset:
name: ARC-Challenge
type: ai2_arc
config: ARC-Challenge
metrics:
- type: acc_norm
value: 24.15
name: Normalized Accuracy
- task:
type: multiple-choice
name: PIQA
dataset:
name: PIQA
type: piqa
metrics:
- type: acc_norm
value: 54.52
name: Normalized Accuracy
- task:
type: multiple-choice
name: WinoGrande
dataset:
name: WinoGrande
type: winogrande
metrics:
- type: acc
value: 52.72
name: Accuracy
- task:
type: multiple-choice
name: BoolQ
dataset:
name: BoolQ
type: boolq
metrics:
- type: acc
value: 55.63
name: Accuracy
- task:
type: multiple-choice
name: SciQ
dataset:
name: SciQ
type: sciq
metrics:
- type: acc_norm
value: 52.70
name: Normalized Accuracy
- task:
type: multiple-choice
name: MMLU-STEM
dataset:
name: MMLU-STEM
type: mmlu
config: stem
metrics:
- type: acc
value: 28.42
name: Accuracy (5-shot)
---
# PolyChromaticLM 1.0 Instruct (0.6B)
**A 597M-parameter transformer with biologically-inspired activation routing, fine-tuned for mathematical reasoning**
*SFT on ~347K math problems from Nemotron-Math-v2, with chain-of-thought solutions in ChatML format.*
[](https://arxiv.org/)
[](https://github.com/danielxmed/PolyGLU)
[](https://www.apache.org/licenses/LICENSE-2.0)
[](https://huggingface.co/tylerxdurden/PolyChromaticLM-1.0-base-0.6B)
---
## Overview
This is the **SFT (instruction-tuned) version** of [PolyChromaticLM-1.0-base-0.6B](https://huggingface.co/tylerxdurden/PolyChromaticLM-1.0-base-0.6B), fine-tuned on mathematical problem-solving data with chain-of-thought reasoning in ChatML format.
The core innovation is **PolyGLU** (Polychromatic Gated Linear Unit) — a drop-in SwiGLU replacement that implements **state-conditional activation routing**. Each FFN neuron dynamically selects among K=4 activation functions (ReLU, Tanh, SiLU, GELU) via a differentiable Gumbel-Softmax mechanism.
**Author**: Daniel Nobrega (independent research)
### Key SFT Results
- **Training loss**: 1.77 → 0.91 (48.7% reduction over 1 epoch)
- **Routing entropy: 1.386 (maximum) throughout all 13,067 SFT steps** — the PolyGLU routing architecture is fully robust to fine-tuning
- **MMLU-STEM improved by +3.14 pp** after SFT, with large gains on quantitative subtasks (High School Statistics +20.84 pp, College Mathematics +11.00 pp)
- Moderate forgetting on general benchmarks (mean -2.89 pp across 10 tasks) — 9/10 benchmarks remain above random
---
## SFT Training
| | |
|---|---|
| **Base checkpoint** | [`PolyChromaticLM-1.0-base-0.6B`](https://huggingface.co/tylerxdurden/PolyChromaticLM-1.0-base-0.6B) (step 19,531, 10.24B tokens) |
| **SFT dataset** | [`nvidia/Nemotron-Math-v2`](https://huggingface.co/datasets/nvidia/Nemotron-Math-v2) (high_part00, ~347K problems) |
| **Format** | ChatML with assistant-only loss masking |
| **Epochs** | 1 |
| **Optimizer** | AdamW (beta1=0.9, beta2=0.95, eps=1e-8) |
| **Peak LR** | 2e-5 (cosine decay, 100-step warmup) |
| **Effective batch** | ~524K tokens (micro_batch=2, grad_accum=16) |
| **Gumbel-Softmax tau** | 0.1 (frozen from pre-training) |
| **Steps** | 13,067 |
| **Hardware** | 1x NVIDIA A100 80GB |
| **Duration** | ~18 hours |
| **Compute cost** | ~$29.50 |
| **Mean throughput** | ~11,447 tok/s |
### Training Dynamics
Loss curve detail
 | Step | Loss |
|-----:|-----:|
| 10 | 1.77 |
| 500 | ~1.10 |
| 5,000 | ~0.95 |
| 10,000 | ~0.90 |
| 13,067 | **0.91** |
| Step | Loss |
|-----:|-----:|
| 10 | 1.77 |
| 500 | ~1.10 |
| 5,000 | ~0.95 |
| 10,000 | ~0.90 |
| 13,067 | **0.91** |
### Routing Entropy Stability
The most remarkable observation: **routing entropy remained at exactly 1.386 (= ln(4) = maximum entropy for K=4) throughout all 13,067 SFT steps.** This means:
- Static routing preferences learned during pre-training were NOT disturbed by SFT
- PolyGLU neurons maintained equal activation diversity across all 4 functions
- The routing architecture is **robust to fine-tuning** — a critical validation of the design
SFT modifies *what* is computed, not *how*: the routing mechanism (which activation function each neuron uses) remains unchanged, while the model's weights adapt to produce chain-of-thought reasoning.
---
## Evaluation
All benchmarks via [EleutherAI lm-evaluation-harness](https://github.com/EleutherAI/lm-eval) v0.4.11, 0-shot unless noted.
### Benchmarks (Base vs SFT vs Qwen3-0.6B-Base)
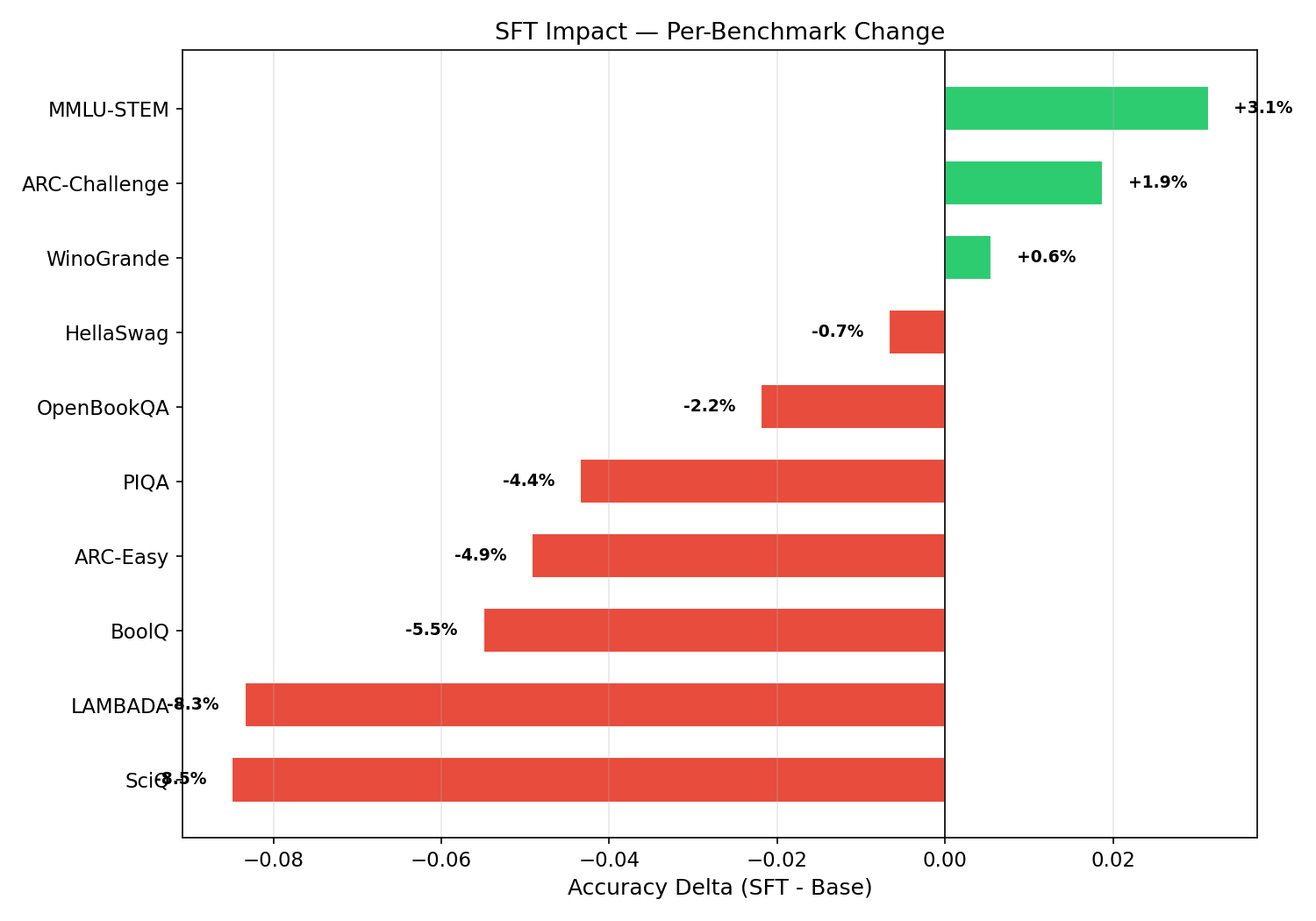
| Benchmark | Metric | Base | SFT | Delta | Random | Qwen3-0.6B |
|-----------|--------|-----:|----:|------:|-------:|-----------:|
| **HellaSwag** | acc_norm | 28.51 | 27.84 | -0.67 | 25.00 | 41.10 |
| **ARC-Easy** | acc_norm | 41.04 | 36.11 | -4.93 | 25.00 | 65.60 |
| **ARC-Challenge** | acc_norm | 22.27 | 24.15 | +1.88 | 25.00 | 33.90 |
| **PIQA** | acc_norm | 58.87 | 54.52 | -4.35 | 50.00 | 70.00 |
| **WinoGrande** | acc | 52.17 | 52.72 | +0.55 | 50.00 | 58.50 |
| **BoolQ** | acc | 61.13 | 55.63 | -5.50 | 50.00 | 69.70 |
| **MMLU-STEM** | acc (5-shot) | 25.28 | 28.42 | **+3.14** | 25.00 | — |
| **LAMBADA** | acc | 15.35 | 7.01 | -8.34 | ~0 | — |
| **OpenBookQA** | acc_norm | 29.00 | 26.80 | -2.20 | 25.00 | — |
| **SciQ** | acc_norm | 61.20 | 52.70 | -8.50 | 25.00 | — |
| **Mean** | | 39.48 | 36.59 | **-2.89** | | |
**Context**: Qwen3-0.6B-Base was trained on ~36T tokens (3,600x our budget). On the 6 tasks with published Qwen3 scores, our SFT model achieves 47-80% of Qwen3 performance. SFT narrows the gap on reasoning tasks like ARC-Challenge (71% of Qwen3, up from 66% pre-SFT).
### Forgetting Analysis
**Pattern**: Tasks requiring reasoning (ARC-Challenge +1.88, MMLU-STEM +3.14) improved, while tasks measuring text fluency (LAMBADA -8.34, SciQ -8.50) regressed. Mean regression of 2.89 pp is moderate and acceptable for math-focused SFT. 9/10 benchmarks remain above random.
### GSM8K
GSM8K generation-based evaluation was not completed due to compute budget constraints. Without KV cache, autoregressive generation of 1,319 test examples required ~9+ hours of A100 GPU time. Indirect evidence of SFT effectiveness includes the converged training loss (0.91) and MMLU-STEM improvement (+3.14 pp with large gains on quantitative subtasks). See the [full evaluation report](https://github.com/danielxmed/PolyGLU/blob/main/paper_reporting/sft__performance.md) for details.
---
## Architecture
| | |
|---|---|
| **Parameters** | 597M total (~1.4M routing, 0.23% overhead) |
| **Hidden dim** | 1,024 |
| **FFN dim** | 4,096 |
| **Layers** | 28 |
| **Attention** | GQA (16 query / 8 KV heads, head dim 64) |
| **Context** | 4,096 tokens |
| **Vocab** | 151,669 ([Qwen3](https://huggingface.co/Qwen/Qwen3-0.6B-Base) tokenizer) |
| **Position encoding** | RoPE (theta=10,000) |
| **Normalization** | RMSNorm (pre-norm) + QK-Norm |
| **FFN** | **PolyGLU** (K=4: ReLU, Tanh, SiLU, GELU) |
| **Weight tying** | Embedding <-> output head |
---
## Usage
This model was trained from scratch in pure PyTorch (no HuggingFace model wrappers). To load and use it:
```python
import torch
from transformers import AutoTokenizer
# Clone the training repo for model code
# git clone https://github.com/danielxmed/PolyGLU.git
from src.model.config import ModelConfig
from src.model.model import load_checkpoint
# Load model
config = ModelConfig(use_flash_attn=False)
model, step, tau = load_checkpoint("path/to/model.safetensors", config, device="cuda")
model.eval()
# Tokenize (ChatML format for instruct model)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-0.6B-Base")
prompt = "<|im_start|>user\nWhat is 15% of 240?<|im_end|>\n<|im_start|>assistant\n"
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()
# Generate (greedy, no KV cache)
with torch.no_grad():
for _ in range(200):
logits = model(input_ids)
next_token = logits[:, -1, :].argmax(dim=-1, keepdim=True)
input_ids = torch.cat([input_ids, next_token], dim=1)
if next_token.item() == tokenizer.eos_token_id:
break
print(tokenizer.decode(input_ids[0]))
```
> **Note**: This model loads from the custom PyTorch checkpoint format. The `load_checkpoint` function in the PolyGLU repo handles both `.pt` and `.safetensors` formats. See the [GitHub repo](https://github.com/danielxmed/PolyGLU) for full details.
---
## Limitations
- **No GSM8K evaluation** — generation-based evaluation was too expensive without KV cache (~9h for 1,319 examples). This is the most significant evaluation gap.
- **Math-only SFT** — fine-tuned exclusively on math problems. General instruction-following capability is limited.
- **10B token pre-training budget** — significantly less than comparable production models.
- **No KV cache** — inference requires the full training codebase; generation is slow.
- **English only** — trained exclusively on English-language data.
- **Single-epoch SFT** — additional epochs might improve performance but risk overfitting.
---
## Citation
```bibtex
@misc{nobrega2026polychromaticLM,
title = {PolychromaticLM: State-Conditional Activation Routing via Neurotransmitter-Inspired Gated Linear Units},
author = {Daniel Nobrega},
year = {2026},
url = {https://huggingface.co/tylerxdurden/PolyChromaticLM-1.0-instruct-0.6B}
}
```
---
## Links
| | |
|---|---|
| **Code** | [github.com/danielxmed/PolyGLU](https://github.com/danielxmed/PolyGLU) |
| **Base Model** | [PolyChromaticLM-1.0-base-0.6B](https://huggingface.co/tylerxdurden/PolyChromaticLM-1.0-base-0.6B) |
| **Instruct Model** | [PolyChromaticLM-1.0-instruct-0.6B](https://huggingface.co/tylerxdurden/PolyChromaticLM-1.0-instruct-0.6B) |
| **Weights & Biases** | [polychromatic-lm](https://wandb.ai/danielmedeiros-medeiros-nobrega-medtech/polychromatic-lm) |
---
Built from scratch on a single A100. Independent research by Daniel Nobrega.