
MiniMax Sparse Attention
Paper • 2606.13392 • Published • 78
MiniMax-M3 is a native multimodal model with 1M context. It has ~428B parameters and ~23B activated parameters.
Highlights:

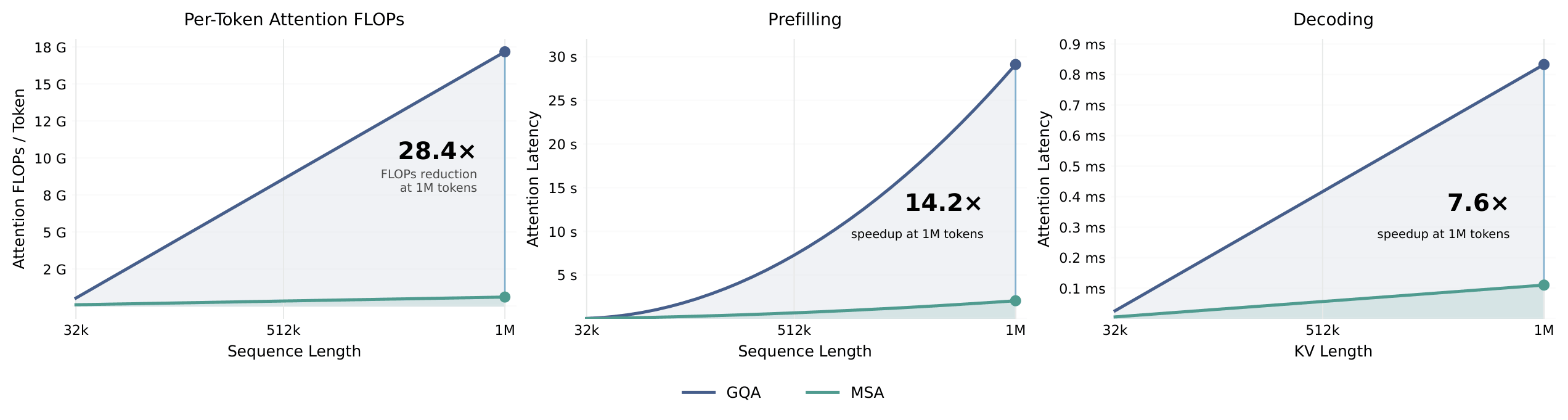
M3 is powered by MiniMax Sparse Attention (MSA), a high-performance sparse attention operator designed for million-token contexts. Compared with GQA, MSA dramatically reduces the attention compute and memory footprint while preserving model quality.
📄 Read the technical report: arXiv:2606.13392 · Hugging Face Papers
M3 supports two reasoning modes:
Download the model:
hf download MiniMaxAI/MiniMax-M3 --local-dir MiniMax-M3
We recommend the following inference frameworks (listed alphabetically) to serve the model:
SGLang - see SGLang cookbook.
vLLM - see vLLM recipes.
Transformers - see Transformers docs.
We recommend the following parameters for best performance: temperature=1.0, top_p=0.95, top_k=40.
Contact us at model@minimax.io.
Install from pip and serve model
# Install vLLM from pip: pip install vllm# Start the vLLM server: vllm serve "MiniMaxAI/MiniMax-M3"# Call the server using curl (OpenAI-compatible API): curl -X POST "http://localhost:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ --data '{ "model": "MiniMaxAI/MiniMax-M3", "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe this image in one sentence." }, { "type": "image_url", "image_url": { "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg" } } ] } ] }'