
ARWKV-7B-Preview-0.1
Collection
3 items • Updated

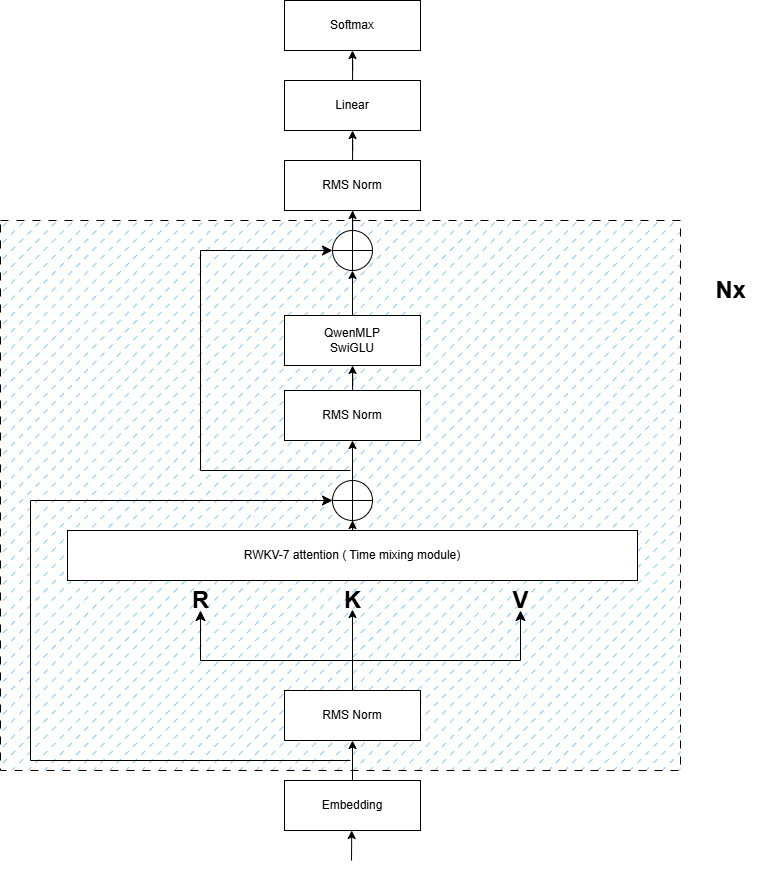
Preview version with RWKV-7 time mixing and Transformer MLP
This version doesn't have the parameter "g". It freezes the MLP and uses 32B logits for distillation alignment.
ALL YOU NEED IS RWKV
This is an early preview of our 7B parameter RNN-based model, trained on 2k context length (only stage-2 applied, without SFT or DPO) through 3-stage knowledge distillation from Qwen2.5-7B-Instruct. While being a foundational version, it demonstrates:
Roadmap Notice: We will soon open-source different enhanced versions with:
pip3 install --upgrade rwkv-fla transformers
Before training: export WKV_MODE=chunk
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"RWKV-Red-Team/ARWKV-7B-Preview-0.1-NoG-32B",
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(
"RWKV-Red-Team/ARWKV-7B-Preview-0.1-NoG-32B"
)
| Component | Specification | Note |
|---|---|---|
| Architecture | RWKV-7 TimeMix + SwiGLU | Hybrid design |
| Context Window | 2048 training CTX | Preview limitation |
| Training Tokens | 40M | Distillation-focused |
| Precision | FP16 inference recommended(16G Vram required) | 15%↑ vs BF16 |
Qwen2.5 Decoder Layer:
- Grouped Query Attention
+ RWKV-7 Time Mixing (Eq.3)
- RoPE Positional Encoding
+ State Recurrence
= Hybrid Layer Output