
Typhoon: Thai Large Language Models
Paper • 2312.13951 • Published • 7
irm https://unsloth.ai/install.ps1 | iex
# Run unsloth studio
unsloth studio -H 0.0.0.0 -p 8888
# Then open http://localhost:8888 in your browser
# Search for RichardErkhov/scb10x_-_typhoon-7b-gguf to start chatting# No setup required# Open https://huggingface.co/spaces/unsloth/studio in your browser
# Search for RichardErkhov/scb10x_-_typhoon-7b-gguf to start chattingYAML Metadata Warning:empty or missing yaml metadata in repo card
Check out the documentation for more information.
Quantization made by Richard Erkhov.
typhoon-7b - GGUF
| Name | Quant method | Size |
|---|---|---|
| typhoon-7b.Q2_K.gguf | Q2_K | 2.55GB |
| typhoon-7b.IQ3_XS.gguf | IQ3_XS | 2.83GB |
| typhoon-7b.IQ3_S.gguf | IQ3_S | 2.98GB |
| typhoon-7b.Q3_K_S.gguf | Q3_K_S | 2.96GB |
| typhoon-7b.IQ3_M.gguf | IQ3_M | 3.07GB |
| typhoon-7b.Q3_K.gguf | Q3_K | 3.29GB |
| typhoon-7b.Q3_K_M.gguf | Q3_K_M | 3.29GB |
| typhoon-7b.Q3_K_L.gguf | Q3_K_L | 3.57GB |
| typhoon-7b.IQ4_XS.gguf | IQ4_XS | 3.69GB |
| typhoon-7b.Q4_0.gguf | Q4_0 | 3.84GB |
| typhoon-7b.IQ4_NL.gguf | IQ4_NL | 3.89GB |
| typhoon-7b.Q4_K_S.gguf | Q4_K_S | 3.87GB |
| typhoon-7b.Q4_K.gguf | Q4_K | 4.09GB |
| typhoon-7b.Q4_K_M.gguf | Q4_K_M | 4.09GB |
| typhoon-7b.Q4_1.gguf | Q4_1 | 4.26GB |
| typhoon-7b.Q5_0.gguf | Q5_0 | 4.67GB |
| typhoon-7b.Q5_K_S.gguf | Q5_K_S | 4.67GB |
| typhoon-7b.Q5_K.gguf | Q5_K | 4.8GB |
| typhoon-7b.Q5_K_M.gguf | Q5_K_M | 4.8GB |
| typhoon-7b.Q5_1.gguf | Q5_1 | 5.09GB |
| typhoon-7b.Q6_K.gguf | Q6_K | 5.55GB |
Original model description:
Typhoon-7B is a pretrained Thai 🇹🇭 large language model with 7 billion parameters, and it is based on Mistral-7B.
Typhoon-7B outperforms all open-source Thai language models at the time of writing as evaluated on Thai examination benchmarks, and its instruction-tuned variant achieves the best results in instruction-following tasks. Also, its performance in Thai is on par with GPT-3.5 while being 2.62 times more efficient in tokenizing Thai text.
This is not an instruction-tuned model - It may not be able to follow human instructions without using one/few-shot learning or instruction fine-tuning. The model does not have any moderation mechanisms, and may generate harmful or inappropriate responses.
The Instruct model (chat-model) will be released soon. The beta version register is open at https://opentyphoon.ai/ or follow us for future model release https://twitter.com/opentyphoon.
For full details of this model, please read our paper.
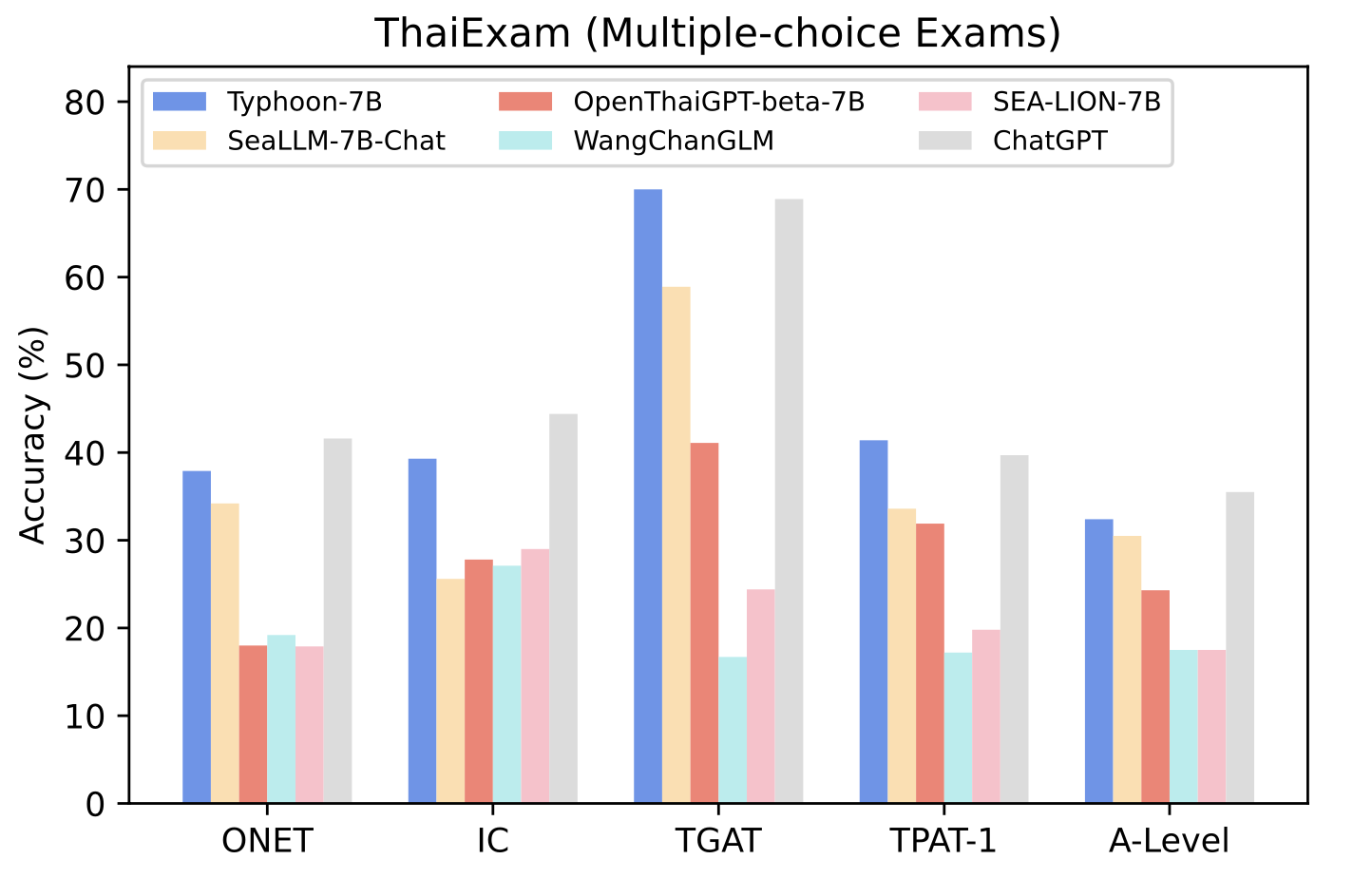
| Model | ONET | IC | TGAT | TPAT-1 | A-Level |
|---|---|---|---|---|---|
| Typhoon-7B | 0.379 | 0.393 | 0.700 | 0.414 | 0.324 |
| SeaLLM-7B | 0.342 | 0.256 | 0.589 | 0.336 | 0.305 |
| OpenThaiGPT-beta-7B | 0.180 | 0.278 | 0.411 | 0.319 | 0.243 |
| WangChanGLM | 0.192 | 0.271 | 0.167 | 0.172 | 0.175 |
| SEA-LION-7B | 0.179 | 0.290 | 0.244 | 0.198 | 0.175 |
| Avg. Human | 0.318 | - | 0.472 | 0.406 | - |
This model is a pretrained base model. Thus, it may not be able to follow human instructions without using one/few-shot learning or instruction fine-tuning. The model does not have any moderation mechanisms, and may generate harmful or inappropriate responses.
https://twitter.com/opentyphoon
@article{pipatanakul2023typhoon,
title={Typhoon: Thai Large Language Models},
author={Kunat Pipatanakul and Phatrasek Jirabovonvisut and Potsawee Manakul and Sittipong Sripaisarnmongkol and Ruangsak Patomwong and Pathomporn Chokchainant and Kasima Tharnpipitchai},
year={2023},
journal={arXiv preprint arXiv:2312.13951},
url={https://arxiv.org/abs/2312.13951}
}
2-bit
3-bit
4-bit
5-bit
6-bit
Install Unsloth Studio (macOS, Linux, WSL)
# Run unsloth studio unsloth studio -H 0.0.0.0 -p 8888 # Then open http://localhost:8888 in your browser # Search for RichardErkhov/scb10x_-_typhoon-7b-gguf to start chatting