
language:
- en
- he
license: apache-2.0
widget:
- text: Zion_Alpha
output:
url: >-
https://huggingface.co/SicariusSicariiStuff/Zion_Alpha/resolve/main/Zion_Alpha.png

Model Details
Zion_Alpha is the first REAL Hebrew model in the world. This version WAS fine tuned for tasks. I did the finetune using SOTA techniques and using my insights from years of underwater basket weaving. If you wanna offer me a job, just add me on Facebook.
Future Plans
I plan to perform a SLERP merge with one of my other fine-tuned models, which has a bit more knowledge about Israeli topics. Additionally, I might create a larger model using MergeKit, but we'll see how it goes.
Looking for Sponsors
Since all my work is done on-premises, I am constrained by my current hardware. I would greatly appreciate any support in acquiring an A6000, which would enable me to train significantly larger models much faster.
Papers?
Maybe. We'll see. No promises here 🤓
Contact Details
I'm not great at self-marketing (to say the least) and don't have any social media accounts. If you'd like to reach out to me, you can email me at sicariussicariistuff@gmail.com. Please note that this email might receive more messages than I can handle, so I apologize in advance if I can't respond to everyone.
Versions and QUANTS
Model architecture
Based on Mistral 7B. I didn't even bother to alter the tokenizer.
The recommended prompt setting is Debug-deterministic:
temperature: 1
top_p: 1
top_k: 1
typical_p: 1
min_p: 1
repetition_penalty: 1
The recommended instruction template is Mistral:
{%- for message in messages %}
{%- if message['role'] == 'system' -%}
{{- message['content'] -}}
{%- else -%}
{%- if message['role'] == 'user' -%}
{{-'[INST] ' + message['content'].rstrip() + ' [/INST]'-}}
{%- else -%}
{{-'' + message['content'] + '</s>' -}}
{%- endif -%}
{%- endif -%}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{-''-}}
{%- endif -%}
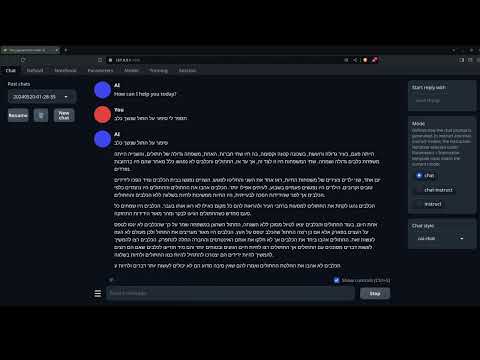
English to hebrew example:

English to hebrew example:

History
The model was originally trained about 2 month after Mistral (v0.1) was released. As of 04 June 2024, Zion_Alpha got the Highest SNLI score in the world among open source models in Hebrew, surpassing most of the models by a huge margin. (84.05 score)

Citation Information
@llm{Zion_Alpha_Instruction_Tuned,
author = {SicariusSicariiStuff},
title = {Zion_Alpha_Instruction_Tuned},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Zion_Alpha_Instruction_Tuned}
}
Support

- My Ko-fi page ALL donations will go for research resources and compute, every bit counts 🙏🏻
- My Patreon ALL donations will go for research resources and compute, every bit counts 🙏🏻