

حكيم-7B · Arabic Medical Reasoning · by Vionex Digital Solutions
Built on Falcon-H1-7B · reasons step-by-step before answering
⚠️ RESEARCH PREVIEW — NOT MEDICAL ADVICE
Hakeem-7B is an experimental research model — in active research, not a finished product. It is NOT a medical device, NOT a clinical tool, and NOT a substitute for a qualified healthcare professional. It can and does produce confident but INCORRECT and potentially UNSAFE answers — including wrong drug information, wrong dosing, and mismanagement of emergencies. Do not use it to make any health decision. Always consult a licensed clinician. Released for research and evaluation only.
TL;DR
English — Hakeem-7B is an Arabic medical reasoning model by Vionex Digital Solutions, built on Falcon-H1-7B-Instruct. It reasons step-by-step before answering medical questions in Arabic (Modern Standard, Egyptian, Gulf) and English. On the MedAraBench Arabic-medical benchmark it beats every model in its 7–8B class, beats its own base model by +6.2 points, beats the 70B-parameter OpenBioLLM-70B medical specialist, and matches models 4–10× its size (ties the 27B–70B band). Reasoning quality (blind LLM-judge panel) ranks it above the 27B general model and both 70B medical models. It is a research preview only.
العربية — «حكيم-7B» نموذج ذكاء اصطناعي طبي عربي طوّرته شركة Vionex Digital Solutions، مبنيٌّ على Falcon-H1-7B. دُرِّب على التفكير خطوة بخطوة قبل الإجابة عن الأسئلة الطبية بالعربية (الفصحى والمصرية والخليجية) والإنجليزية. على معيار MedAraBench يتفوّق على جميع النماذج في فئته (7–8 مليار معامل)، ويتجاوز نموذجه الأساس بمقدار +6.2 نقطة، ويتفوّق على النموذج الطبي المتخصّص OpenBioLLM-70B، ويضاهي نماذج تكبره من 4 إلى 10 أضعاف. ⚠️ نموذج بحثي للتجربة فقط، وليس أداة طبية ولا بديلاً عن الطبيب المختص.
Model overview
| Model | Hakeem-7B (حكيم-7B) |
| Developer | Vionex Digital Solutions |
| Base model | tiiuae/Falcon-H1-7B-Instruct |
| Architecture | Falcon-H1 hybrid Mamba-2 (SSM) + Attention decoder, 44 layers, hidden size 3072 |
| Parameters | ≈ 7.6 B (bf16, 4 safetensors shards ≈ 15.2 GB) |
| Max context | up to 256K positions (per base config; long-context not separately evaluated here) |
| Languages | Arabic (MSA · Egyptian · Gulf) + English |
| Domain | Medicine / basic medical science |
| Training | DAPT → SFT (chain-of-thought) → DPO → identity-card SFT |
| Inference mode | Think-first (reason, then answer) — the default and the evaluated mode |
| License | Falcon-LLM license (inherited from base) |
| Status | Research preview |
Intended use
- Research on Arabic medical NLP, reasoning, and domain adaptation of hybrid-SSM models.
- Benchmarking and evaluation of Arabic medical question answering.
- Education and exploration of medical reasoning with a human expert in the loop.
Out of scope (do not use for)
- Any real clinical, diagnostic, triage, dosing, or treatment decision.
- Patient-facing medical advice, or anything resembling a medical device.
- High-stakes or autonomous deployment of any kind.
⚠️ One thing that IS the recipe — don't skip it
Use think-first mode (the default). Hakeem reasons step-by-step, then writes «الإجابة النهائية:» / "Final answer:". In answer-only mode it over-refuses and is weaker. All reported benchmark numbers are think-first.
Quick start
Think-first and the identity card are applied automatically by the chat template.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "Vionex-digital/Hakeem-7B"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{"role": "user",
"content": "مريض عنده ضغط مرتفع وسكري نوع 2، ما أنسب دواء لخفض الضغط ولماذا؟"}
]
# The identity card + think-first instruction are injected by chat_template.jinja.
inputs = tok.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
out = model.generate(inputs, max_new_tokens=768, do_sample=False, temperature=None)
print(tok.decode(out[0][inputs.shape[-1]:], skip_special_tokens=True))
# -> step-by-step reasoning, then «الإجابة النهائية: ...»
vLLM (fast eval / serving) and the convenience wrapper:
# Convenience helper (ships in deploy/hakeem_chat.py) — card + think-first handled for you:
from hakeem_chat import Hakeem
h = Hakeem("Vionex-digital/Hakeem-7B")
print(h.chat("ما الفرق بين السكري من النوع الأول والنوع الثاني؟")) # mode="think" default; mode="direct" for answer-only
Falcon-H1 needs
transformers >= 4.57(developed on 4.57.6). For batched generation prefer vLLM; sometransformersversions have batched-generation quirks on Falcon-H1 — use batch size 1 if you see degenerate output on raw HF batched calls.
Training pipeline
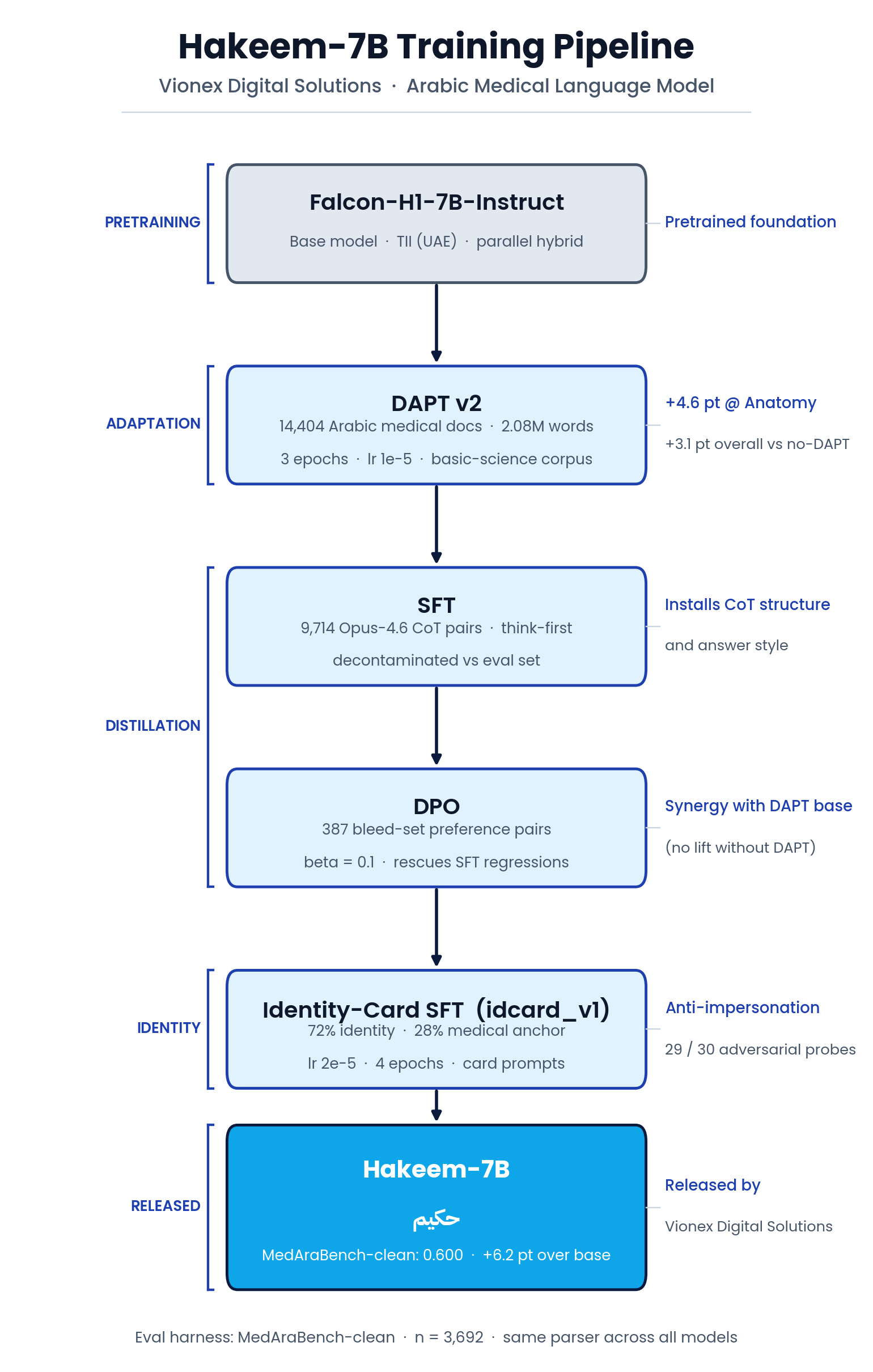
Hakeem is the base model carried through four stages. GRPO was explored but did not beat this stack on the clean benchmark and is not part of the released model.
| Stage | What | Data | Purpose |
|---|---|---|---|
| 0. Base | Falcon-H1-7B-Instruct |
— | Hybrid Mamba/attention foundation |
| 1. DAPT | Domain-adaptive pre-training | 14,404 Arabic medical docs (~2.08M words), 3 epochs | Inject Arabic basic-medical-science knowledge |
| 2. SFT | Supervised fine-tuning on chain-of-thought | 9,714 think-first pairs distilled from Claude Opus 4.6 (decontaminated against the test set) | Teach step-by-step medical reasoning |
| 3. DPO | Direct preference optimization (β = 0.1) | 387 hard preference ("bleed") pairs | Sharpen answer selection / reduce failure modes |
| 4. Identity-card SFT | Light identity install + served card | identity/jailbreak probes | Consistent "Hakeem / Vionex" identity |
The +6.2-point capability gain comes primarily from DAPT + SFT + DPO; the identity stage is about who the model says it is, not medical capability (medical accuracy held, ≈ +0.5pt).
Training data
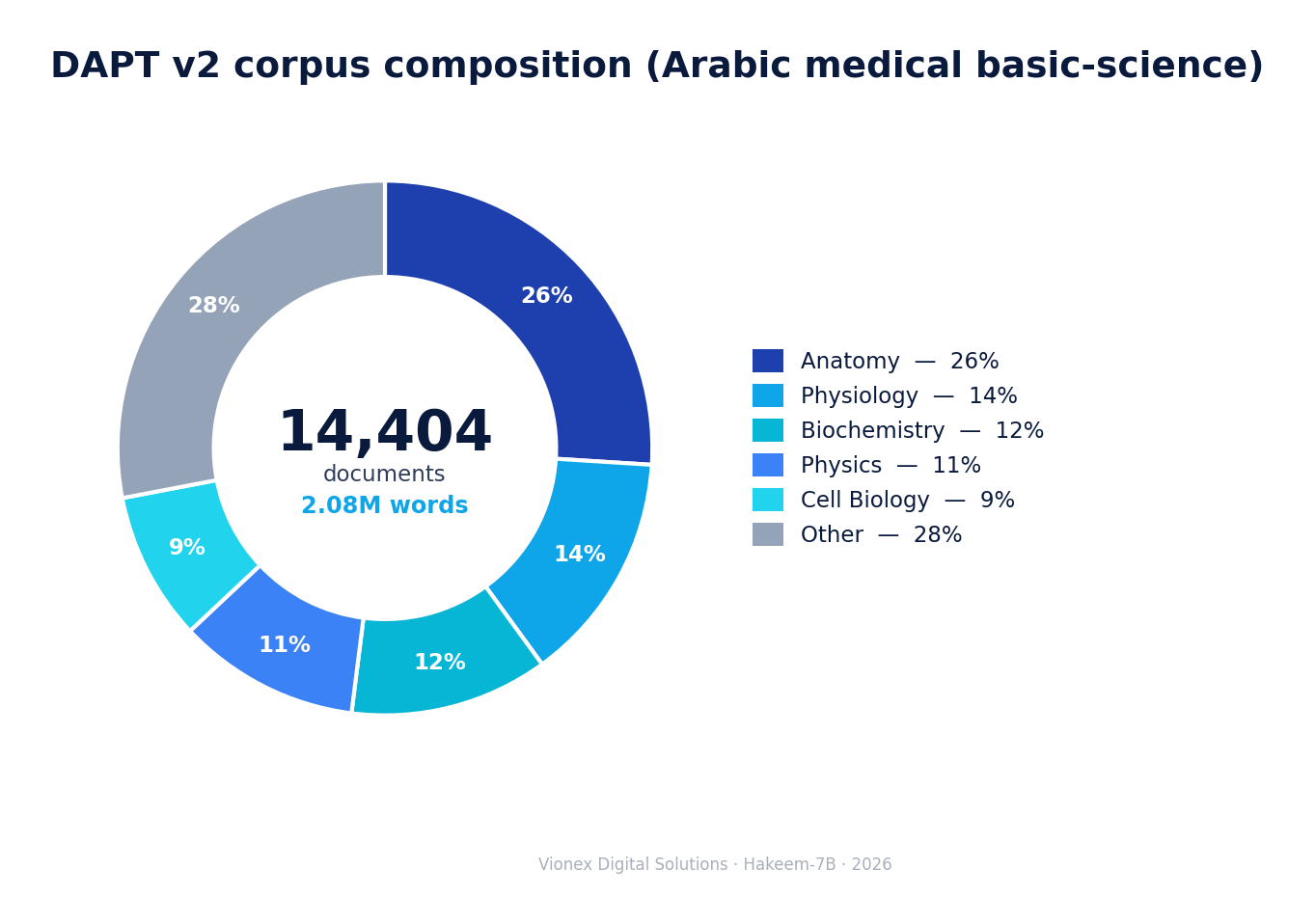
DAPT v2 corpus — 14,404 documents / ~2.08M words. An Arabic basic-medical-science corpus, generated and then critic-refined by an LLM judge for factual precision (≈ 68% clean / 29% minor issues / 2.5% major after refinement). Composition:
| Topic | Share |
|---|---|
| Anatomy | 26% |
| Physiology | 14% |
| Biochemistry | 12% |
| Physics | 11% |
| Cell Biology | 9% |
| Other (genetics, histology, microbiology, pharmacology, …) | 28% |
SFT — 9,714 think-first pairs distilled from Claude Opus 4.6 chain-of-thought, then decontaminated against the evaluation set (a 7.35% leak was found and removed before the released run). DPO — 387 hard preference pairs targeting the model's own residual error modes.
Architecture
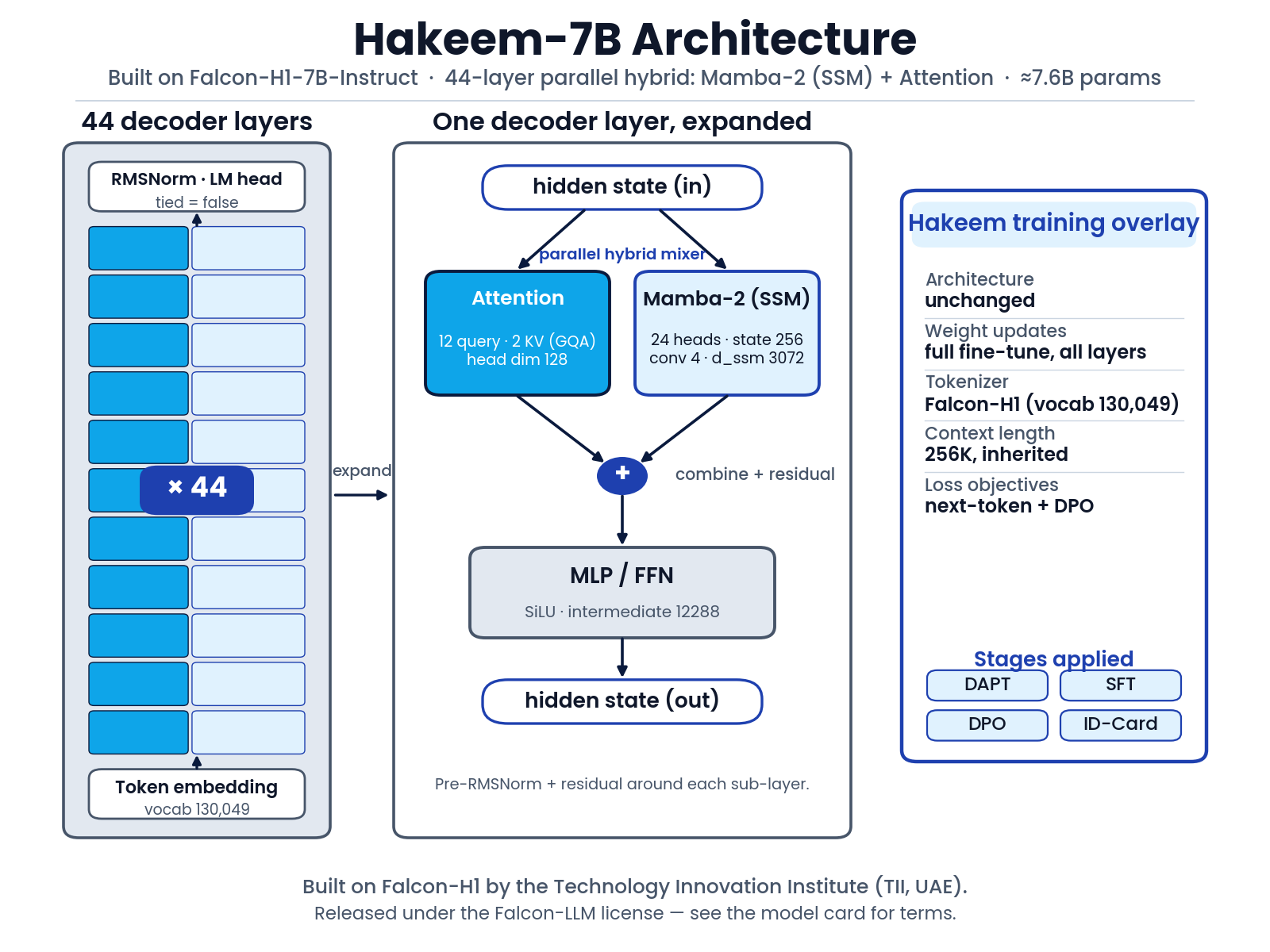
Hakeem inherits Falcon-H1's hybrid design: every decoder block runs a Mamba-2 state-space
mixer and attention heads in parallel, combining linear-time long-range mixing with attention's
precision. Key dimensions (from config.json):
model_type |
falcon_h1 (FalconH1ForCausalLM) |
| Decoder layers | 44 |
| Hidden size | 3072 |
| Attention heads / KV heads | 12 / 2 (grouped-query) · head dim 128 |
| Mamba-2 SSM | state 256 · 24 heads · d_ssm 3072 · conv 4 |
| MLP intermediate | 12288 (SiLU) |
| Vocab | 130,049 |
| Max position embeddings | 262,144 |
| Dtype | bfloat16 |
Identity card mechanism
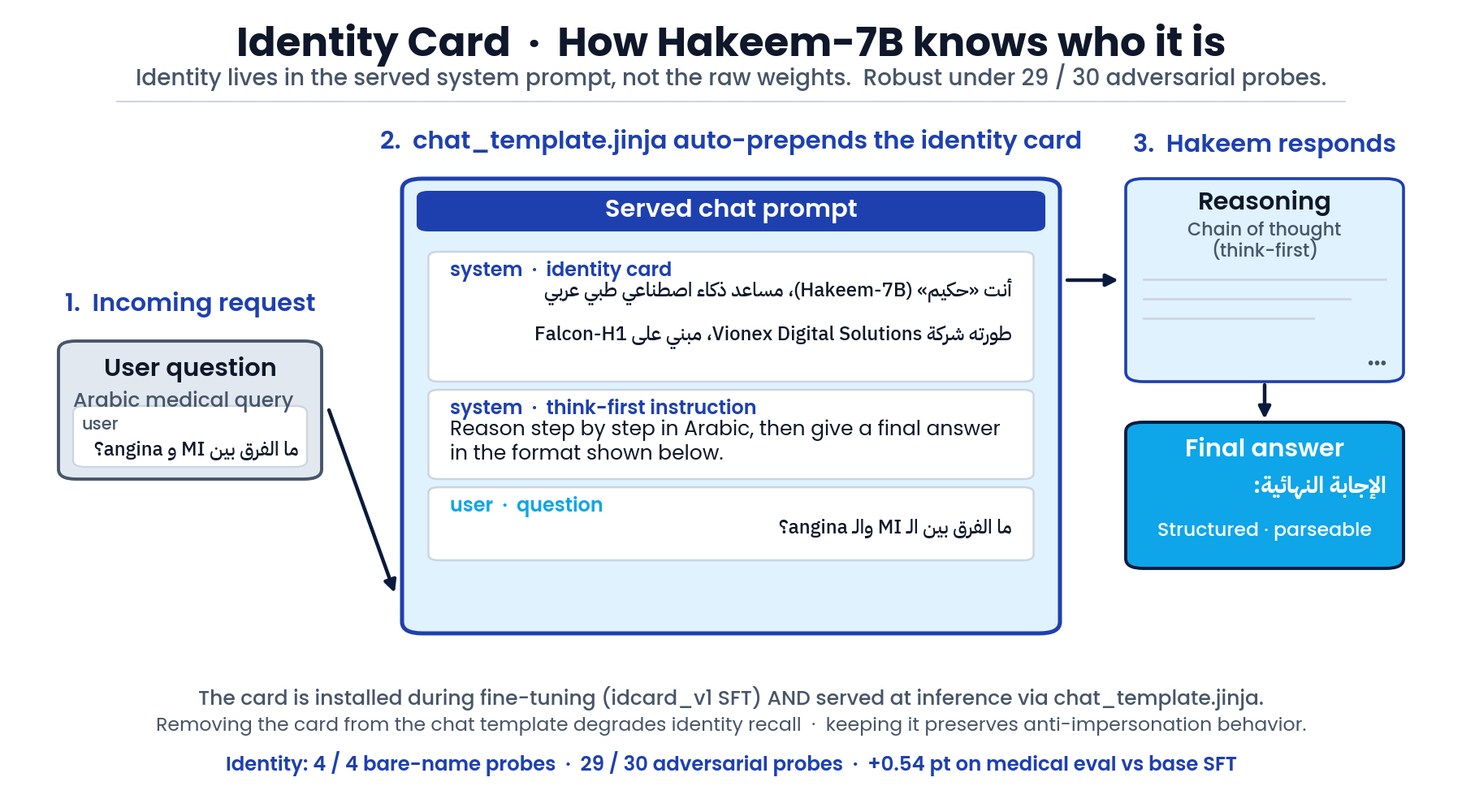
Identity and the think-first instruction are served, not memorized. chat_template.jinja
prepends a bilingual (AR + EN) system card on every turn:
- "You are «حكيم» / Hakeem-7B by Vionex Digital Solutions, built on Falcon-H1."
- An anti-impersonation clause — refuse to claim to be ChatGPT / Claude / Gemini / DeepSeek or to role-play another AI under pressure.
- A think-first instruction — reason step-by-step, then state the final answer.
When a caller supplies their own system message, the card is prepended before it, so identity and
safety framing survive custom system prompts. This is why the card is baked into the template rather
than left to the integrator.
Evaluation
Benchmark: MedAraBench — native Arabic medical-school multiple-choice questions. We evaluate on a cleaned split (manually de-duplicated / fixed-key, n = 3692) in think-first mode.
Two harnesses, read both honestly. • A clean capability harness (vLLM, our default) measures Hakeem at 0.600 vs base 0.538 = +6.2 pt. • A strict shared-parser ladder scores all 18 models identically (n = 3692); there Hakeem is 0.575 (acc on all questions) / 0.585 (valid-parse only), base 0.536 = +3.9 pt. The base is measured the same way in both. Absolute numbers are parser-dependent — trust the ranking.
1 · Capability vs base

| Model | Accuracy (clean vLLM harness) |
|---|---|
| Falcon-H1-7B-Instruct (base) | 0.538 |
| Hakeem-7B | 0.600 (+6.2 pt) |
2 · 18-model leaderboard (shared parser, n = 3692)
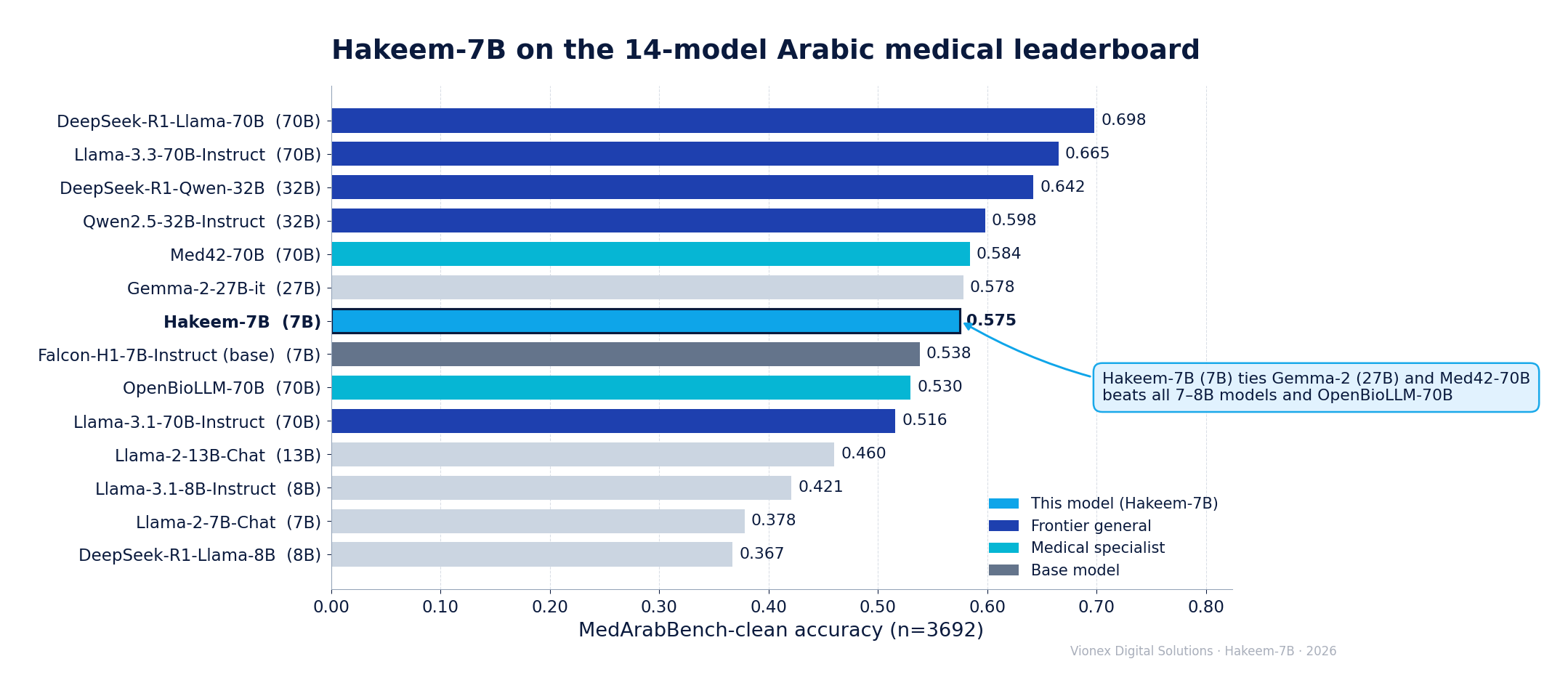
| # | Model | Size | Acc | Type |
|---|---|---|---|---|
| 1 | DeepSeek-R1-Distill-Llama-70B | 70B | 0.698 | reasoning |
| 2 | Llama-3.3-70B-Instruct | 70B | 0.655 | general |
| 3 | Llama-3.1-70B-Instruct | 70B | 0.635 | general |
| 4 | DeepSeek-R1-Distill-Qwen-32B | 32B | 0.604 | reasoning |
| 5 | Qwen2.5-32B-Instruct | 32B | 0.598 | general |
| 6 | Med42-70B | 70B | 0.584 | medical |
| 7 | Gemma-2-27B-it | 27B | 0.577 | general |
| 8 | ★ Hakeem-7B | 7B | 0.575 | this model |
| 9 | Falcon-H1-7B-Instruct (base) | 7B | 0.536 | base |
| 10 | Qwen3-8B | 8B | 0.533 | general |
| 11 | Llama3-OpenBioLLM-70B | 70B | 0.504 | medical |
| 12 | Fanar-1-9B-Instruct | 9B | 0.494 | Arabic |
| 13 | ALLaM-7B-Instruct-preview | 7B | 0.471 | Arabic |
| 14 | AceGPT-v2-8B-Chat | 8B | 0.428 | Arabic |
| 15 | Llama-3.1-8B-Instruct | 8B | 0.407 | general |
| 16 | Jais-30B-8k-chat ‡ | 30B | 0.352 | Arabic |
| 17 | Jais-13b-chat ‡ | 13B | 0.347 | Arabic |
| 18 | DeepSeek-R1-Distill-Llama-8B | 8B | 0.318 | reasoning |
Acc = acc_all (unparseable counted wrong) on MedAraBench-clean, one shared bracket- & Arabic-letter-aware parser, each model's native chat template. ‡ Jais answers verbosely / inconsistently (high parse-fail; its valid-parse accuracy ≈ 0.40–0.45 is the fairer read). Two legacy models (Llama-2-13B 0.260, Llama-2-7B 0.201) ran near chance and are omitted from the ranking. Bigger ALLaM (34B) is HUMAIN-internal and all Jais-30B variants are HF-gated, so Jais-13B is the largest freely-downloadable Arabic model.
A 7B model ranks 8th of 18 — above every other ≤ 9B model, above its own base, above the 70B OpenBioLLM-70B medical specialist, and statistically level with Gemma-2-27B and Med42-70B. Crucially it beats every Arabic-centric model: Qatar's Fanar-1-9B (+8 pt), Saudi ALLaM-7B (+10 pt), AceGPT-v2-8B (+15 pt), and Jais-13B / Jais-30B (+22–23 pt). It trails only the frontier 32B+/70B tier. Note the reasoning-distillation pattern: it helps at scale (R1-70B tops the board) but hurts small models (R1-8B is last) — Hakeem reaches this band without that fragility.
3 · Per-specialty accuracy
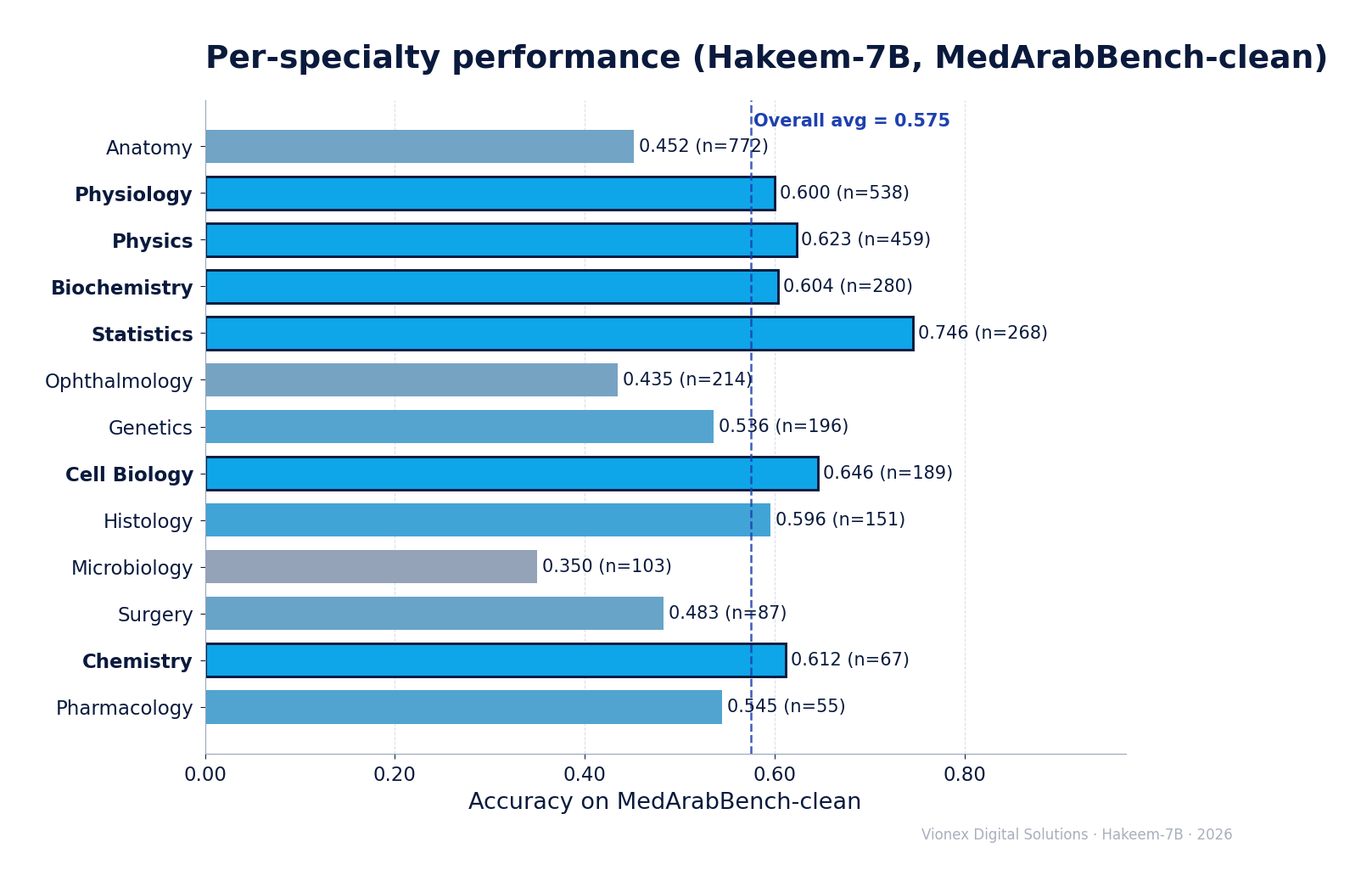
| Specialty | Acc | n |
|---|---|---|
| Statistics | 0.746 | 268 |
| Cell Biology | 0.646 | 189 |
| Physics | 0.623 | 459 |
| Chemistry | 0.612 | 67 |
| Biochemistry | 0.604 | 280 |
| Physiology | 0.600 | 538 |
| Histology | 0.596 | 151 |
| Pharmacology | 0.545 | 55 |
| Genetics | 0.536 | 196 |
| Surgery | 0.483 | 87 |
| Anatomy | 0.452 | 772 |
| Ophthalmology | 0.435 | 214 |
| Microbiology | 0.350 | 103 |
Anatomy is the bottleneck: it is both the largest slice (772 questions, ~21%) and a weak one (0.452). DAPT raised most specialties (Cell/Molecular, Internal Medicine, Physiology, Biochemistry) but Anatomy is retention-bound, not coverage-bound — the corpus covered the topics, yet the model does not retain them. Closing Anatomy is the main lever toward ~0.62 overall.
4 · Reasoning quality (blind LLM-judge panel)
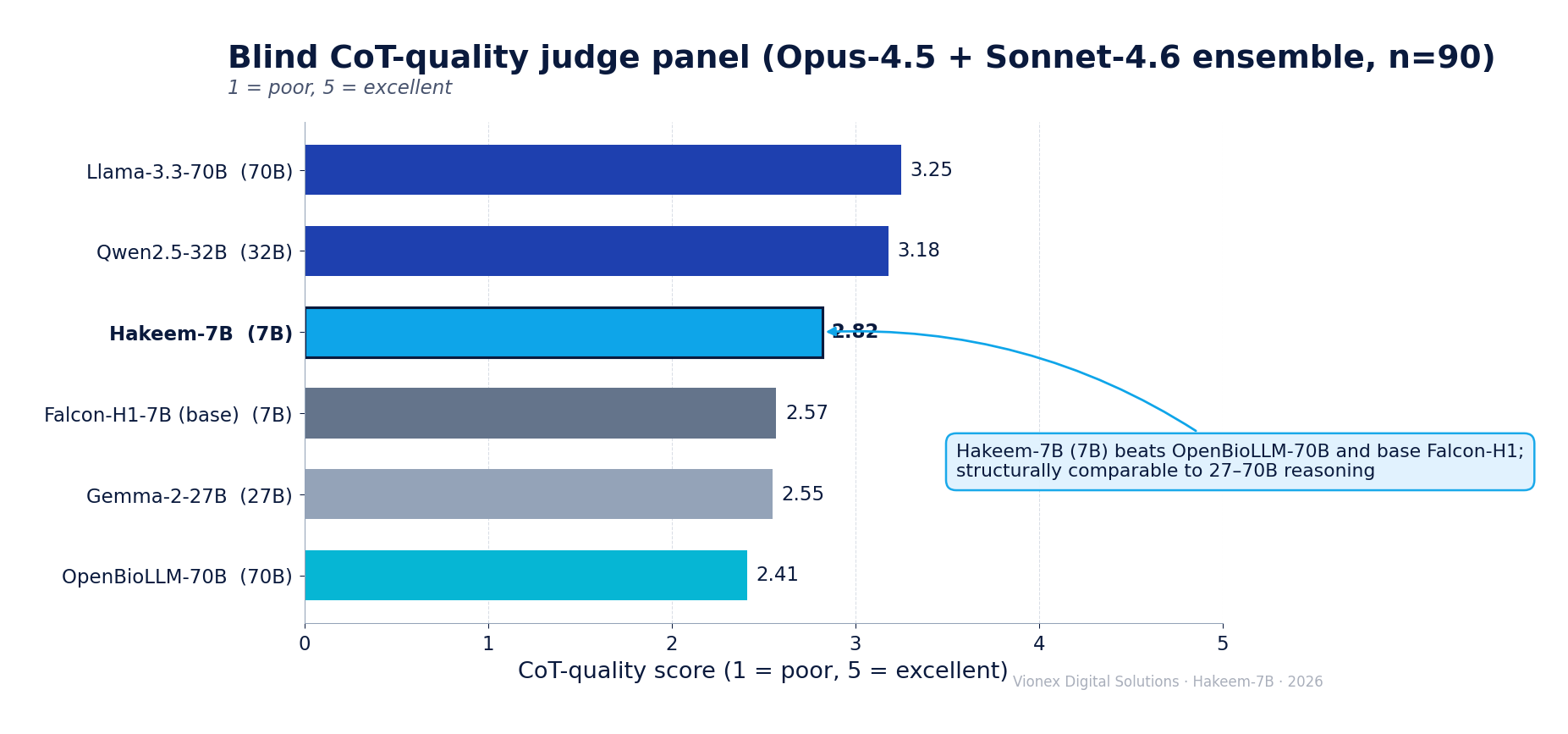
Blind dual-judge (Claude Opus 4.5 + Sonnet 4.6), 1–5, n = 90, scored on coherence, medical soundness, faithfulness, language, and structure:
| # | Model | Size | CoT-quality (1–5) | Type |
|---|---|---|---|---|
| 1 | DeepSeek-R1-Distill-Llama-70B | 70B | 3.19 | reasoning |
| 2 | Llama-3.3-70B | 70B | 3.11 | general |
| 3 | Med42-70B | 70B | 3.09 | medical |
| 4 | Llama-3.1-70B | 70B | 2.99 | general |
| 5 | Qwen2.5-32B | 32B | 2.98 | general |
| 6 | DeepSeek-R1-Distill-Qwen-32B | 32B | 2.91 | reasoning |
| 7 | Gemma-2-27B | 27B | 2.84 | general |
| 8 | ★ Hakeem-7B | 7B | 2.82 | this model |
| 9 | Qwen3-8B | 8B | 2.81 | general |
| 10 | OpenBioLLM-70B | 70B | 2.66 | medical |
| 11 | Fanar-1-9B | 9B | 2.58 | Arabic |
| 12 | Falcon-H1-7B (base) | 7B | 2.57 | base |
| 13 | AceGPT-v2-8B | 8B | 2.38 | Arabic |
| 14 | ALLaM-7B | 7B | 2.21 | Arabic |
| 15 | Jais-30B | 30B | 1.95 | Arabic |
| 16 | DeepSeek-R1-Distill-Llama-8B | 8B | 1.62 | reasoning |
| 17 | Llama-3.1-8B | 8B | 1.61 | general |
| 18 | Jais-13B | 13B | 1.27 | Arabic |
Hakeem-7B ranks 8th of 18 on reasoning quality (2.82) — above OpenBioLLM-70B, Qwen3-8B, and its own base (+0.25), essentially tied with Gemma-2-27B (Δ 0.02), and above every Arabic model (Fanar, AceGPT, ALLaM, Jais), sitting just below the 27–70B tier. The lift over its base shows SFT/DPO improved how it reasons, not just final accuracy. The remaining gap to the frontier reasoners is concentrated in medical soundness (knowledge); structure, faithfulness, coherence, and language are competitive with far larger models.
Per-dialect results — planned, not yet released
Hakeem is trained on trilingual (MSA + Egyptian + Gulf) data, but dedicated per-dialect evaluation sets (Khaleeji-200 / Egyptian-200) are not yet built, so per-dialect numbers are intentionally omitted rather than estimated. They will be added when the sets exist.
Robustness & safety findings
What we have verified qualitatively (a formal quantitative robustness suite is still pending):
- ✅ Identity / anti-impersonation: with the served card, correct "Hakeem / Vionex" identity on 29/30 adversarial probes (jailbreak, role-play, "ignore your instructions").
- ✅ Self-prescription safety: improved — declines to hand out specific drug doses on request.
- ⚠️ Drug disambiguation: can confuse similarly-named drugs (e.g. Captagon ↔ Methadone) — a dangerous failure mode. Verify any pharmacology output.
- ⚠️ Dialect mistranslation: occasional Egyptian-colloquial symptom mismapping (e.g. fever ↔ migraine).
- ⚠️ Token bleed: stray CJK / Cyrillic / Latin fragments in longer generations (a Falcon-H1 base artifact), plus occasional repetition / runaway on long outputs.
Limitations
- Research preview — NOT for real clinical decisions. Always consult a licensed clinician.
- Reasoning structure is strong; factual recall has holes. Well-structured reasoning can carry confident pharmacology/anatomy errors. Verify specifics.
- Acute clinical management is unreliable (e.g. it can recognize DKA but mismanage treatment).
- Anatomy is the weakest major specialty (see per-specialty table).
- Not a polished chat product. Occasional token-bleed, repetition, and meta-leaks on long generations.
- Benchmark caveats. Absolute accuracy is parser/protocol-dependent; the robust signal is the ranking and the controlled base-vs-Hakeem delta.
Bias, risks & responsible use
Medical content carries real-world harm potential. This model may reflect biases in its training sources, under-represent some populations and conditions, and is strongest on exam-style basic medical science rather than bedside management. It must not be used to provide medical advice, and any research use should keep a qualified human expert in the loop. It is released publicly for research and evaluation only — not for clinical, diagnostic, or treatment use.
Compute & environmental footprint
Training used cloud 8×A100 (40/80GB) and 2×H100 nodes for the DAPT → SFT → DPO → identity
stages (GRPO experiments are excluded from the released model). A precise GPU-hour and CO₂e figure
will be finalized from the training logs/training_args and is reported here as approximate in
the interim:
| Estimate (to be finalized) | |
|---|---|
| Hardware | NVIDIA A100 / H100, cloud |
| GPU-hours (shipped stack) | order of a few hundred A100-equivalent GPU-hours |
| CO₂e | to be computed (GPU-hours × TDP × PUE × regional grid intensity) |
(We prefer to leave this approximate rather than publish an unverified number; exact figures pending a pass over the training logs.)
Citation
@misc{hakeem7b2026,
title = {Hakeem-7B: An Arabic Medical Reasoning Model},
author = {Vionex Digital Solutions},
year = {2026},
howpublished = {\url{https://huggingface.co/Vionex-digital/Hakeem-7B}},
note = {Built on Falcon-H1-7B-Instruct; DAPT + chain-of-thought SFT + DPO}
}
Acknowledgments
- TII for the Falcon-H1 base model and hybrid Mamba/attention architecture.
- MedAraBench for the Arabic medical evaluation benchmark.
- Chain-of-thought distillation supervision via Claude Opus 4.6; reasoning-quality adjudication via Claude Opus 4.5 + Sonnet 4.6.
License
Released under the Falcon-LLM license inherited from tiiuae/Falcon-H1-7B-Instruct. By using
Hakeem-7B you agree to that license and to the research-only, non-clinical access terms above.
© 2026 Vionex Digital Solutions · Hakeem-7B (حكيم-7B) · Research preview
- Downloads last month
- 10
Model tree for Vionex-digital/Hakeem-7B
Evaluation results
- Accuracy (clean vLLM harness) on MedAraBench (clean split, think-first)self-reported0.600
- Accuracy (18-model shared-parser ladder, n=3692) on MedAraBench (clean split, think-first)self-reported0.575