
⚠️ 🇹🇷 Not: Model ağırlıkları henüz yüklenmedi (ağ kısıtı); kart, eğitim tamamlandıktan sonra yayınlandı. Ağırlıklar
scripts/supervised_upload.sh(Finetuner Studio) ile eklenecek. 🇬🇧 Note: Model weights are not uploaded yet (network constraint); they will follow via the repo's supervised upload script.
Llama-3.2-1B-Instruct · Turkish-Alpaca (MLX)
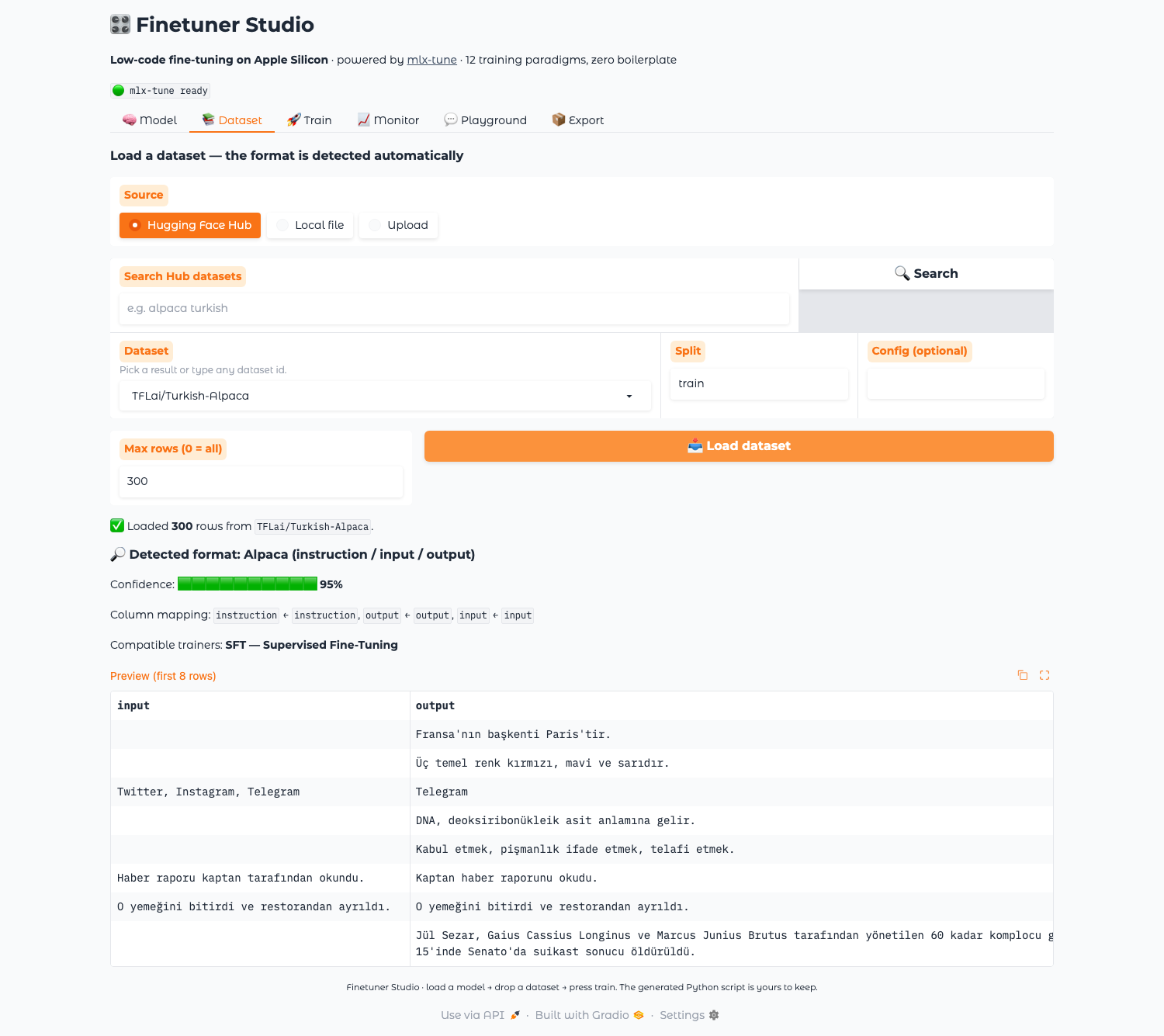
🇹🇷 Türkçe — Llama-3.2-1B-Instruct (4-bit MLX), TFLai/Turkish-Alpaca veri kümesinin tamamı (51.914 örnek) üzerinde LoRA ile ince ayarlandı. Eğitim, Apple Silicon üzerinde Finetuner Studio (arka uç: mlx-tune) ile tamamen yerel olarak yapıldı; veri kümesi formatı otomatik algılandı, eğitim native MLX ile koştu.
🇬🇧 English — Llama-3.2-1B-Instruct (4-bit MLX) fine-tuned with LoRA on the full Turkish-Alpaca instruction dataset (51,914 rows), trained entirely locally on an Apple Silicon Mac with Finetuner Studio, a low-code GUI over mlx-tune; the dataset format was auto-detected and training ran on native MLX.
Training details · Eğitim ayrıntıları
| Base model | mlx-community/Llama-3.2-1B-Instruct-4bit |
| Dataset | TFLai/Turkish-Alpaca (51,914 rows, auto-detected Alpaca format) |
| Method | LoRA r=16, α=16 on q/k/v/o + gate/up/down projections |
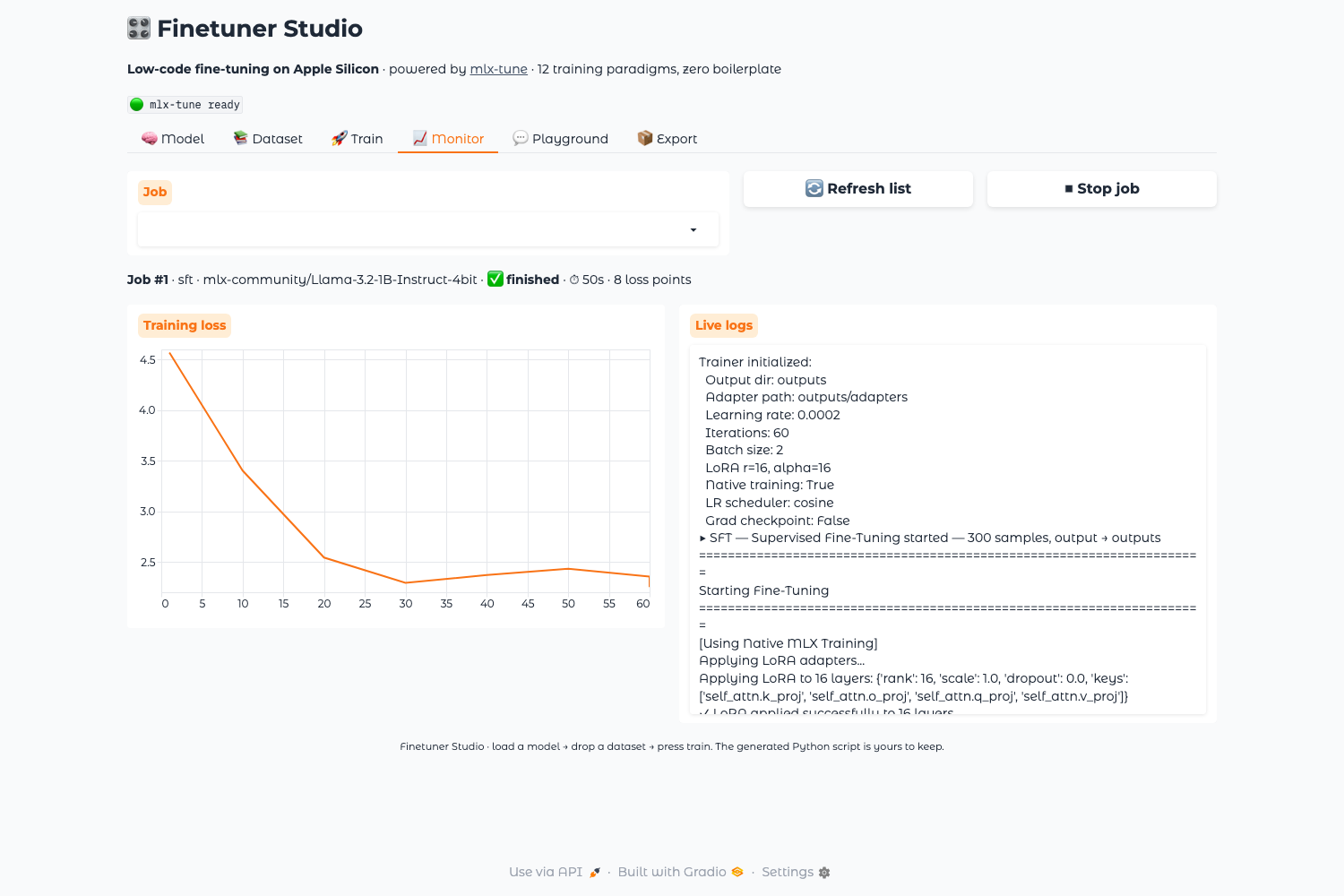
| Steps | 2,000 (batch 2, grad accum 1, seq len 2,048) |
| LR | 1e-4, cosine schedule, 50 warmup steps |
| Val loss | 4.876 → 2.248 |
| Hardware | Apple Silicon (MLX native training, ~221 tok/s, ≤7.376 GB) |
🇹🇷 Bu repo, kökte birleştirilmiş bf16 MLX modelini (4-bit taban LoRA ile
birleştirilirken dequantize edilir), adapters/
altında ise her 100 adımda kaydedilen tüm ara checkpoint'lerle birlikte ham
LoRA adaptörlerini içerir.
🇬🇧 This repo contains the merged bf16 MLX model at the root (the 4-bit
base is dequantized during LoRA fusion) and the raw LoRA adapters under
adapters/, including all intermediate checkpoints
saved every 100 steps.
Checkpoints · Ara kayıtlar
| Checkpoint | Val loss | Train loss |
|---|---|---|
0000100_adapters.safetensors |
— | 1.926 |
0000200_adapters.safetensors |
2.502 | 1.929 |
0000300_adapters.safetensors |
— | 2.271 |
0000400_adapters.safetensors |
2.296 | 1.881 |
0000500_adapters.safetensors |
— | 1.992 |
0000600_adapters.safetensors |
2.100 | 2.078 |
0000700_adapters.safetensors |
— | 1.991 |
0000800_adapters.safetensors |
1.780 | 1.824 |
0000900_adapters.safetensors |
— | 2.022 |
0001000_adapters.safetensors |
2.104 | 1.863 |
0001100_adapters.safetensors |
— | 1.894 |
0001200_adapters.safetensors |
1.993 | 1.796 |
0001300_adapters.safetensors |
— | 2.041 |
0001400_adapters.safetensors |
1.975 | 1.983 |
0001500_adapters.safetensors |
— | 1.668 |
0001600_adapters.safetensors |
2.009 | 2.050 |
0001700_adapters.safetensors |
— | 2.113 |
0001800_adapters.safetensors |
2.196 | 1.777 |
0001900_adapters.safetensors |
— | 2.197 |
0002000_adapters.safetensors |
2.248 | 1.912 |
Usage · Kullanım (MLX)
pip install mlx-lm
from mlx_lm import load, generate
model, tokenizer = load("acayir64/Llama-3.2-1B-Instruct-Turkish-Alpaca-mlx")
prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": "Yapay zeka nedir? Kısaca açıkla."}],
tokenize=False, add_generation_prompt=True)
print(generate(model, tokenizer, prompt=prompt, max_tokens=200))
Built with Finetuner Studio 🎛️
🇹🇷 Bu model, Finetuner Studio arayüzü üzerinden yapılandırıldı, eğitildi ve izlendi. 🇬🇧 This model was configured, trained and monitored entirely through the Finetuner Studio GUI:
GGUF · Ollama · LM Studio
🇹🇷 Bu model GGUF'a da dönüştürüldü (f16, llama.cpp convert_hf_to_gguf.py ile).
Kendi GGUF'unuzu üretmek için:
🇬🇧 The model also converts cleanly to GGUF (f16, via llama.cpp's
convert_hf_to_gguf.py). To produce your own GGUF:
# 1. Fuse adapters into the base (dequantized bf16):
mlx_lm.fuse --model mlx-community/Llama-3.2-1B-Instruct-4bit \
--adapter-path adapters --save-path fused --dequantize
# 2. Convert with llama.cpp:
python llama.cpp/convert_hf_to_gguf.py fused --outfile model-f16.gguf --outtype f16
Ollama
cat > Modelfile <<'EOF'
FROM ./model-f16.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop <|eot_id|>
PARAMETER temperature 0.7
PARAMETER repeat_penalty 1.15
EOF
ollama create llama32-turkish-alpaca -f Modelfile
ollama run llama32-turkish-alpaca "Sağlıklı yaşam için üç öneri ver."
LM Studio
🇹🇷 LM Studio, Mac'te MLX modellerini doğrudan çalıştırır: uygulama içi
aramaya acayir64/Llama-3.2-1B-Instruct-Turkish-Alpaca-mlx yazıp indirin — bu repo MLX formatındadır. Alternatif
olarak ürettiğiniz GGUF dosyasını My Models → Import ile yükleyebilirsiniz.
🇬🇧 LM Studio runs MLX models natively on Mac: search acayir64/Llama-3.2-1B-Instruct-Turkish-Alpaca-mlx inside
the app and download — this repo is MLX-format. Alternatively import your
GGUF file via My Models → Import.
Intended use & limitations · Kullanım amacı ve sınırlamalar
🇹🇷 Türkçe talimat takibi için eğitilmiş küçük (1B) bir modeldir; bilgi yoğun sorularda hata yapabilir, üretim kullanımı öncesi değerlendirme gerekir. 🇬🇧 A small 1B model for Turkish instruction following — expect factual mistakes; evaluate before production use.
Trained & published with Finetuner Studio 🎛️
Model tree for acayir64/Llama-3.2-1B-Instruct-Turkish-Alpaca-mlx
Base model
mlx-community/Llama-3.2-1B-Instruct-bf16