
license: apache-2.0
tags:
- music
- audio
- embeddings
- mert
- fma
- music-information-retrieval
task_categories:
- audio-classification
- feature-extraction
size_categories:
- 1K<n<10K
language:
- en
FMA-MERT Embeddings
Pre-computed MERT-v1-330M embeddings for the FMA-Small dataset. 7,997 tracks, each represented as a 1024-dimensional vector, with banger scores (0-10) derived from log-normalized play counts.
Use this dataset to train music quality scorers, explore music similarity, or experiment with audio representation learning -- without needing to download 7.2 GB of audio or run MERT yourself.
Dataset Description
Each row represents one track from FMA-Small, encoded through MERT-v1-330M and annotated with popularity-based quality labels.
Fields
| Field | Type | Description |
|---|---|---|
track_id |
int | FMA track identifier |
embedding |
list[float] (1024) | Mean-pooled MERT-v1-330M embedding |
banger_score |
float (0-10) | Log-normalized play count, scaled to 0-10 |
genre |
string | Top-level genre from FMA metadata |
listens |
int | Raw play count from FMA |
Size
- 7,997 tracks (3 corrupt MP3s out of 8,000 failed during embedding extraction -- 99.96% success rate)
- 1024 dimensions per embedding
- ~31 MB as a NumPy array on disk
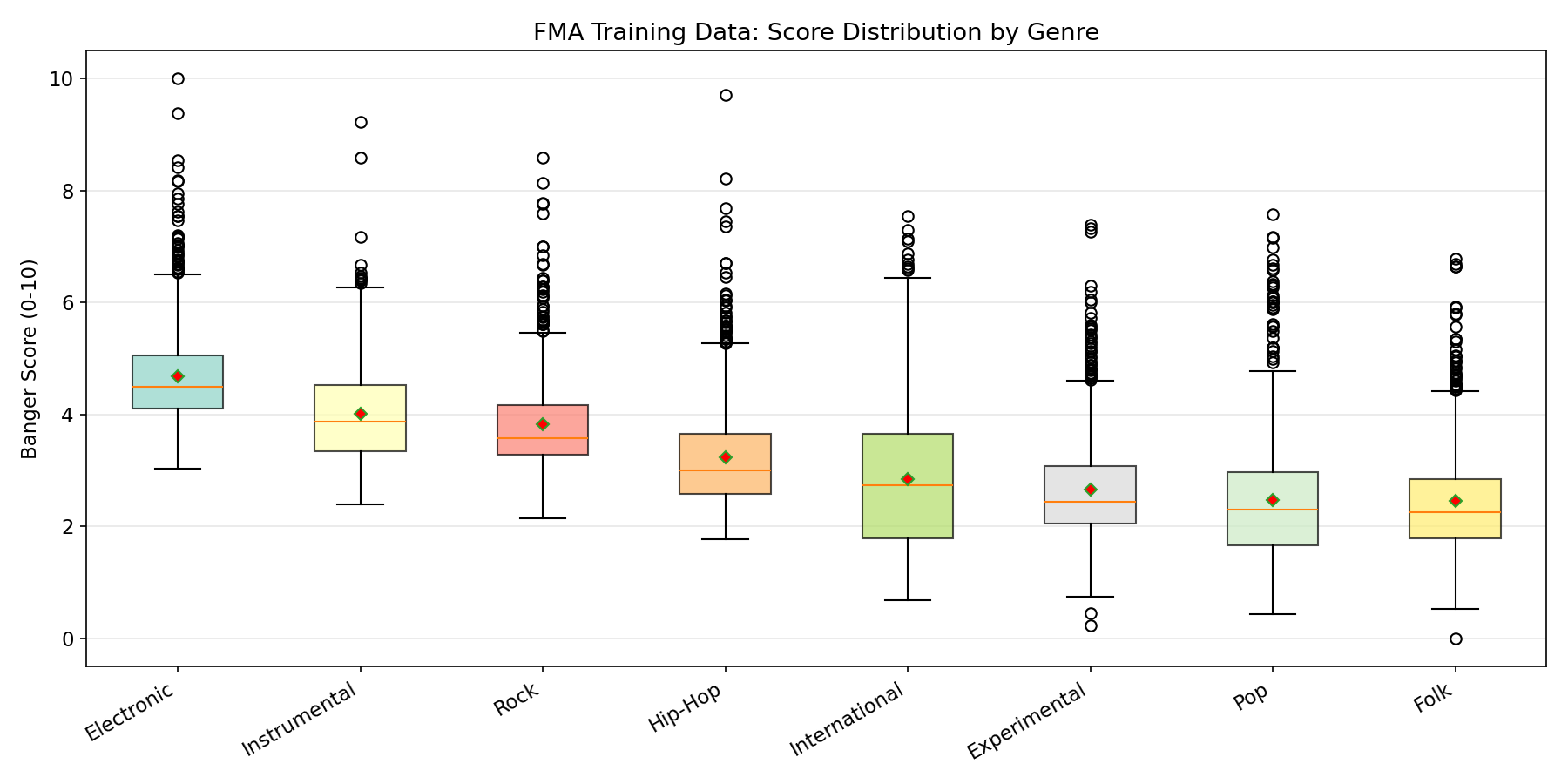
Genre Breakdown
FMA-Small is perfectly balanced across 8 genres (~1,000 tracks each):
| Genre | Count |
|---|---|
| Hip-Hop | ~1,000 |
| Pop | ~1,000 |
| Folk | ~1,000 |
| Experimental | ~1,000 |
| Rock | ~1,000 |
| International | ~1,000 |
| Electronic | ~1,000 |
| Instrumental | ~1,000 |
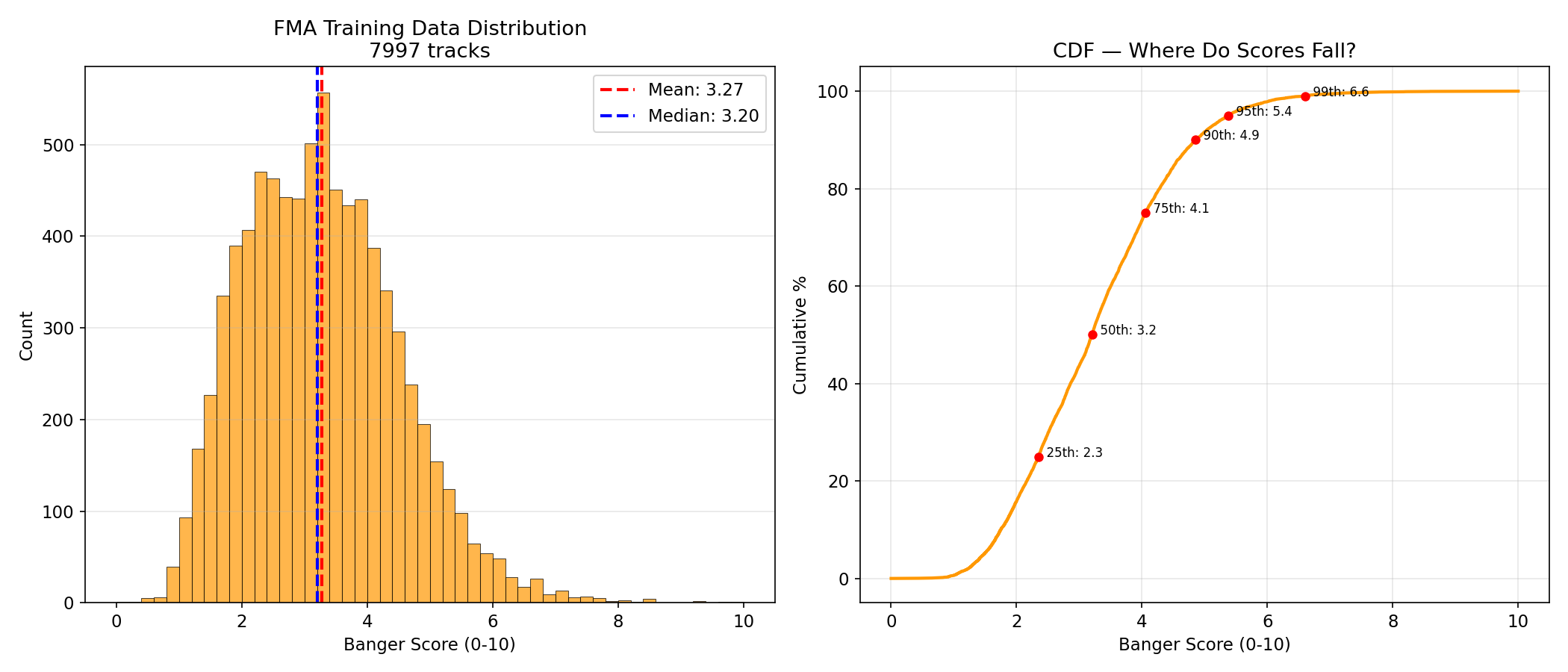
Score Distribution
Banger scores are derived from FMA play counts via log-normalization:
log_listens = np.log1p(df["listens"])
banger_score = (log_listens - log_listens.min()) / (log_listens.max() - log_listens.min()) * 10.0
| Statistic | Value |
|---|---|
| Mean | 3.27 |
| Median | 3.20 |
| Std | 1.37 |
| Min | 0.00 |
| Max | 10.00 |
| Tracks >= 5.0 | 668 (8.4%) |
| Tracks >= 7.0 | 45 (0.6%) |
| Tracks >= 9.0 | 4 (0.1%) |
The distribution is concentrated in the 1-5 range. Very few tracks have high scores, which reflects the heavy-tailed nature of music popularity (a few hits, many average tracks).
Source Data
Audio Source
FMA (Free Music Archive) -- a large-scale, freely available dataset of audio tracks. FMA-Small contains 8,000 tracks of 30-second clips (7.2 GB), Creative Commons licensed.
Play count range: 196 to 543,252 (mean 4,730, median 2,492). The massive gap between mean and median reflects the power-law distribution typical of music popularity.
How Embeddings Were Generated
Model: m-a-p/MERT-v1-330M -- a 330M parameter, 24-layer self-supervised music understanding model trained on 160,000 hours of audio.
Process:
- Load each MP3 track and resample to 24kHz mono (MERT's expected input rate) using librosa
- Truncate to 30 seconds maximum
- Run through MERT's feature extractor and forward pass
- Mean-pool the last hidden state across the time dimension:
outputs.last_hidden_state.mean(dim=1)to produce a single 1024-dim vector per track - Save as NumPy array
# Core embedding logic
waveform, _ = librosa.load("track.mp3", sr=24000, mono=True)
waveform = waveform[:24000 * 30] # 30s max
inputs = feature_extractor(waveform, sampling_rate=24000, return_tensors="pt")
with torch.no_grad():
outputs = mert(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1).squeeze(0).cpu().numpy() # (1024,)
Compute:
- Device: Apple M4 Pro, Metal Performance Shaders (MPS)
- Processing rate: 1.3 tracks/second
- Total time: 101 minutes for 7,997 tracks
- Peak memory: ~1.7 GB (MERT model + one audio buffer)
- Failures: 3 out of 8,000 (corrupt MP3s)
Why mean pooling? MERT produces ~1,200 time frames (one per ~25ms) for a 30-second clip, each with a 1024-dim vector. Mean pooling collapses these into a single vector that captures the overall "essence" of the track -- rhythm patterns, harmonic content, timbral quality, melodic structure -- while discarding temporal ordering. Simple and effective as a baseline; attention pooling could be explored for improvements.
How to Use
from datasets import load_dataset
import numpy as np
# Load the dataset
ds = load_dataset("treadon/fma-mert-embeddings", split="train")
# Access a single track
track = ds[0]
embedding = np.array(track["embedding"]) # (1024,)
score = track["banger_score"] # float 0-10
genre = track["genre"] # e.g., "Electronic"
listens = track["listens"] # raw play count
print(f"Track {track['track_id']}: {genre}, score={score:.2f}, listens={listens}")
print(f"Embedding shape: {embedding.shape}")
# Filter by genre
electronic = ds.filter(lambda x: x["genre"] == "Electronic")
print(f"Electronic tracks: {len(electronic)}")
# Get all embeddings as a matrix for training
all_embeddings = np.array(ds["embedding"]) # (7997, 1024)
all_scores = np.array(ds["banger_score"]) # (7997,)
Train a scorer on these embeddings
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
# Load embeddings
ds = load_dataset("treadon/fma-mert-embeddings", split="train")
X = np.array(ds["embedding"]) # (7997, 1024)
y = np.array(ds["banger_score"]) # (7997,)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define a simple MLP
scorer = nn.Sequential(
nn.Linear(1024, 512), nn.BatchNorm1d(512), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(512, 256), nn.BatchNorm1d(256), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(256, 128), nn.BatchNorm1d(128), nn.ReLU(), nn.Dropout(0.15),
nn.Linear(128, 1),
)
# Train... (see treadon/banger-scorer for full training code)
The trained model that ships with treadon/banger-scorer achieved MAE 0.858 and Spearman 0.468 on this data, training in ~30 seconds on M4 Pro.
Use Cases
- Train music quality scorers without downloading 7.2 GB of FMA audio or running MERT (which takes ~100 minutes on GPU)
- Music similarity search -- compute cosine similarity between embeddings to find similar-sounding tracks
- Genre classification -- train a classifier on the embeddings using the genre labels
- Explore MERT's representation space -- visualize with t-SNE/UMAP, analyze what musical features each dimension captures
- Baseline for music understanding tasks -- compare against fine-tuned or alternative audio models
Limitations
- FMA-Small only. 8,000 tracks is relatively small. FMA-Medium (25K) or FMA-Large (106K) would provide more diverse representations.
- Popularity labels are noisy. Play counts reflect many factors beyond musical quality: playlist placement, artist following, upload timing. They are a useful but imperfect proxy.
- Mean pooling discards temporal info. The embeddings capture "what happens" but not "when it happens." Songs with identical frequency content but different temporal structures will have similar embeddings.
- 30-second clips. FMA-Small contains 30-second excerpts, not full tracks. The embedding represents only part of each song.
- Fixed MERT version. These embeddings are from MERT-v1-330M specifically. They are not compatible with other audio encoders or MERT versions.
Citation
@article{li2023mert,
title={MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training},
author={Li, Yizhi and Yuan, Ruibin and Zhang, Ge and Ma, Yinghao and others},
journal={arXiv preprint arXiv:2306.00107},
year={2023}
}
@inproceedings{defferrard2017fma,
title={FMA: A Dataset For Music Analysis},
author={Defferrard, Micha{\"e}l and Benzi, Kirell and Vandergheynst, Pierre and Bresson, Xavier},
booktitle={ISMIR},
year={2017}
}
Dataset Card Contact
treadon on HuggingFace