
✂️ Abliteration
Collection
Uncensored models using abliteration. See this article for more information: huggingface.co/blog/mlabonne/abliteration • 32 items • Updated • 167

This is an uncensored version of google/gemma-3-1b-it-qat-q4_0-unquantized created with a new abliteration technique. See this article to know more about abliteration.
This is a new, improved version that targets refusals with enhanced accuracy.
I recommend using these generation parameters: temperature=1.0, top_k=64, top_p=0.95.
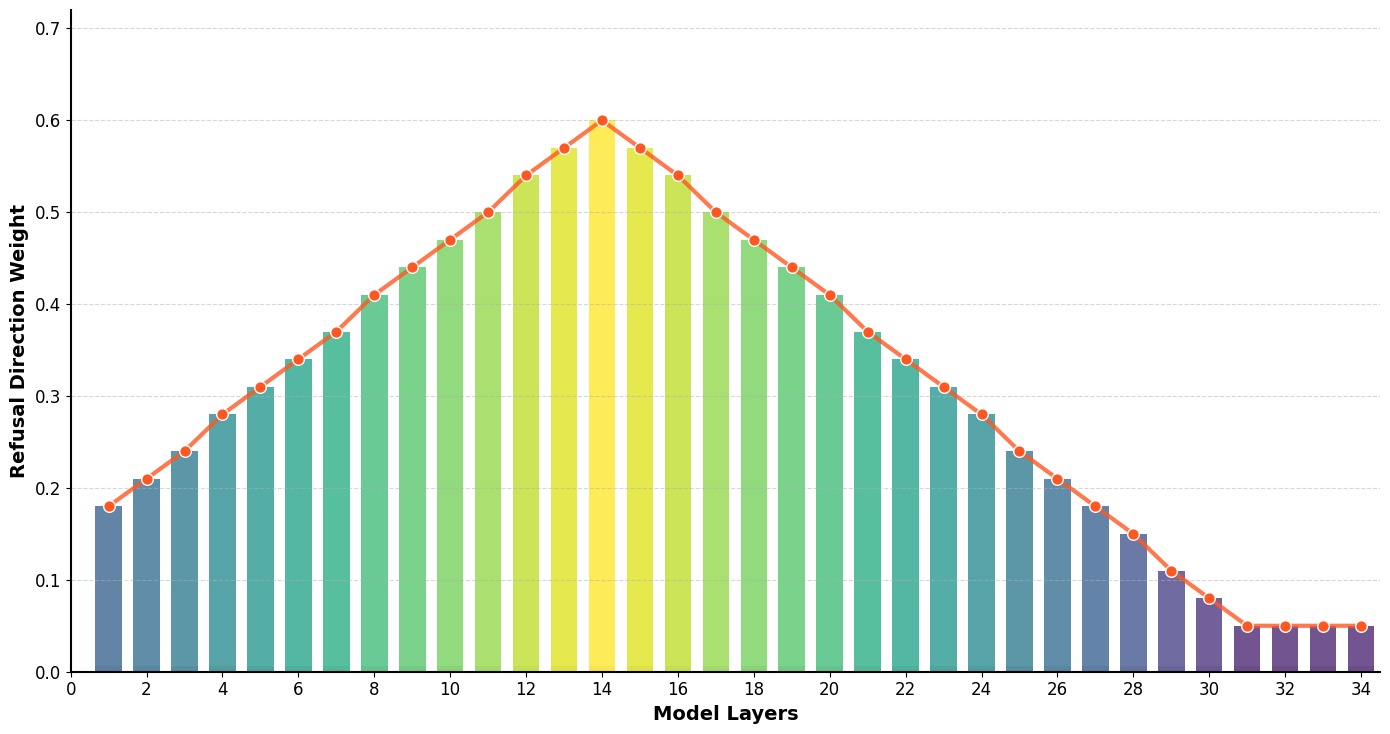
The refusal direction is computed by comparing the residual streams between target (harmful) and baseline (harmless) samples. The hidden states of target modules (e.g., o_proj) are orthogonalized to subtract this refusal direction with a given weight factor. These weight factors follow a normal distribution with a certain spread and peak layer. Modules can be iteratively orthogonalized in batches, or the refusal direction can be accumulated to save memory.
Finally, I used a hybrid evaluation with a dedicated test set to calculate the acceptance rate. This uses both a dictionary approach and NousResearch/Minos-v1. The goal is to obtain an acceptance rate >90% and still produce coherent outputs.