
Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
Paper • 2606.02373 • Published • 54
# Load model directly
from transformers import AutoTokenizer, AutoModelForMultimodalLM
tokenizer = AutoTokenizer.from_pretrained("pat-jj/harness-1")
model = AutoModelForMultimodalLM.from_pretrained("pat-jj/harness-1")
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))A 20B search agent that matches frontier AI's search capability.
safetensors shards.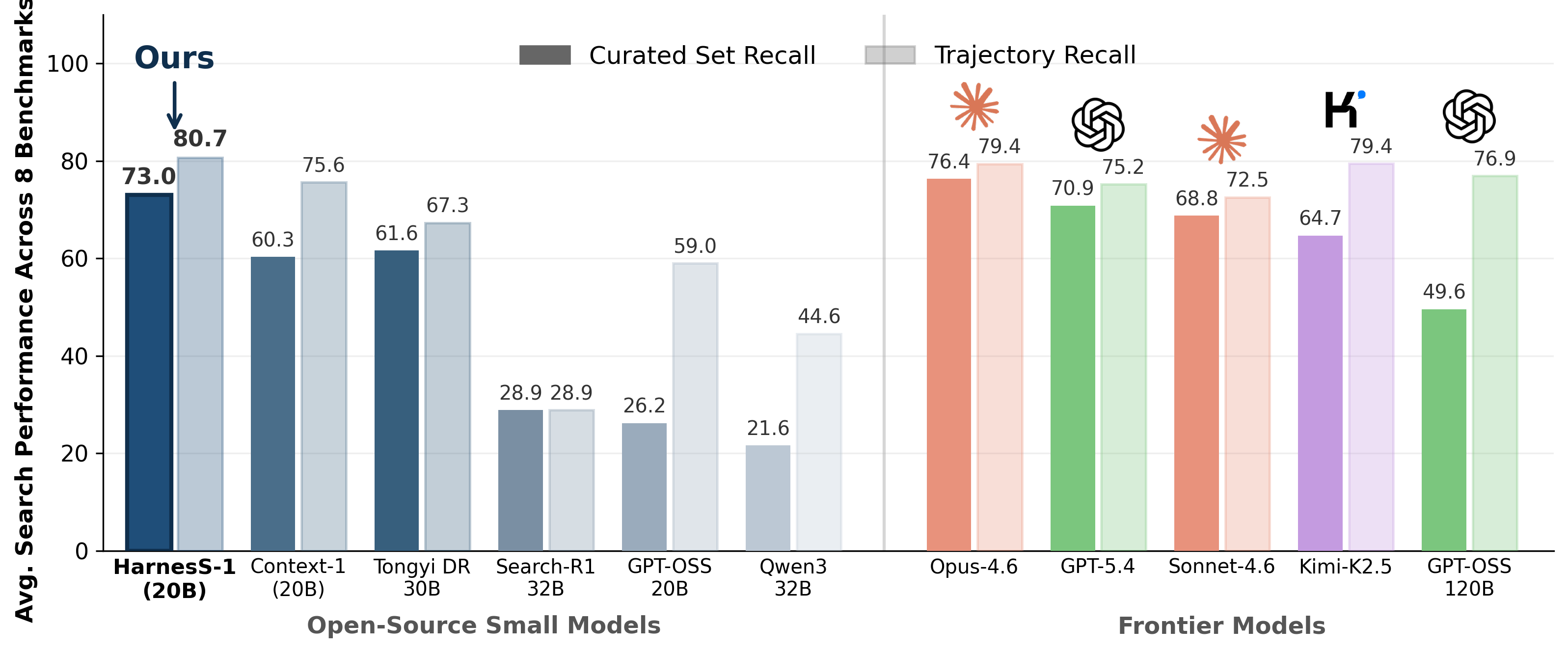
Code: https://github.com/pat-jj/harness-1
Paper: https://arxiv.org/abs/2606.02373
Training data and corpora: https://huggingface.co/datasets/pat-jj/harness-1-train-data
Tinker inference example: https://github.com/pat-jj/harness-1/blob/main/inference/tinker_inference.md
vLLM inference example: https://github.com/pat-jj/harness-1/blob/main/inference/vllm_h100_browsecompplus.md
This repository contains the full merged Harness-1 release checkpoint. The model
is merged into the openai/gpt-oss-20b base model and saved as standard Hugging
Face safetensors shards.
The Harness-1 training data and retrieval corpora are published separately as
pat-jj/harness-1-train-data.
It contains one train split with a stage column:
sft: 899 raw GPT-5.4-generated v8d SFT trajectories produced by generate_sft_ultra_0417.py.rl: 3,453 SEC training-split query records used for RL (TRAIN_DATASETS=sec, RL_QUERY_SPLIT=train).The same dataset repo also includes retrieval corpora under corpora/:
corpora/browsecompplus/test: 1,144,886 chunks.corpora/web/train: 219,388 chunks.corpora/web/test: 54,735 chunks.corpora/patents/train: 104,842 chunks.corpora/patents/test: 35,551 chunks.corpora/sec/train: 2,115,106 chunks.from datasets import load_dataset
ds = load_dataset("pat-jj/harness-1-train-data", split="train")
sft = ds.filter(lambda row: row["stage"] == "sft")
rl = ds.filter(lambda row: row["stage"] == "rl")
sec_corpus = load_dataset(
"parquet",
data_files="hf://datasets/pat-jj/harness-1-train-data/corpora/sec/train/*.parquet",
split="train",
)
# Use a pipeline as a high-level helper from transformers import pipeline pipe = pipeline("text-generation", model="pat-jj/harness-1") messages = [ {"role": "user", "content": "Who are you?"}, ] pipe(messages)