
MiniMax-M3
Collection
3 items • Updated • 5
This is an experimental quantization of MiniMax M3 to NVFP4 for use on DGX Spark. (Note: This quantization is not DGX Spark only.)
For DGX Spark Users: Run with sparkrun; part of Spark Arena
https://sparkrun.dev https://spark-arena.com
To run with sparkrun on 4x DGX Spark Nodes:
sparkrun run @experimental/minimax-m3-v0-nvfp4-4x
For RTX Pro 6000 Users (or DGX Spark Users who don't want to use sparkrun): You can run this using the custom sglang container:
docker pull scitrera/dgx-spark-sglang-mm:v0
(Container build is multi-arch so it can be used for x86 and ARM)
Reference settings can be derived from the sparkrun recipe: https://github.com/spark-arena/recipe-registry/blob/main/experimental-recipes/minimax-m3/minimax-m3-v0-nvfp4-4x.yaml
Happy Coding! Let's go!
MiniMax-M3 is a native multimodal model with 1M context. It has ~428B parameters and ~23B activated parameters.
Highlights:

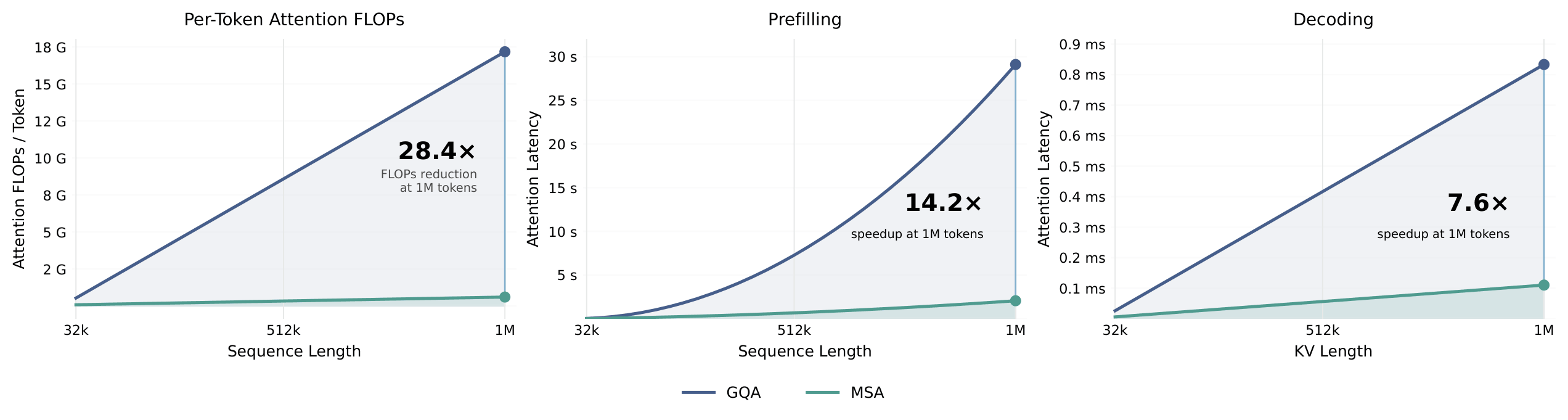
M3 is powered by MiniMax Sparse Attention (MSA), a high-performance sparse attention operator designed for million-token contexts. Compared with GQA, MSA dramatically reduces the attention compute and memory footprint while preserving model quality.
📄 Read the technical report: arXiv:2606.13392 · Hugging Face Papers
M3 supports two reasoning modes:
Download the model:
hf download MiniMaxAI/MiniMax-M3 --local-dir MiniMax-M3
We recommend the following inference frameworks (listed alphabetically) to serve the model:
SGLang - see SGLang cookbook.
vLLM - see vLLM recipes.
Transformers - see Transformers docs.
We recommend the following parameters for best performance: temperature=1.0, top_p=0.95, top_k=40.
Contact us at model@minimax.io.